
With watsonx.ai, you can train, validate, tune, and deploy generative AI based on foundation models. This post explains some of the strategies to instruct Large Language Models how to generate text, either via APIs or via the watsonx.ai Prompt Lab (‘playground’).
There is a great blog How to generate text: using different decoding methods for language generation with Transformers on Hugging Face describing the different decoding methods. These methods define which words (more precisely tokens) to return next.
Let’s look at the main differences between these three methods:
- Greedy
- Beam
- Sampling
Greedy
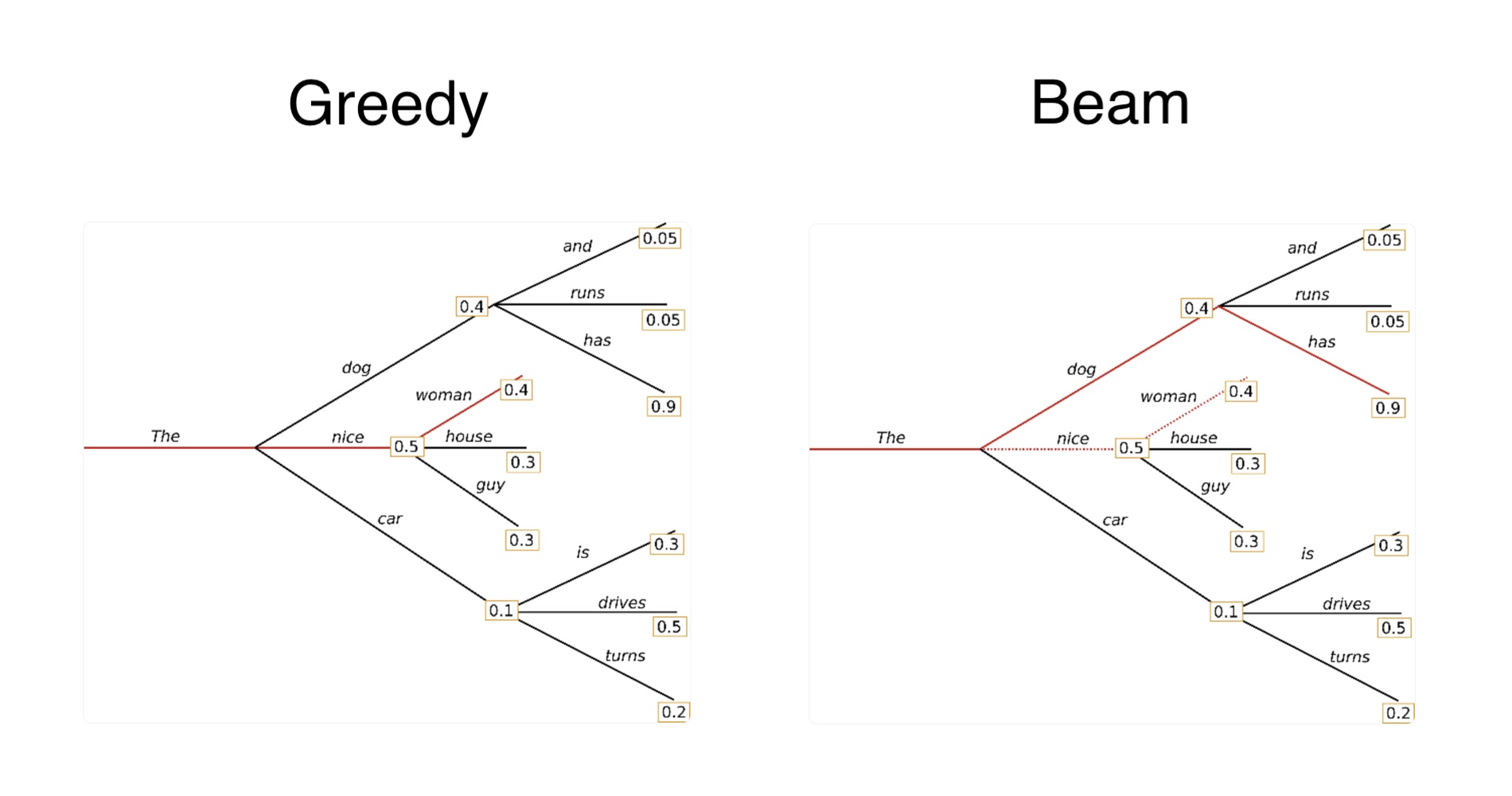
Greedy basically means to return the word/token which has the highest probability of all possible words in the model’s dictionary. In the graphic at the top of this post after the first word ‘The’ the next word that is chosen is ‘nice’ since it has the highest probability.
The disadvantage of greedy search is that it misses high probability words hidden behind low probability words. For example, the model will not return ‘The dog has’ even though ‘has’ has a high probability and ‘dog’ only a little less than ‘nice’.
Beam
Beam addresses this issue by not only looking at the probabilities of the next word, but the next possible chains of words. In the example it detects that ‘The dog has’ has a high probability than ‘The nice woman’. The number of beams defines how far the model should look into the potential futures/next word combinations.
