
One of the most impressive features of Large Language Models (LLMs) is the ability to answer questions in fluent language. This post describes some of the underlaying techniques and how to avoid hallucination.
To build an Question Answering service usually multiple steps are taken as described below:
- Full-text searches on knowledge bases
- Identification of key words or passages in single documents
- Generation of answers by passing in context to LLMs
The video Open Source Generative AI in Question-Answering describes this in more detail.
Scenario
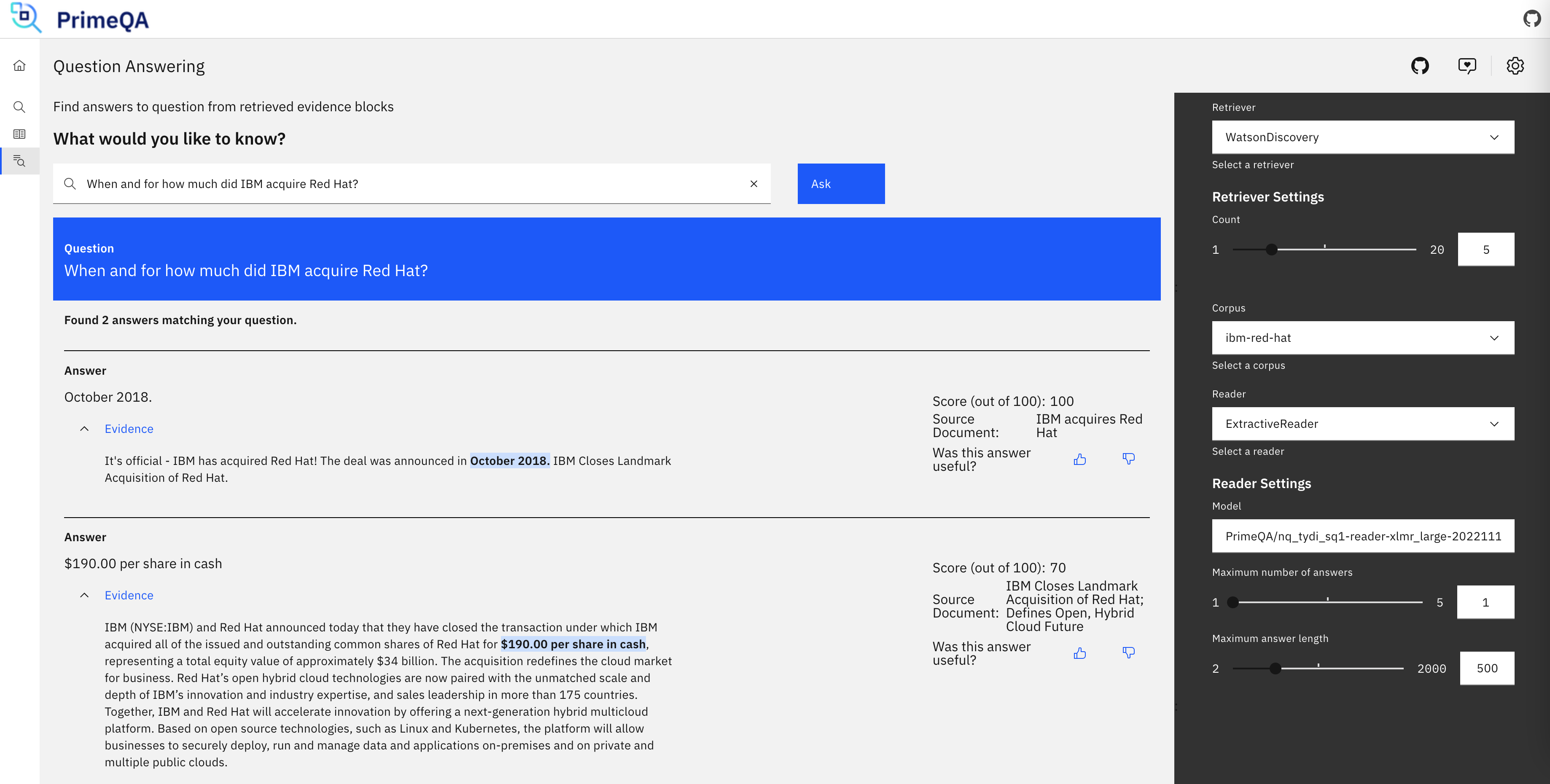
Let’s start with a simple sample. The goal is to answer the following question:
“When and for how much did IBM acquire Red Hat?”
There are two documents that are necessary to answer this question:
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"id": "0001",
"title": "IBM Closes Landmark Acquisition of Red Hat; Defines Open, Hybrid Cloud Future",
"link": "https://www.redhat.com/en/about/press-releases/ibm-closes-landmark-acquisition-red-hat-34-billion-defines-open-hybrid-cloud-future",
"text": "IBM (NYSE:IBM) and Red Hat announced today that they have closed the transaction under which IBM acquired all of the issued and outstanding common shares of Red Hat for $190.00 per share in cash, representing a total equity value of approximately $34 billion. ..."
}
{
"id": "0002",
"title": "IBM acquires Red Hat",
"link": "https://www.ibm.com/support/pages/ibm-acquires-red-hat",
"text": "It's official - IBM has acquired Red Hat! The deal was announced in October 2018. IBM Closes Landmark Acquisition of Red Hat."
}
The answer should be something like this:
“October 2018. $190.00 per share in cash… representing a total equity value of approximately $34 billion. The acquisition redefines the cloud market for business.”
Step 1: Full-text Searches
In the first step searches to knowledge bases like databases or object storage are executed to find a good set of documents which most likely contain the answer or pieces of the answer.
This step is important to reduce hallucination, especially in scenarios like support chat clients where accuracy is key. The final answer from step 3 will primarily use the information from the documents identified in this step. This also helps with transparency since links to documents can be provided that contain the information from the answer and more details.
PrimeQA is an open source project contributed by IBM for ‘State-of-the-Art Multilingual Question Answering Research and Development’. My colleague Adam de Leeuw has written a nice blog Using PrimeQA For NLP Question Answering how we’ve set up PrimeQA in a VM with 16 GB RAM and without GPU. He has documented how to use a local index. You can also use Watson Discovery as backend without having to code anything.
Step 2: Identify Passages
In the next step passages, key words and signals are identified within the documents returned by the previous step. In the screenshot at the top “October 2018” and “$190.00 per share in cash” are identified for the two documents.
The second step can also be implemented with PrimeQA. While the first ‘retrieval’ step is a more classic search approach, the second ‘reader’ step leverages AI. Check out the documentation to find out which models are supported. I have used a RoBERTa multilingual model. The chosen model for this step primarily determines the hardware requirements to run PrimeQA.
Step 3: Generate Answers
In the last step the one answer for the one question is generated. This is often the most impressive part. Answers can be generated from one document only or from multiple documents. Parts of the answer can also originate from the used Large Language Model which means there is still a chance of hallucination without further curation.
There are different ways to implement this step. If you have lots of (labeled) data, it might be a good idea to choose a rather small LLM and fine tune it. However, Fine-Tuning is often not really ‘fine’ but requires a lot of compute.
Another simpler approach is to use Prompt Tuning as described in The Importance of Prompt Engineering:
- The documents from step 1 are passed in as context.
- The signals/passages from step 2 are passed in as hint in the query.
- ‘Summarize the answer’ is appended to increase the chances to get fluent language.

In the screenshot above the FLAN-T5 model has been used with 11B parameters.
Resources
I’ve open sourced which is the starting point of a simple sample and have planned to extend it. I’ll also blog more about how the ‘Question Answering’ microservice has been implemented.