
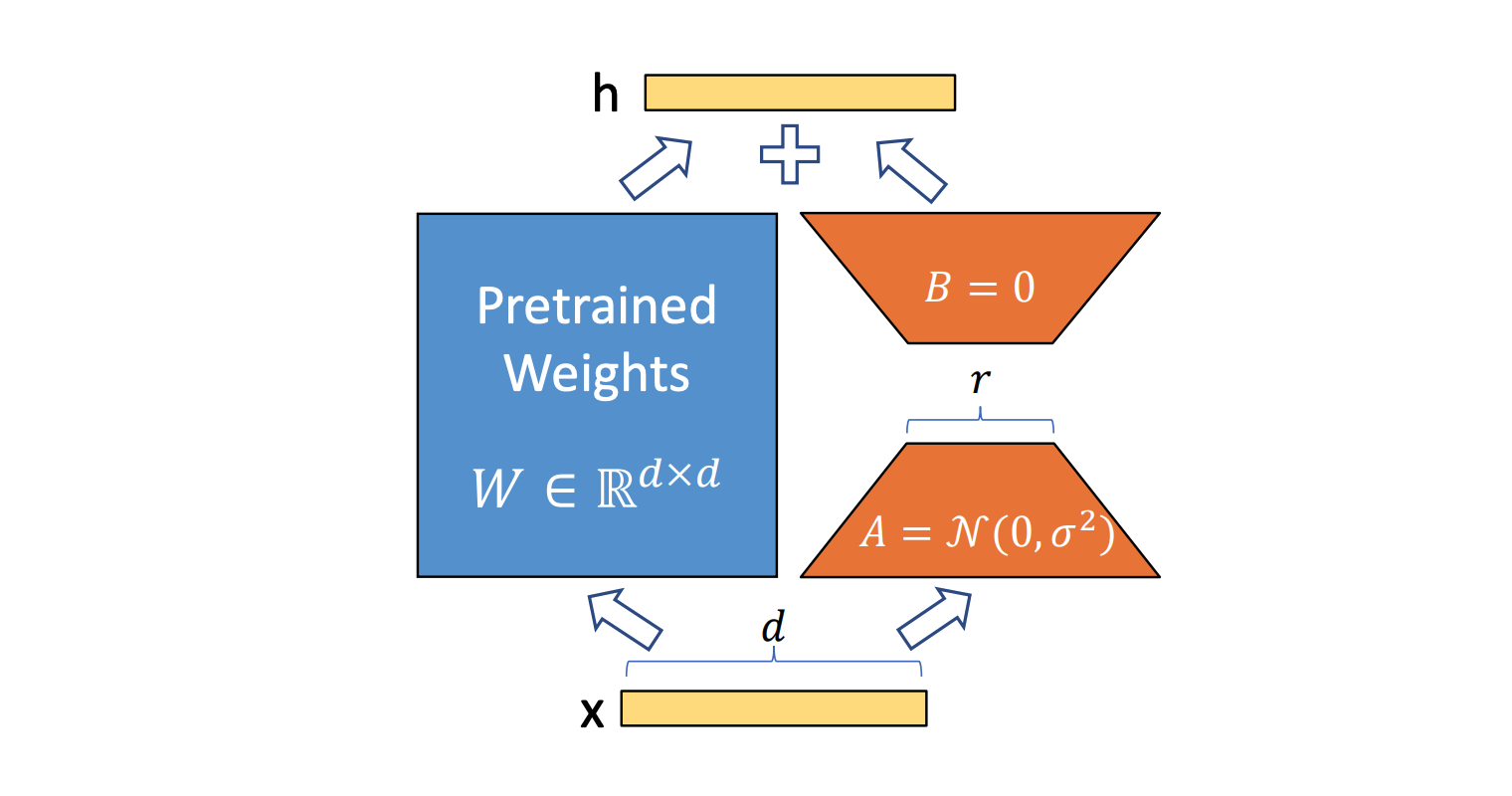
Classic fine-tuning of Large Language Models typically changes most weights of the models which requires a lot of resources. LoRA based fine-tuning freezes the original weights and only trains a small number of parameters making the training much more efficient.
Philipp Schmid from Hugging Face compares in his blog post classic fine-tuning and LoRA fine-tuning:
“This [LoRA] tutorial was created and run on a g5.2xlarge AWS EC2 Instance, including 1 NVIDIA A10G. The training took ~10:36:00 and cost ~13$ for 10h of training. For comparison a full fine-tuning on FLAN-T5-XXL with the same duration (10h) requires 8x A100 40GBs and costs ~322$.”
PEFT
PEFT is a library from Hugging Face which comes with several options to train models efficiently, one of them is LoRA.
PEFT, or Parameter-Efficient Fine-Tuning (PEFT), is a library for efficiently adapting pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model’s parameters. PEFT methods only fine-tune a small number of (extra) model parameters, significantly decreasing computational and storage costs because fine-tuning large-scale PLMs is prohibitively costly. Recent state-of-the-art PEFT techniques achieve performance comparable to that of full fine-tuning.
LoRA
LoRA was introduced at the end of 2021 in the paper LoRA: Low-rank adaptation of Large Language Models.
To make fine-tuning more efficient, LoRA’s approach is to represent the weight updates with two smaller matrices (called update matrices) through low-rank decomposition. These new matrices can be trained to adapt to the new data while keeping the overall number of changes low. The original weight matrix remains frozen and doesn’t receive any further adjustments. To produce the final results, both the original and the adapted weights are combined.
Models that want to support LoRA fine-tuning need to provide adapters. There is a list on Hugging Face with the supported models which covers popular open source models and it is growing.
Example
In addition to loading the model, you also need to get the PEFT version of the model which comes with the adapter which adds extra layers to the original architecture.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-xxl", load_in_8bit=True, device_map="auto")
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.05,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM
)
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# trainable params: 18874368 || all params: 11154206720 || trainable%: 0.16921300163961817
Based on the model and the LoRA config different amounts of parameters can be trained. In this example 0.16% of all parameters.
Read the blog post Efficient Large Language Model training with LoRA and Hugging Face for a complete example.
As stated at the end of the post the results are impressive: “Our PEFT fine-tuned FLAN-T5-XXL achieved a rogue1 score of 50.38% on the test dataset. For comparison a full fine-tuning of flan-t5-base achieved a rouge1 score of 47.23. That is a 3% improvements.”
Advantages
There are some additional advantages that LoRA provides. One is to use quantization which leads to memory reduction. Read the blog post on Hugging Face Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA for more details.
Some people claim that LoRA might also help to reduce catastrophic forgetting which happens when too much fine-tuning has been done. However, while the original weights are frozen, at inference time the additional parameters are utilized which lead to other results which is the whole point of fine-tuning.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.