
To find the best possible models and parameters for Question Answering via Generative AI, a lot of experiments need to be run. While some techniques have been proven successful, other approaches need to be tried out. Some findings can even be discovered coincidentally via trial and error. This post describes how experiments can be run automatically.
Overview
The article Optimizing Generative AI for Question Answering explains how to meassure performance via Ground Truth documents. This is the prerequisite to compare different models, flows and parameters.
For efficiency reasons the process needs to be fully automated. The exact definitions of the experiments as well as the results need to be tracked, for example in Git, and they need to be in a format that they can easily be compared.
When building systems that generate answers to questions of users, you do not just pass the questions to generic Large Language Models. Instead, the models need to understand the context of the questions. Before the models are asked to generate answers, pre-processing needs to be done to describe the context efficiently. For example, full text searches and re-ranking can be used to identify most relevant passages of documents which are passed to the answer generating models.
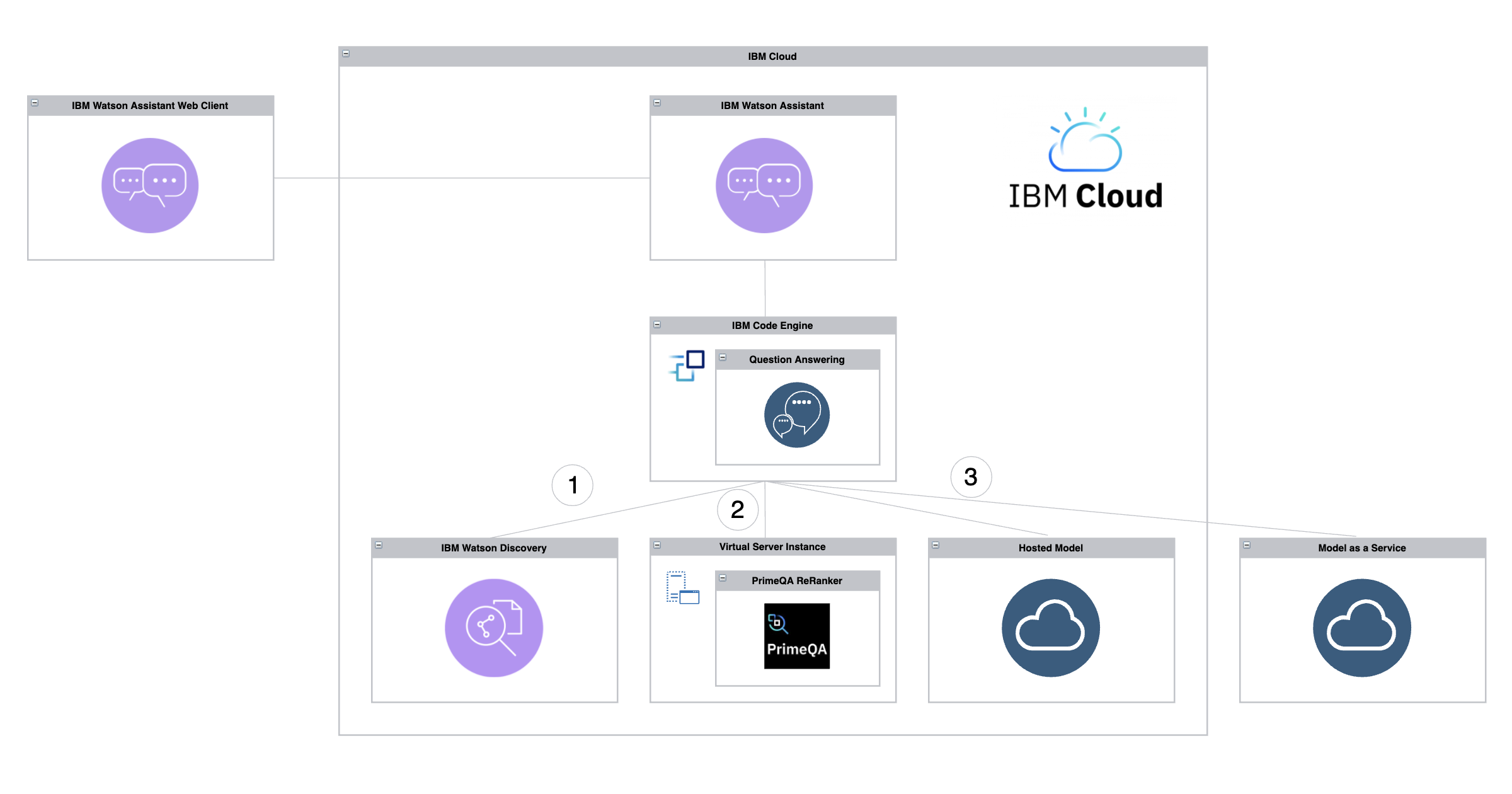
Often three stages are used to generate answers. The diagram at the top of this post shows how the Question Answering service orchestrates these flows.
