
The innovation in the AI space is continuing in an incredible speed. This post describes a new technique that has evolved recently which allows smaller fine-tuned models to almost reach the performance of much larger models.
Over the last six months some significant things have changed in the AI industry and community. While at the beginning of this year many people thought that only big companies can afford building and even fine-tuning Large Language Models, new innovative solutions in the open space created by the community have come up. Additionally, some vendors started to keep new versions of their models closed. They were not open sourced anymore and no scientific papers were published anymore.
But in March the Stanford university demonstrated how smaller models can be fine-tuned with the output of larger language models which achieve really good performances. Amazing!
The post We Have No Moat by an anonymous author written in May summarizes the quick evolution well.
Democratization of AI
If smaller models can be fine-tuned to achieve almost the same performance of larger models, many more people and companies can benefit from this technology.
Smaller models require less resources which makes deployments much cheaper. Smaller models can also be fine-tuned faster for specific scenarios. If new techniques like LoRA are applied for the fine-tuning, costs decrease a lot.
It sounds like these savings are the reason why Microsoft built Orca which is much cheaper to operate.
Note: While Democratization sounds good, there are also downsides. Some people use the closed, commercial, large models to train smaller models which is against the interest of the vendors. To prevent this misuse, the licenses and terms of some models explicitly prohibit that their models can be used to train other models.
I think this is fair since these vendors spent a lot of research, time and money on building them. As analogy to development, you could compare this with Code Decompilation.
No One-Size-Fits-All
As Dr. Darío Gil, IBM Senior Vice President and Director of Research, IBM talked about at IBM Think there is no such thing like the one model that solves everything:
Be a value creator, build foundation models on your data and under your control. They will become your most valuable asset. Don’t outsource that and don’t reduce your AI strategy to an API call. One model, I guarantee you, will not rule them all. … Build responsibly, transparently and put governance into the heart of your AI lifecycle.
Companies don’t only need smaller and cheaper models, but also specialized models for their own needs and businesses. In these cases, some fine-tuning needs to be done, either classic fine-tuning or LoRA based fine-tuning. Companies shouldn’t have to start with pretraining large language models, but use good starting points provided by vendors like IBM.
Alpaca
The work from the Stanford university is impressive. I won’t go into the details, but only summarize the key concepts.
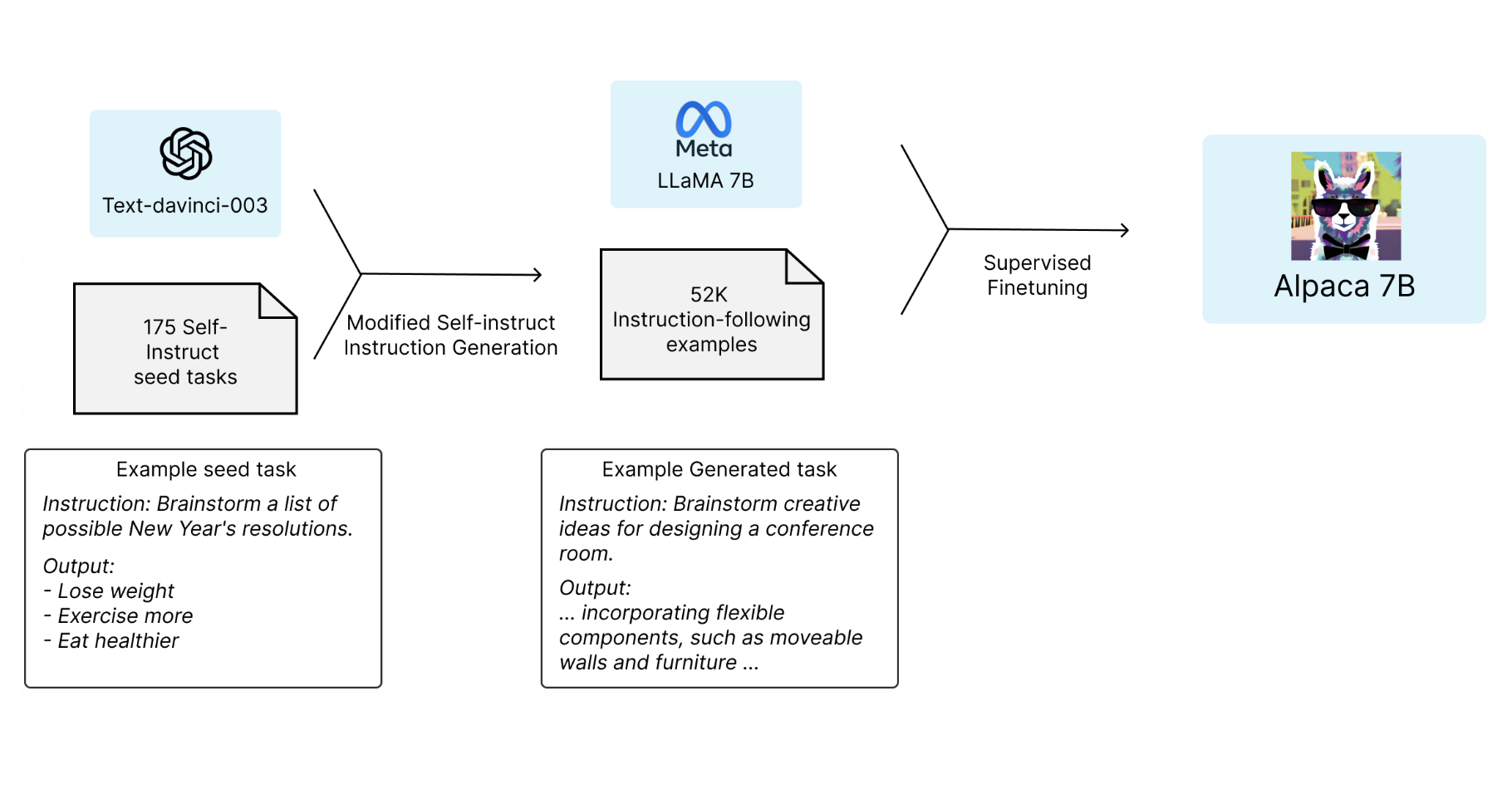
First some students created 175 well written instructions and sample data. These instructions were used on an OpenAI model to generate 52k synthetic instructions. Note: I’m not a lawyer, but as far as I understand this is not allowed commercially.
