
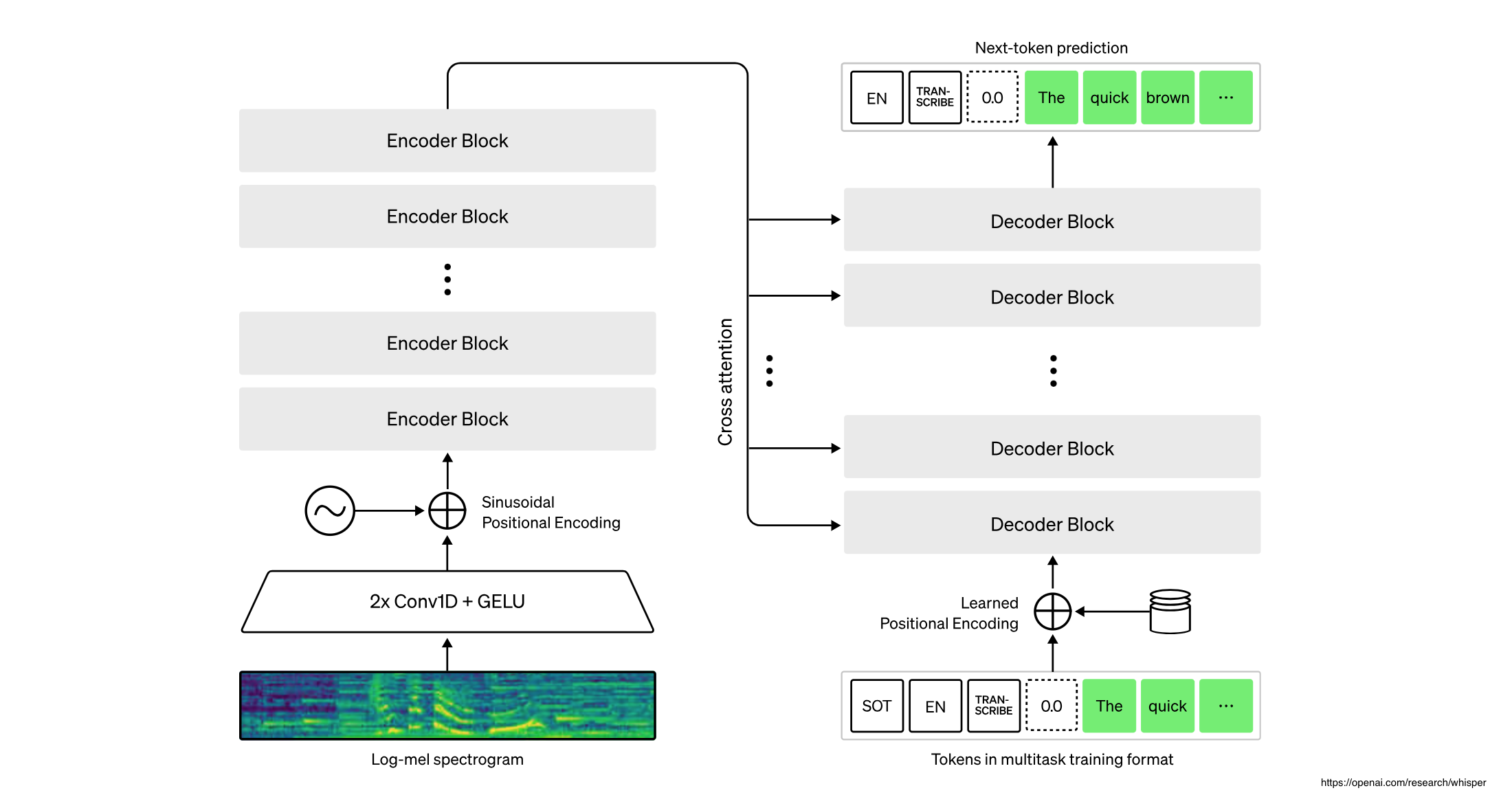
The Hugging Face libraries have become the de-facto standard how to access foundation models from Python, both for inference and fine-tuning. This post describes how to use the Hugging Face APIs for different types of Large Language Models.
As part of the Transformers library Hugging Face provides Auto Classes which works well when accessing popular models. For other models and when training models it’s important to understand the different types of architectures:
- Causal Language Modeling (CLM) - decoder
- Masked Language Modeling (MLM) - encoder
- Sequence-to-Sequence (Seq2Seq) - encoder and decoder
Below is a quick summary of the great blog Understanding Causal LLM’s, Masked LLM’s, and Seq2Seq: A Guide to Language Model Training Approaches.
Causal Language Modeling
Causal Language Modeling is typically used in decoder-based architectures, for example GPT, to generate text and for summarization. Causal Language Modeling is an autoregressive method where the model is trained to predict the next token in a sequence given the previous tokens.
Hugging Face API: transformers.AutoModelForCausalLM
1
2
3
4
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id="gpt2"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
Masked Language Modeling
Masked Language Modeling is typically used in encoder-based architectures, for example BERT, to predict masked content as needed for text classification, sentiment analysis, and named entity recognition.
Hugging Face API: transformers.AutoModelForMaskGeneration
1
2
3
4
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id="bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
Sequence-to-Sequence
Sequence-to-Sequence is typically used in encoder-decoder-based architectures, for example FLAN-T5, to do translations, question answering and speech to text. Check out the Hugging Face documentation for details.
Hugging Face API: transformers.AutoModelForSeq2SeqLM
1
2
3
4
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_id="google/flan-t5-small"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)
Next Steps
The three architectures have pros and cons as explained in the referenced blog.
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.