
In large language models embeddings are numerical representations of words, phrases, or sentences that capture their meaning and context. This post describes how to use embeddings to search and rerank documents.
When words or sentences are represented in vectors, several AI tasks can be performed like classification and similarity detection. Even arithmetic operations like “King − Man + Woman = ?” are possible (to some degree).
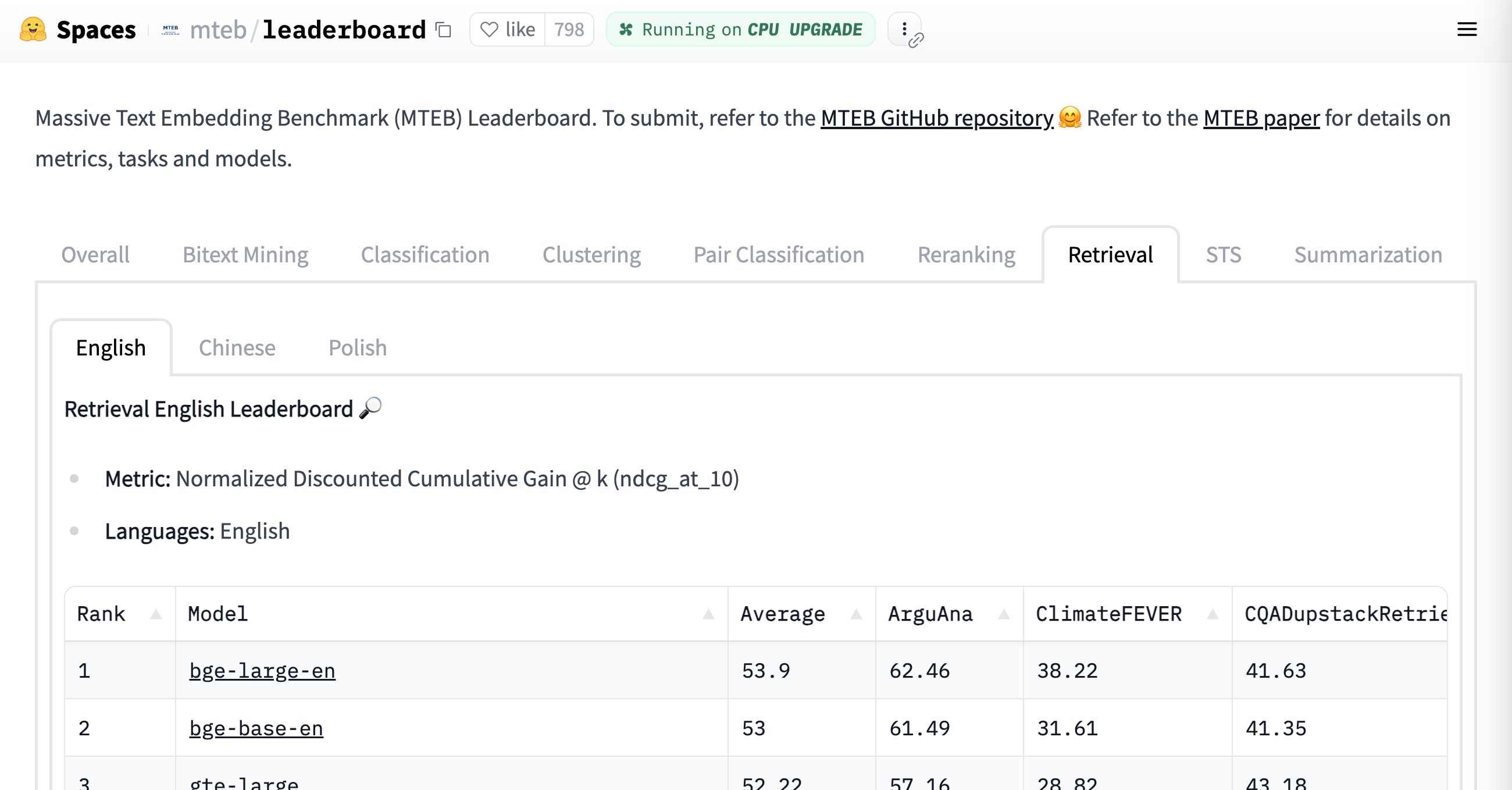
Since Word2vec was introduced, many more efficient embedding models have been created - see the Massive Text Embedding Benchmark (MTEB) Leaderboard.
At this point BAAI/bge-large-en is the leader.
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search. And it also can be used in vector database for LLMs.
Hugging Face API
Hugging Face is often considered as the GitHub for AI since more than 200k models are shared in their catalogue. Additionally Hugging Face provides libraries which make it easy to consume AI, for example Transformers and Pipelines. Another library is Sentence Transformers which is a Python framework for state-of-the-art sentence, text and image embeddings.
