
Transformer based AI models can generate amazing answers to users’ questions. While the underlaying Large Language Models are not retrained, the performance of Question Answering AI can be improved by running experiments with different hyper parameters.
Overview
This post describes how to optimize generated AI answers. When building systems that generate answers to questions of users, you do not just pass the questions to generic Large Language Models. Instead, the models need to understand the context of the questions. Before the models are asked to generate answers, pre-processing needs to be done to describe the context efficiently. For example, full text searches and re-ranking can be used to identify most relevant passages of documents which are passed to the answer generating models.
Re-ranking utilizes neural information retrieval techniques to find answers to queries without comparing single word occurrences. Instead, representations of words are used to find the closest neighbors in the neural networks. So often two large language models are leveraged:
- Re-ranker which is typically an encoder-based transformer
- Answer generator which is typically a decoder-based transformer
Often three stages are run in pipelines to produce answers:
- Full text searches
- Re-ranking
- Answer generation
In the context of ‘Question Answering’ tasks it is important to provide answers that are correct to avoid hallucination which is why the ‘temperature’ parameter is set to ‘0’. Other parameters should be optimized for specific use cases and specific data corpora, for example the choice of large language models and the size of documents which are passed between the different stages.
Read my previous posts for more context.
Ground Truth
To measure the performance of different models and parameters, ground truth based approaches can be leveraged. Experts for specific domains and data provide at least 100 questions and expected answers, called ‘gold answers’.
Since the answer generation pipelines contain multiple steps, not only the final answers should be measured but also the previous steps like the re-ranking.
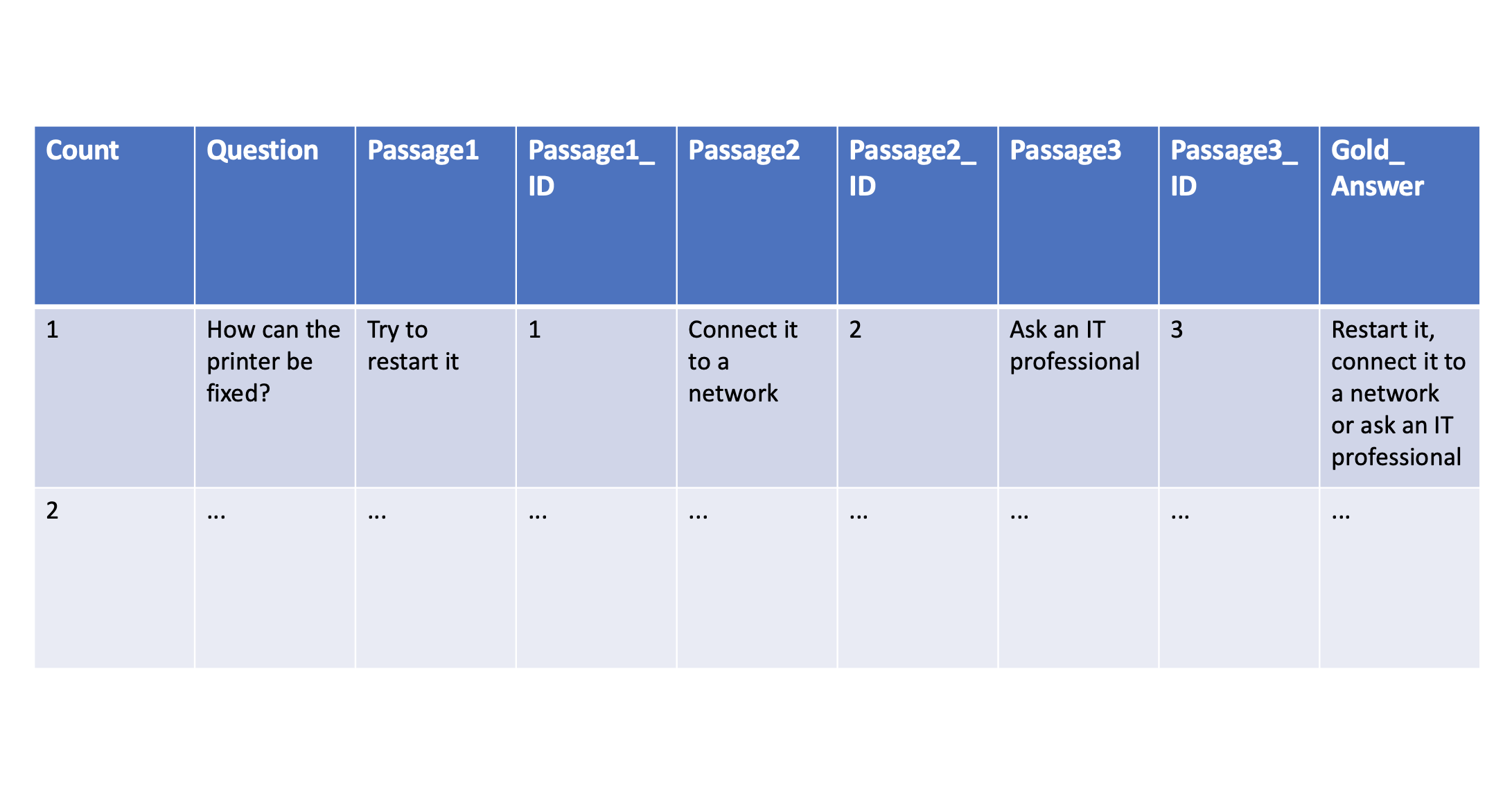
The following sample (or the table at the top of this post) shows all the information that needs to be defined in the ground truth file. In addition to questions and answers the key passages are defined as well that include information necessary to generate the answers. Note that good answers often require information from more than one passage.