- Full text searches via Watson Discovery
- Reranking via PrimeQA ReRankers
- Answer generation via Large Language Models hosted and/or managed on clouds
Architecture
The code of the mechanism explained in this post is available as open source in the question-answering repo.
To get started as easily as possible, containers are provided. Additionally, Watson Discovery and the PrimeQA ReRanker need to be provisioned and configured.
The microservice, the experiment runner and a mock MaaS (model as a service) service can be run locally via Docker including Docker Compose. Furthermore a sample dataset is provided as well as a sample Ground Truth document.
While for demo purposes the MaaS mock service can be run, for real question answering services and experiments Large Language Models are used to generate answers. Since these models are typically big, it makes sense to utilize a Model as a Service offering. If your MaaS provider uses another interface, you need extend the MaaS mock service to become a proxy.
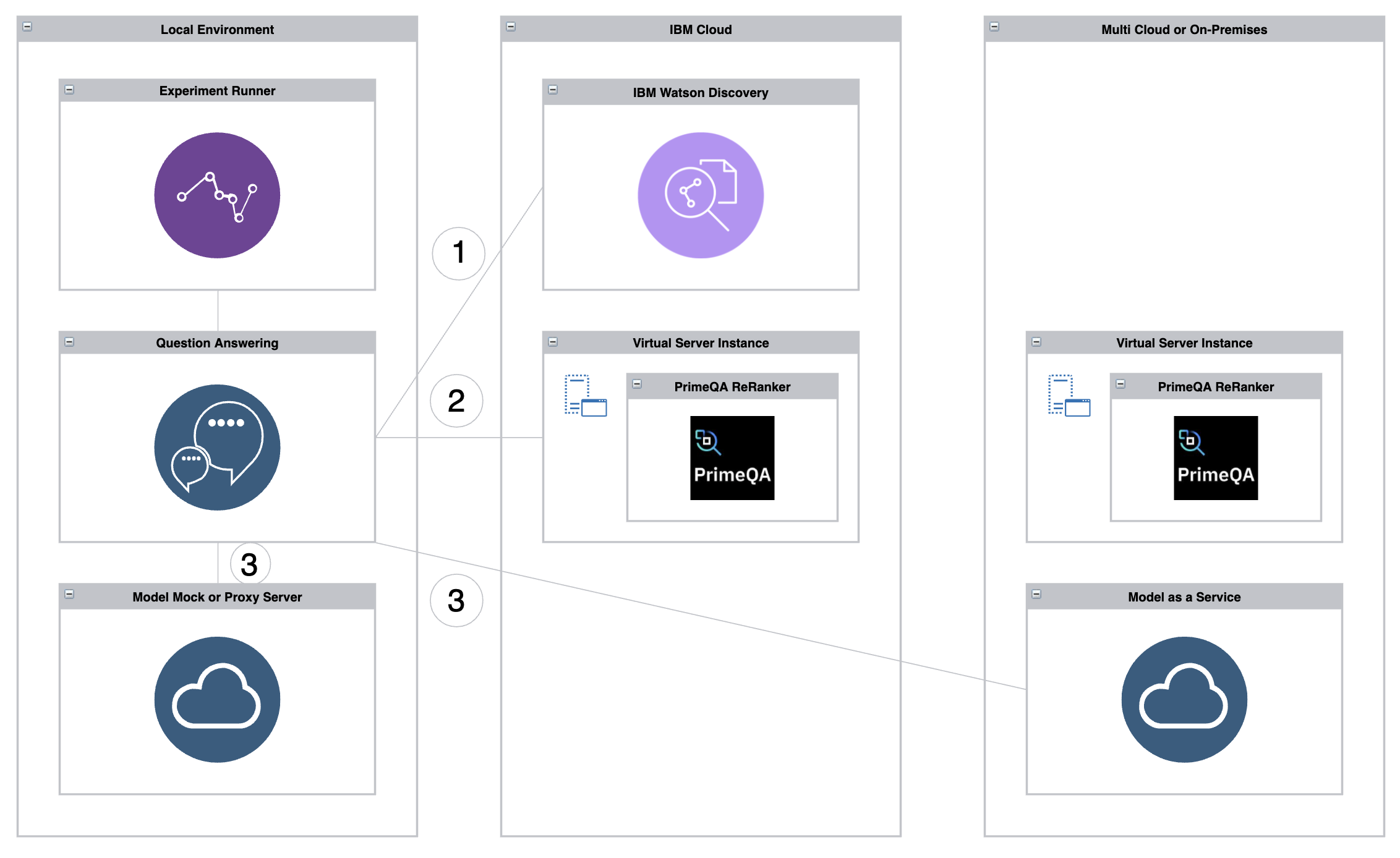
There are several ways to run the code. The next section covers only the first container alternative.
- All three containers via Docker Compose
- Only the Question Answering service as container
- As local Java and Python applications
Setup
There are five steps to set up everything:
