

At IBM Think 2023 several exciting new Foundation Model capabilities have been announced. Below are some of my highlights.
Most of the content below is from the great talk from Dr. Darío Gil, IBM Senior Vice President and Director of Research, IBM. Watch the whole recording!
Watsonx is a new platform for foundation models and generative AI, offering a studio, data store, and governance toolkit. Let’s take a look what this platform intends to provide.
Data Pile
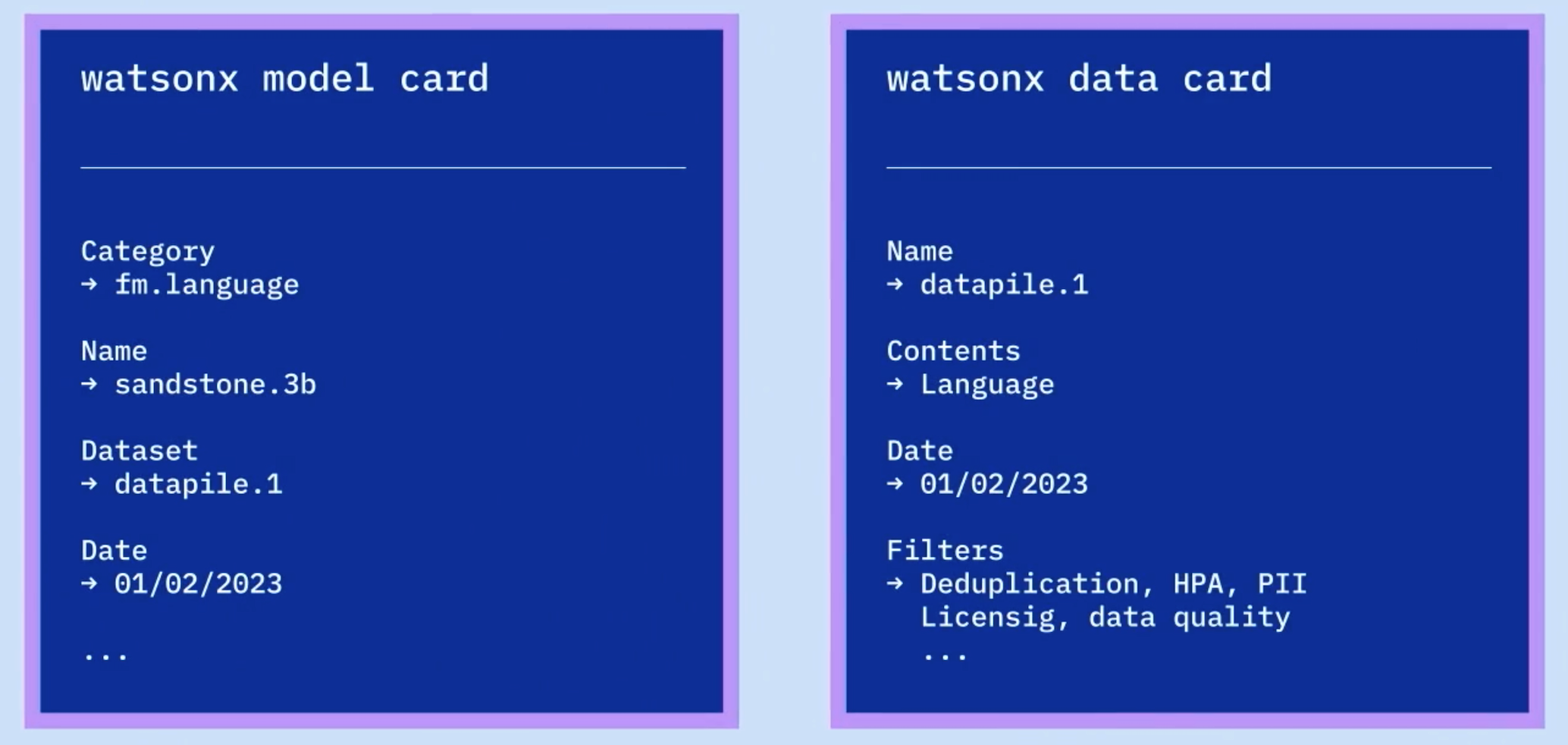
To build good AI models and applications, you need good data. IBM has planned to provide a pile of data from various sources which filters hate, abuse, profanity, private information and licenced information. IBM clients can also bring their own data. When models are trained, the information which data was used to train the models and how to remove it again (opt out/regular cadence), if necessary, is managed via ‘data cards’.
In addition to tracking the data, model metadata is tracked as well as part of the governance functionality in Watsonx.
