
Watsonx.ai is IBM’s offering to train, validate, tune, and deploy generative AI based on foundation models. It comes with several open source models which are briefly described in this post.
As a developer I’m familiar with open source licenses like Apache license v2 and MIT. I also understand that just because developers defined a license for their projects, these projects might not qualify for this license if the licenses of their dependencies don’t match. However, for popular and bigger open-source code projects in general it is relative clear whether they can be used commercially or not.
For Foundation Models it is more challenging to find out whether and how models can be integrated in applications. The main reason is that models are not only code and there might be different licenses and terms for the following assets:
- Model weights (and checkpoints)
- Input data for the pretraining
- Input data for the fine-tuning
- Code for training and inference
Furthermore, even if the assets above are available under good licenses, there might be additional terms and restrictions:
- For research only, for everything except commercial usage, only for companies with less than a certain amount of revenue, etc.
- Not for training other (smaller) models
Open Source Models
Unfortunately lately some of the big players in the market stopped to open source their models and stopped to write public papers about their work. But as some people in the community think, for example this anonymous author, innovation in the open space cannot be stopped.
Here are some tips you should have in mind when finding the right model for you:
- Not all models on Hugging Face are open source.
- Can the model be used commercially?
- Which languages does the model support?
- Different versions of a model (small vs big; plain vs instruct; etc.) can have different terms.
- Can the model efficiently be fine-tuned via LoRA?
- Has the model been tuned to prevent hate, abuse, profanity, etc.?
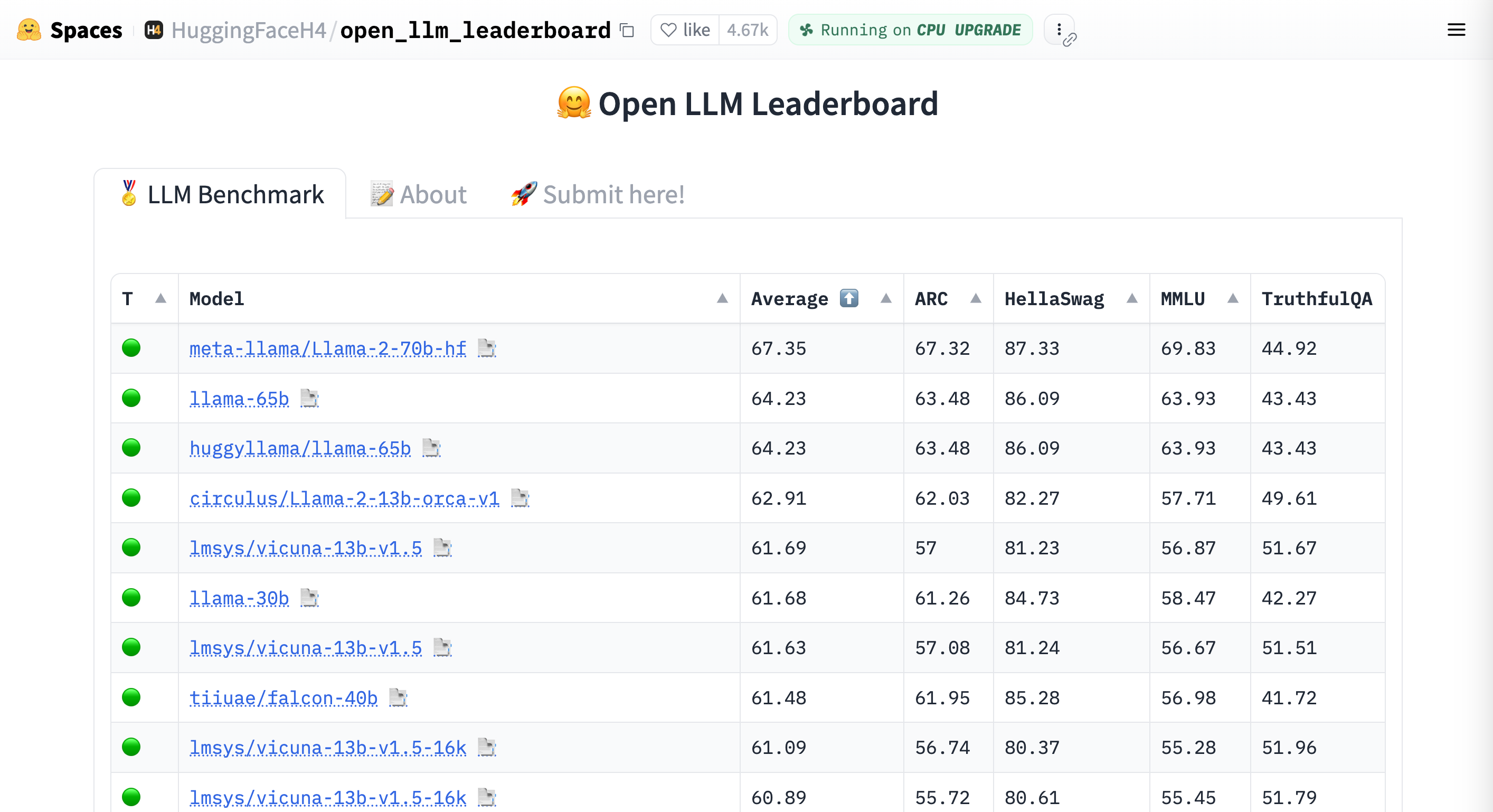
There are various leaderboards which can help. But since there is no one size fits all model, make sure you don’t compare apples with oranges.
- Open LLM Leaderboard
- Standford Helm
- Databricks: Best-in-class open source generative AI models for free commercial use
- LMsys leaderboard
FLAN-T5