- Clone the repo
- Provision Watson Discovery and upload data
- Set up the PrimeQA ReRanker in a VM
- Configure the experiment
- Start the local containers and the experiment
Read the documentation for details.
Experiments can choose different parameters, for example:
- EXPERIMENT_DISCOVERY_MAX_OUTPUT_DOCUMENTS=30
- EXPERIMENT_DISCOVERY_CHARACTERS=1000
- EXPERIMENT_DISCOVERY_FIND_ANSWERS=false
- EXPERIMENT_RERANKER_MODEL=”/store/checkpoints/drdecr/DrDecr.dnn”
- EXPERIMENT_RERANKER_ID=ColBERTReranker
- EXPERIMENT_RERANKER_MAX_INPUT_DOCUMENTS=20
- EXPERIMENT_LLM_NAME=google/flan-t5-xxl
- EXPERIMENT_LLM_PROMPT=”Document: CONTEXT\n\nQuestion: QUESTION\nAnswer the question using the above document. Answer: “
- EXPERIMENT_LLM_MIN_NEW_TOKENS=1
- EXPERIMENT_LLM_MAX_NEW_TOKENS=300
- EXPERIMENT_LLM_MAX_INPUT_DOCUMENTS=3
Running Experiments
Running experiments is really easy. All you need to do is to run the following commands in two terminals. This triggers the Experiment Runner which invokes all queries defined in the Ground Truth document on the Question Answering service.
1
2
cd scripts
sh start-containers.sh
1
2
docker exec -it experimentrunner sh
sh start.sh
The screenshot displays the two terminals. In the left terminal the logs of the three containers are listed, in the right terminal the output of the experiment runner code.