With the 52k instructions, LLaMA has been fine-tuned to create Alpaca. Again, consult your legal departments if this can be done.
If you want to find out more, check out these resources:
- Alpaca: A Strong, Replicable Instruction-Following Model
- Video: Self-instruct fine-tuning of LLMs
- Video: The ALPACA Code explained: Self-instruct fine-tuning of LLMs
- Alpaca on GitHub
The GitHub repo contains all necessary assets to redo the fine-tuning:
- Prompt
- 175 original instructions
- 52k generated instructions
- Training source code
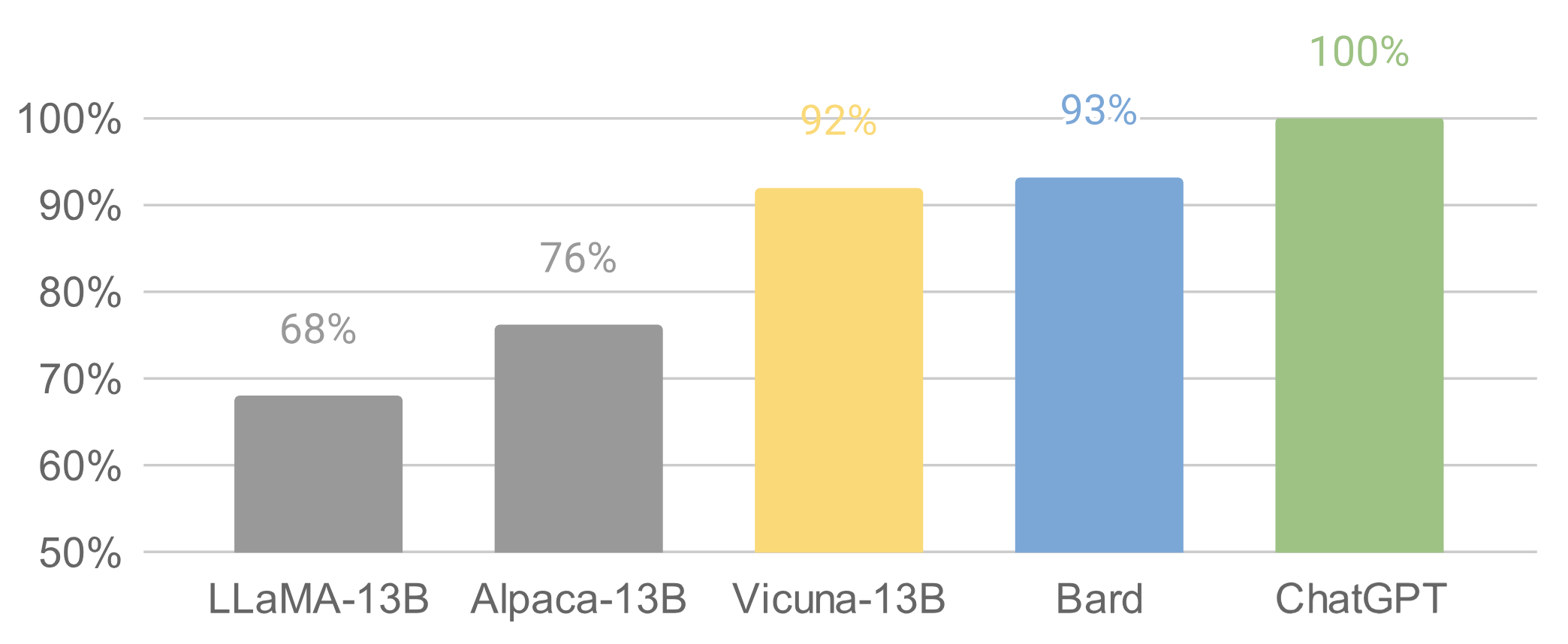
Shortly after Alpaca was published, a cross-university collaboration created Vicuna, an even better version than Alpaca. This one is based on ChatGPT chats that users posted on another site.
Recipe
If you want to learn how to fine-tune your own models, check out my previous posts:
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.