IBM Models
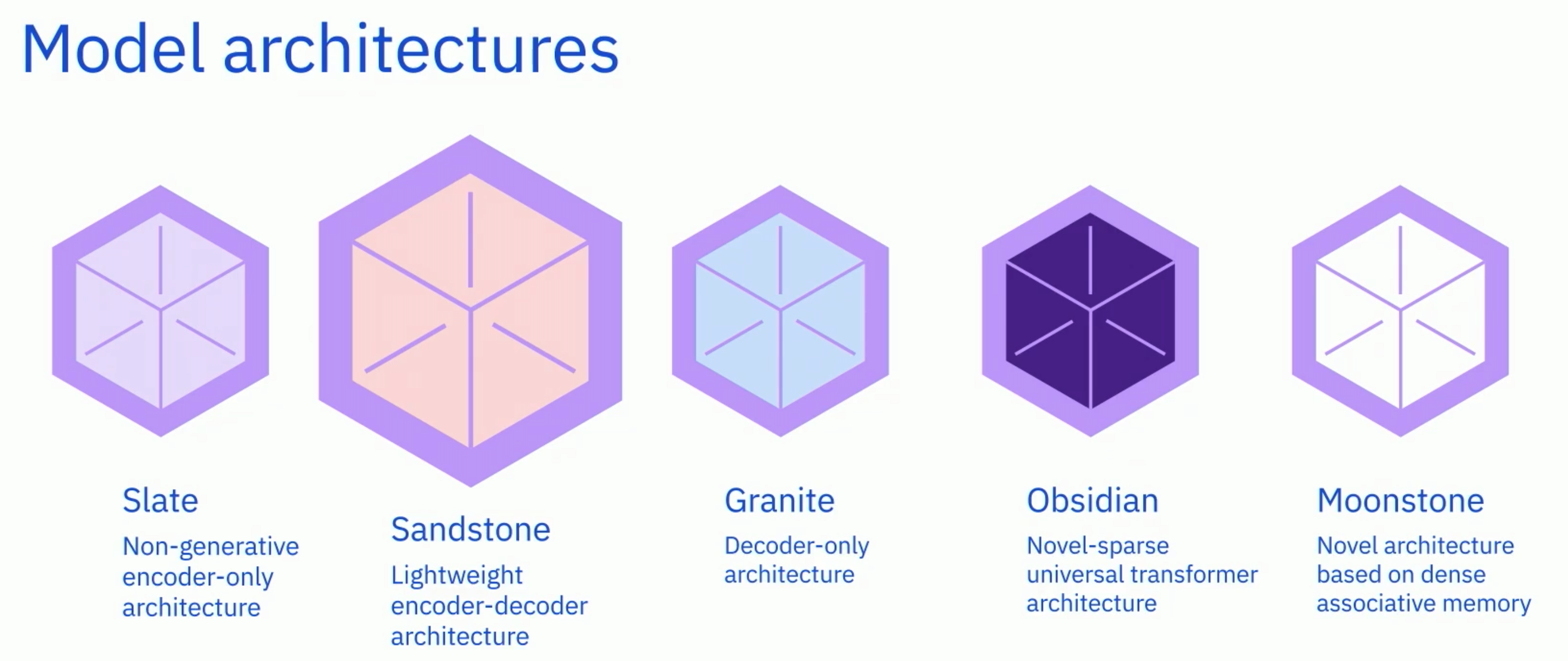
IBM has planned to offer a suite of foundation models, for example smaller encoder based models, but also encoder-decoder or just decoder based models.
Recognizing that one size doesn’t fit all, we’re building a family of language and code foundation models of different sizes and architectures. Each model family has a geology-themed code name —Granite, Sandstone, Obsidian, and Slate — which brings together cutting-edge innovations from IBM Research and the open research community. Each model can be customized for a range of enterprise tasks.
While Foundation Models are in general good in performing multiple tasks, they have been trained with generic data. To optimize them, fine tuning with domain specific or proprietary data can be done.