Both Greedy and Beam can lead to repetitions. n-grams (a.k.a word sequences of n words) penalties can be used to address this issue. For example, an n-gram of two means that the same two words must not appear twice.
The disadvantage of beam search and n-grams is that that certain might not be desired. For example, when using two g-grams the word ‘New York’ would never appear twice in a generated text about New York.
Sampling
Sampling adds some randomness. This is especially useful if you want to generate stories or some other text in creative scenarios.
However, when too much randomness is applied, the generated text is not fluent. To overcome this issue, it can be defined how to find next words. With Top-K the next word is chosen from the k most likely words. With Top-P the next word needs to be one of the p% most likely ones.
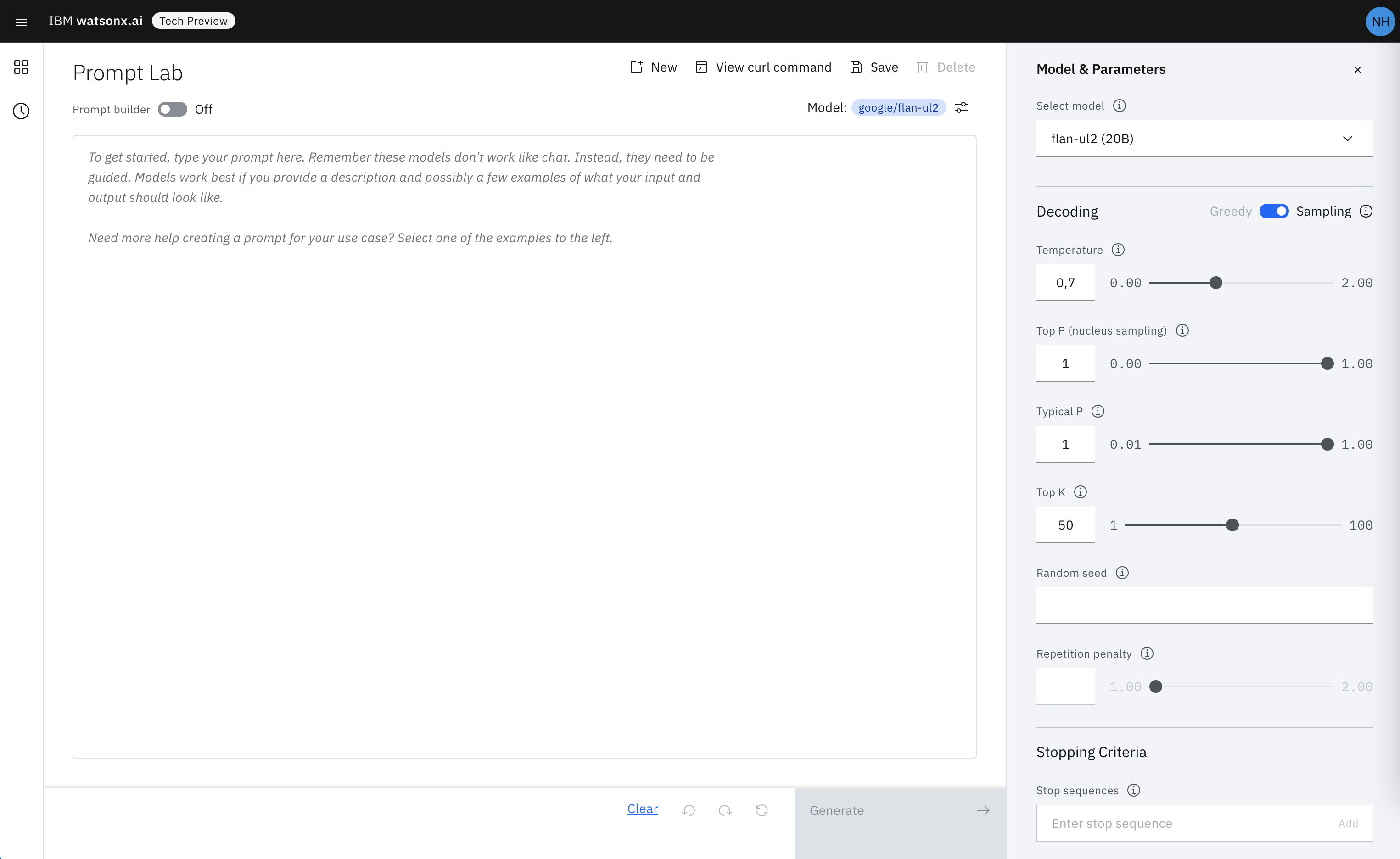
Watsonx.ai API
Watsonx.ai provides APIs to utilize these settings.
- decoding_method: Represents the strategy used for picking the tokens during generation of the output text. Options are greedy and sample
- beam_width: Multiple output sequences of tokens are generated, using your decoding selection, and then the output sequence with the highest overall probability is returned.
- temperature: To modify the next-token probabilities in sampling mode.
- top_k: The number of highest probability vocabulary tokens to keep for top-k-filtering.
- top_p: Similar to top_k except the candidates to generate the next token are the most likely tokens with probabilities that add up to at least top_p.
These settings can also be defined in the Watsonx.ai user interface.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.