| Count | Question | Passage1 | Passage1_ID | Passage2 | Passage2_ID | Passage3 | Passage3_ID | Gold_Answer |
|---|---|---|---|---|---|---|---|---|
| 1 | How can the printer be fixed? | Try to restart it | 1 | Connect it to a network | 2 | Ask an IT professional | 3 | Restart it, connect it to a network or ask an IT professional |
| 2 | … | … | … | … | … | … | … | … |
Evaluations
To evaluate different combinations of parameters, the quality of the final answers as well as the found passages need to be checked.
| Experiment | Recall@1 | Recall@2 | Recall@3 | ROUGE-L | BLEU |
|---|---|---|---|---|---|
| 1 | 0.462 | 0.581 | 0.640 | 0.3288 | 20.2427 |
| 2 | … | … | … | … | … |
The final answers can be measured with Bleu and Rouge.
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another.
The same mechanism can be applied to compare gold answers with actual answers in the same language. In the simplest case n-gram comparisons can be done for words that are next to each other.
To compare experiments, the relative Bleu and Rouge values can be used. Note: Don’t expect them to be 100 or 1 in this scenario.
While these mechanisms give some indications of the performance, you should also do manual due diligence, since final subjective measurements are important.
In the question-answering repo we automatically generate spreadsheets that can easily be read by humans.
| Question | Answer | Gold Answer |
|---|---|---|
| How can the printer be fixed? | Try to restart it and connect it. | Restart it, connect it to a network or ask an IT professional |
| … | … | … |
For passages matches and recalls can be calculated. The goal is to check how many of the right passages have been found by the first steps of the pipeline (full text search and re-ranking).
Parameters
To run experiments pipelines need to be built that can be configured easily. The question-answering repo contains a Java application which exposes these parameters as environment variables.
There are a lot of possible variations:
- Which Large Language Model is best for answer generation? How many passages should be passed in? Which prompt should be used?
- How exactly to do full text search queries?
- Should the full documents of the data corpus be split first into smaller passages?
- Should a re-ranker be used? Which one? With how many passages?
- And much more …
Metrics
To run the evaluations efficiently, I put metrics into the pipeline app. Every endpoint invocation creates a ‘last run’ markdown file.
Additionally, two csv files are created that contain all metadata and all 100+ queries of an experiment.
- ENDPOINT
- DISCOVERY_MAX_OUTPUT_DOCUMENTS
- RERANKER_MAX_INPUT_DOCUMENTS
- RERANKER_MODEL
- RERANKER_ID
- LLM_NAME
- LLM_MIN_NEW_TOKENS
- LLM_MAX_NEW_TOKENS
LLM_MAX_INPUT_DOCUMENTS
- QUERY
- ANSWER
- PROMPT
- RESULT_PASSAGE1
- RESULT_PASSAGE1_ID
- RESULT_PASSAGE2
- RESULT_PASSAGE2_ID
- RESULT_PASSAGE3
- RESULT_PASSAGE4_ID
- SIZE_DISCOVERY_RESULTS
- SIZE_RERANKER_INPUTS
- SIZE_RERANKER_RESULTS
Automation is required to run the queries defined in the ground truth file, to produce all assets automatically and to run the comparisons against the ground truth file. We’ve built two containers to execute the experiments:
- Container with the pipeline functionality
- Container that invokes the queries and tracks output data
After an experiment all assets are put in Git to track progress and compare results.