Foundation Models as a Service
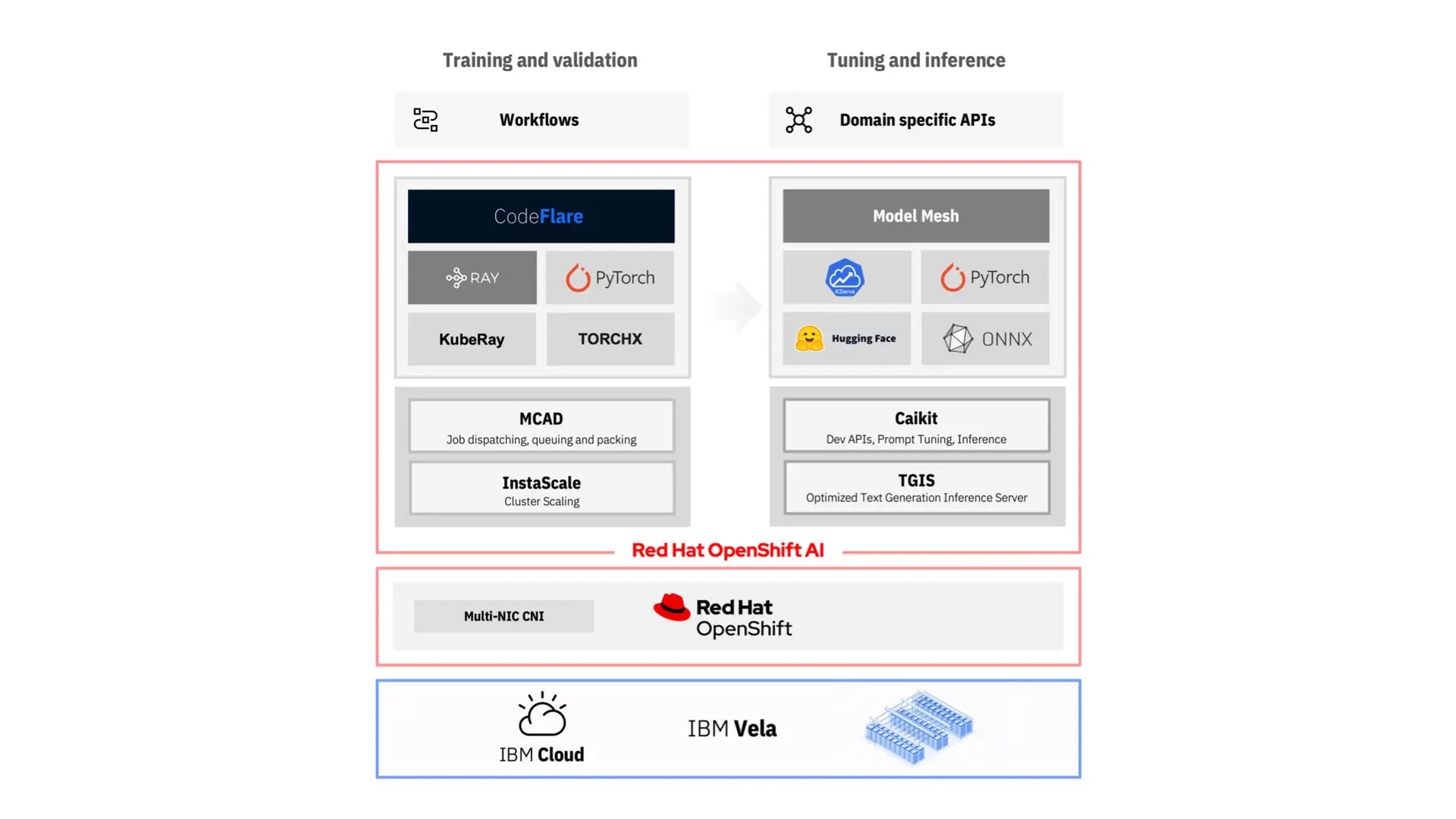
As explained by Dario, IBM plans to provide the capabilities of IBM’s first AI-optimized, cloud-native supercomputer Vela as a Service.
The stack utilizes Red Hat OpenShift, so that it could also be run on multiple clouds or on-premises. It is based on popular open source frameworks and communities like PyTorch, Ray and Hugging Face.