Using the sentence transformers library is as easy as this:
1
2
3
4
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
sentence = ['This framework generates embeddings for each input sentence']
embedding = model.encode(sentence)
Example
Let’s look at a simple example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
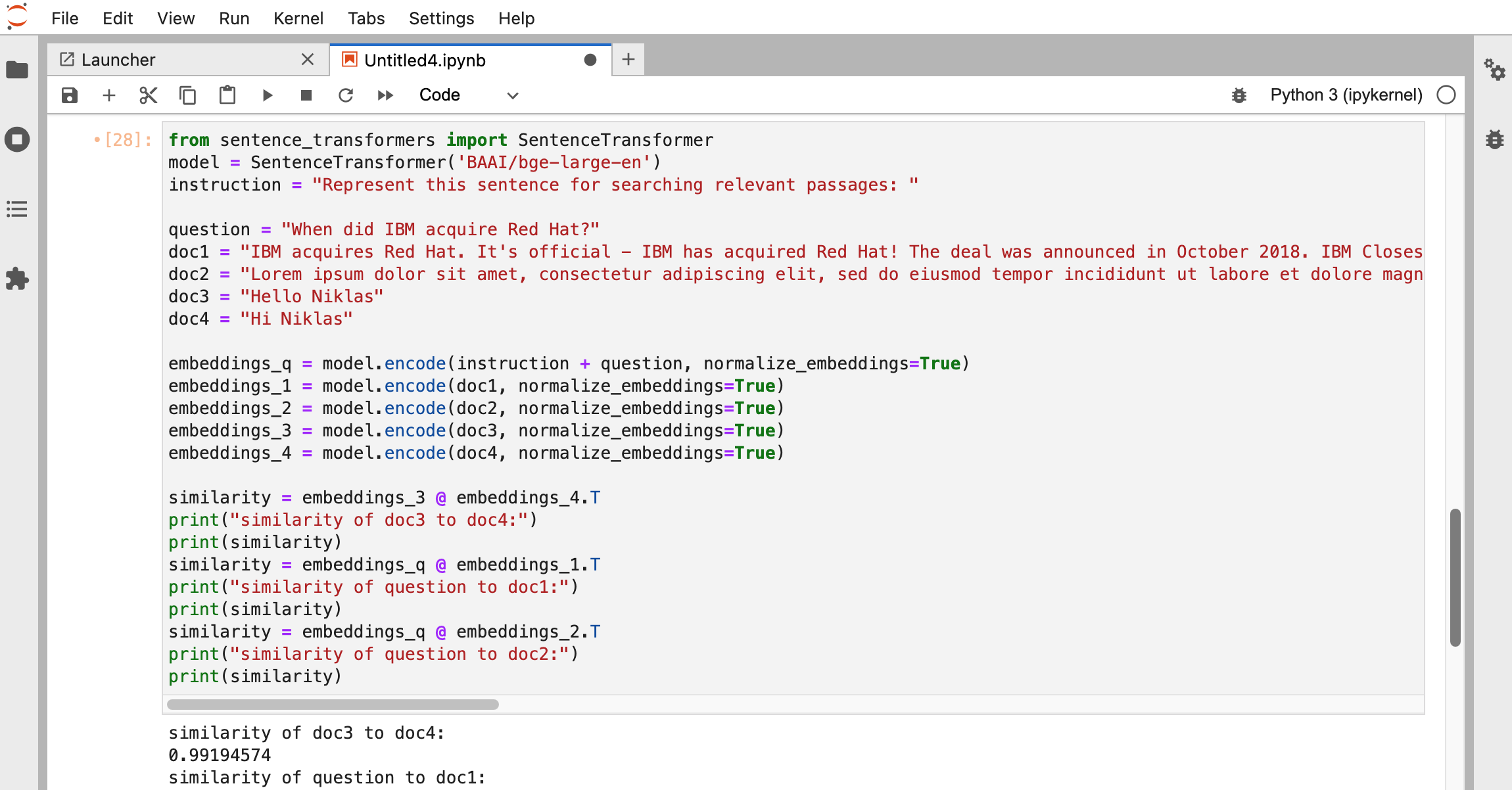
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('BAAI/bge-large-en')
instruction = "Represent this sentence for searching relevant passages: "
question = "When did IBM acquire Red Hat?"
doc1 = "IBM acquires Red Hat. It's official - IBM has acquired Red Hat! The deal was announced in October 2018. IBM Closes Landmark Acquisition of Red Hat."
doc2 = "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
doc3 = "Hello Niklas"
doc4 = "Hi Niklas"
embeddings_q = model.encode(instruction + question, normalize_embeddings=True)
embeddings_1 = model.encode(doc1, normalize_embeddings=True)
embeddings_2 = model.encode(doc2, normalize_embeddings=True)
embeddings_3 = model.encode(doc3, normalize_embeddings=True)
embeddings_4 = model.encode(doc4, normalize_embeddings=True)
similarity = embeddings_3 @ embeddings_4.T
print("similarity of doc3 to doc4:")
print(similarity)
similarity = embeddings_q @ embeddings_1.T
print("similarity of question to doc1:")
print(similarity)
similarity = embeddings_q @ embeddings_2.T
print("similarity of question to doc2:")
print(similarity)
1
2
3
4
5
6
similarity of doc3 to doc4:
0.99194574
similarity of question to doc1:
0.9207834
similarity of question to doc2:
0.6977091
The text ‘Hi Niklas’ and ‘Hello Niklas’ are considered to be almost identical: 0.9919
For the question “When did IBM acquire Red Hat?” doc1 which contains the press release is considered more similar than the lorem ipsum text in doc2.
The key advantage of using embeddings and neural seek rather than keyword matches is that even texts can be found that do not include the same words. For the BAAI/bge-large-en model an instruction “Represent this sentence for searching relevant passages: “ is prepended to the question when comparing much longer documents with the question.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.