The FLAN-T5 and UL2 models have been open sourced by Google at the end of 2022 and in 2023 and can be used commercially (as far as I know). The FLAN versions have been fine-tuned for multiple AI tasks and perform usually better than the non-FLAN versions. Additionally, the models can be fine-tuned via LoRA which makes the fine-tuning very fast and relative cheap. Furthermore, many different languages are supported.
- google/flan-t5-xl 3b
- google/flan-t5-xxl 11b
- google/flan-ul2 20b
- google/ul2 20b
- prakharz/dial-flant5-xl 3b
The UL2 models have the training objective to allow the model to see bidirectional context of the prompt. The dial-flant5-xl model has been fine-tuned especially for dialogs.
In the Tuning Studio of Watsonx.ai LoRA training can be executed simply by providing small datasets with labels. At this point google/flan-t5-xl 3b is supported.
Falcon
Falcon 40b is the UAE’s and the Middle East’s first home-grown, open-source large language model (LLM) with 40 billion parameters trained on one trillion tokens. According to benchmarks it is one of the leading models right now.
The 40b version is not only available in English but in more languages. Additionally, there are smaller and instruct fine-tuned versions.
A very interesting use case is that Falcon can be leveraged to create synthetic data which can be fed into the fine-tuning for smaller specialized models. Read my post Generating synthetic Data with Large Language Models.
LLaMA
LLaMA 2 from Meta/Facebook is another very powerful model. Some people refer to it as an open source model. While I am not a lawyer and cannot give legal advice, I would not categorize this under open source.
There are two reasons why I list LLaMA here anyway. Earlier this month IBM announced an extended partnership with Meta IBM Plans to Make Llama 2 Available within its Watsonx AI and Data Platform. Furthermore the Standford university demonstrated how LLaMA 2 can be fine-tuned with synthetic data.
In addition to the 70b version, there is a smaller 13b version and there are instruct fine-tuned versions for chat. As far as I understand one of the key reasons why LLaMA 2 is so good is that it has been trained on 2t tokens which is why it can compete even with models with many more parameters.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.