Watsonx.ai Studio
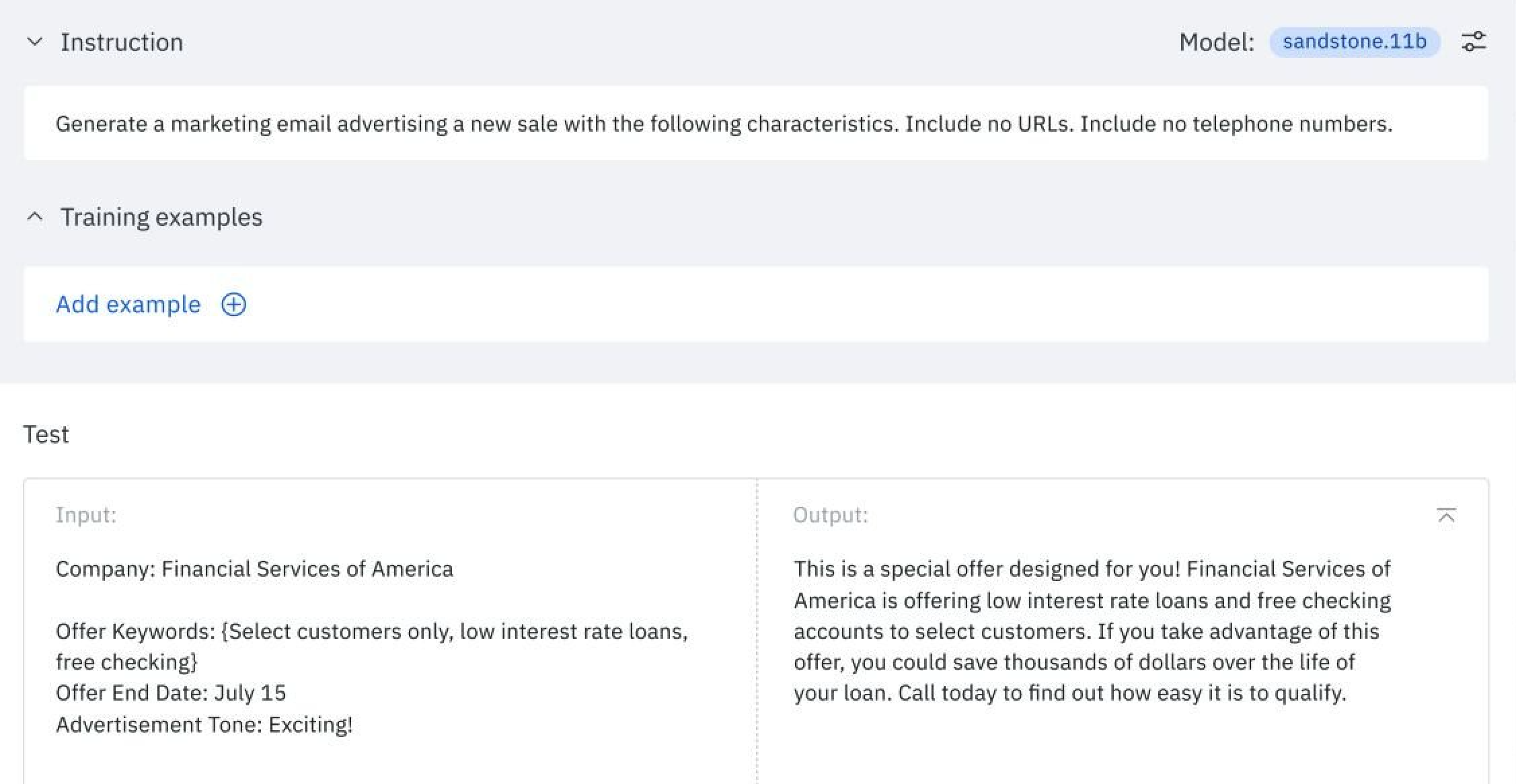
Another nice feature is Watsonx.ai Studio with the new playground including easy to use Prompt Tuning.
watsonx.ai is an AI studio that combines the capabilities of IBM Watson Studio with the latest generative AI capabilities that leverage the power of foundation models. It provides access to high-quality, pre-trained, and proprietary IBM foundation models built with a rigorous focus on data acquisition, provenance, and quality. watsonx.ai is user-friendly. It’s not just for data scientists & developers, but also for business users. It provides a simple, natural language interface for different tasks.
IBM Watson Code Assistant
IBM also demonstrated a preview of IBM Watson Code Assistant to increase developer productivity, especially for Ansible, Java and Cobol.
Intended to be generally available later this year, Watson Code Assistant is designed to reduce the complexity of coding through AI-generated content recommendations. Additionally, organizations will be able to tune the underlying foundation model and customize it with their own standards and best practices, while data-source attribution will provide transparency into the potential origins of the generated code.
Community
IBM is working closely with key communities on AI related projects, for example Hugging Face, PyTorch and OpenShift.