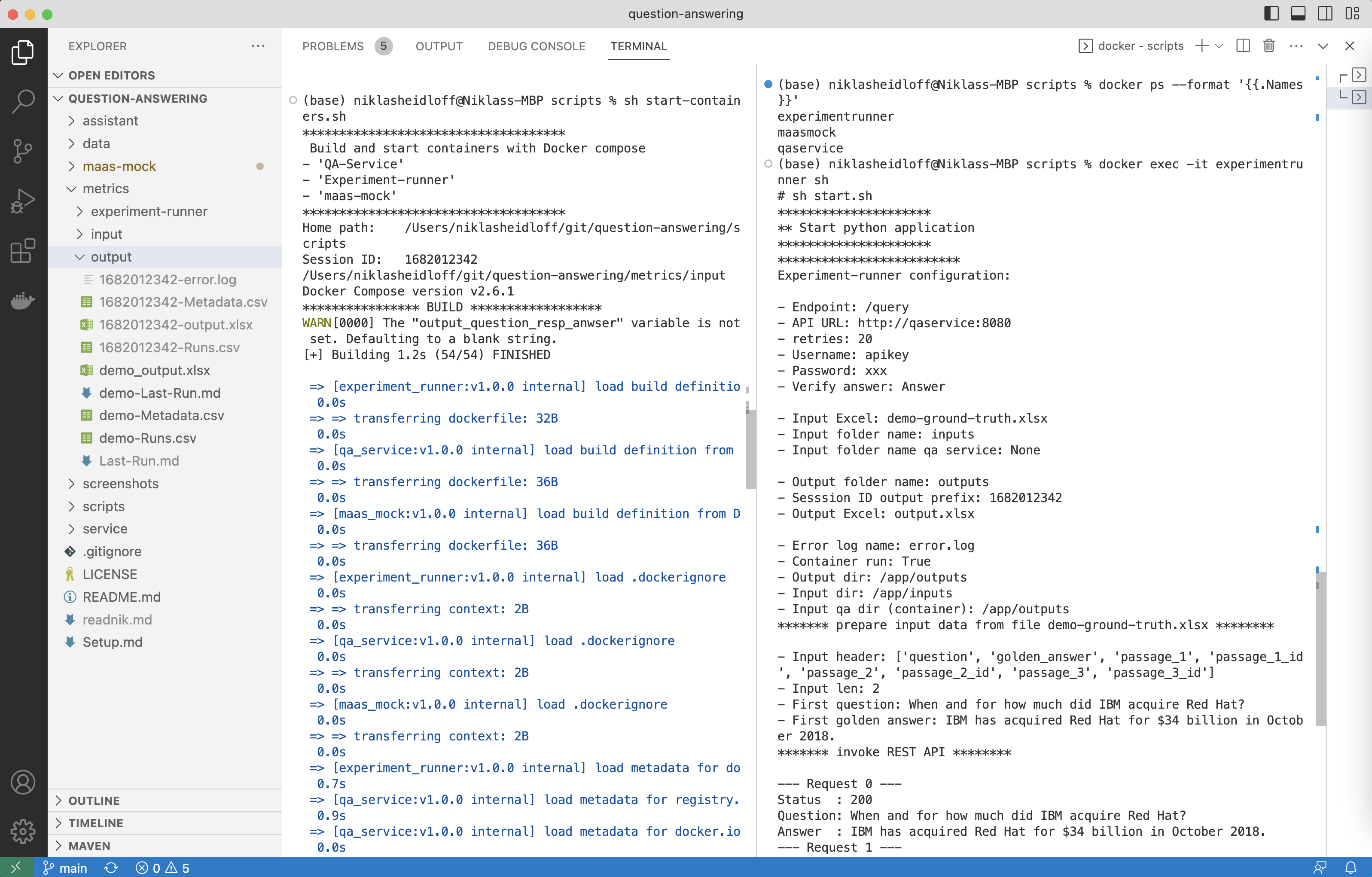
As output of experiments, the following files are created which contain now only the final results and performance indicators like Bleu and Rouge, but also intermediate steps.
Resources
Check out these resources to learn more about Question Answering and Generative AI:
- Question Answering Repo
- Optimizing Generative AI for Question Answering
- Generative AI for Question Answering Scenarios
- Introduction to Neural Information Retrieval
- Foundation Models, Transformers, BERT and GPT
- Generative AI Sample Code for Question Answering
- Integrating generative AI in Watson Assistant
- Finding concise answers to questions in enterprise documents
- Using PrimeQA For NLP Question Answering