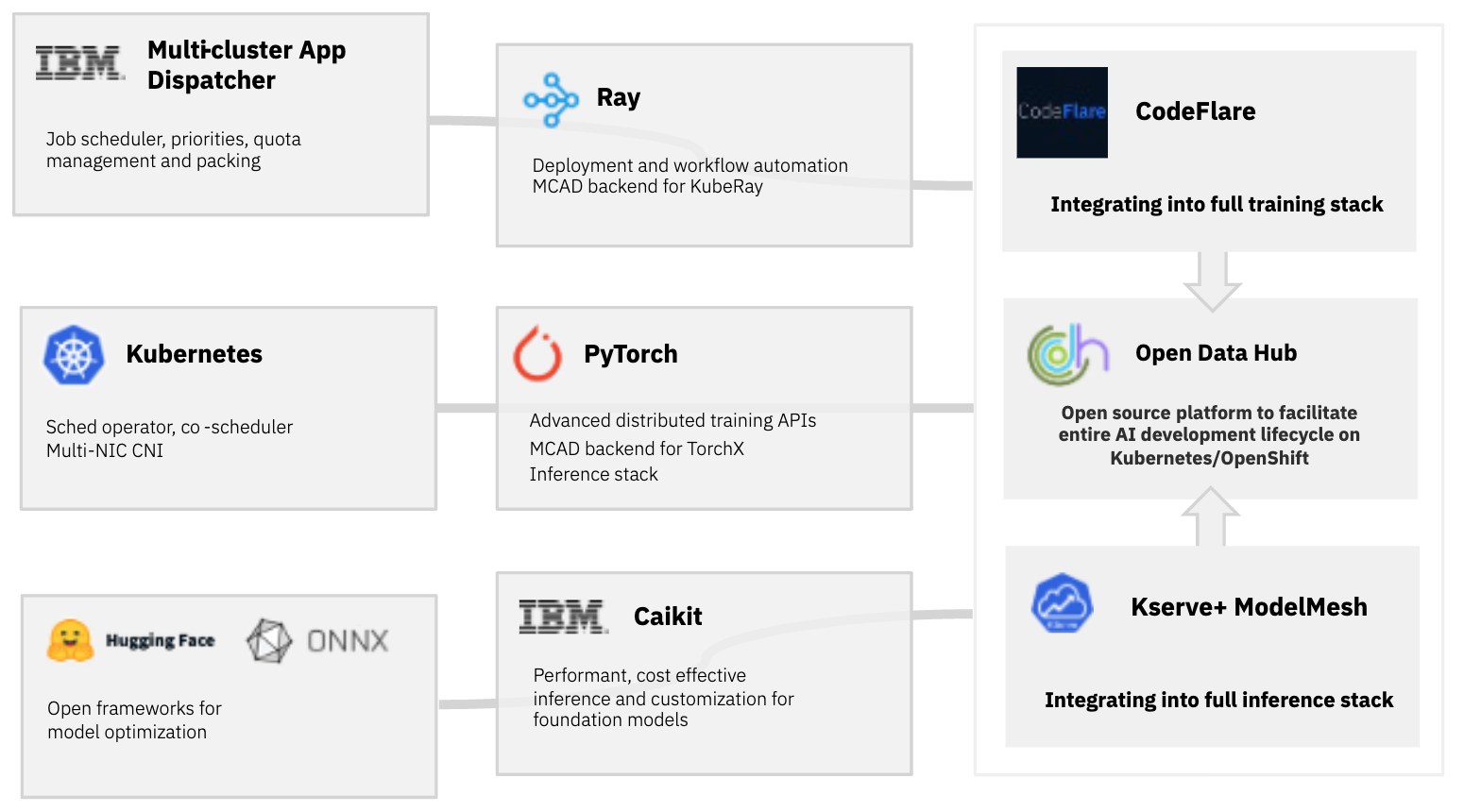
In addition to consuming open source software in IBM offerings, IBM also contributes to existing projects and contributes new projects like Caikit
Inference servers available today for running AI models require significant AI-specific knowledge on the part of the user. The input to the model is a tensor, and the output to the model is a tensor. … We have created an abstraction layer, called Caikit, that provides intuitive APIs and data models for application developers, and provides a stable interface that allows the model and application to evolve independently. This abstraction is used in IBM’s Watson model serving infrastructure and will soon be contributed to open-source.
Next Steps
Dario ends his talk with a great summary:
Be a value creator, build foundation models on your data and under your control. They will become your most valuable asset. Don’t outsource that and don’t reduce your AI strategy to an API call. One model, I guarantee you, will not rule them all. … Build responsibly, transparently and put governance into the heart of your AI lifecycle.
Check out these resources to learn more:
- Introducing watsonx: The future of AI for business
- Building a foundation for the future of AI models
- A cloud-native, open-source stack for accelerating foundation model innovation
- How IBM is tailoring generative AI for enterprises
- Reshaping IT automation with IBM Watson Code Assistant
- Caikit
- Tweets from @armand_ruiz