
In the context of cloud-native applications the topic ‘reactive’ becomes more and more important, since more efficient applications can be built and user experiences can be improved. If you want to learn more about reactive functionality in Java applications, read on and try out the code.
Challenges when getting started with reactive Applications
While the topic ‘reactive’ has been around for quite some time, for some developers it’s not straightforward to get started with reactive applications. One reason is that the term is overloaded and describes different aspects, for example reactive programming, reactive systems, reactive manifesto and reactive streams. Another reason is that there are several different frameworks which support different functionality and use other terminologies. For example for me with my JavaScript background it wasn’t obvious to figure out the Java counterparts for JavaScript callbacks, promises and observables. Yet another reason why it can be challenging for some developers to get started is that reactive programming requires a different type of thinking compared to writing imperative code.
There are a lot of resources available to start learning various reactive concepts. When learning new technologies simple tutorials, samples and guides help to understand specific functions. In order to understand how to use the functions together, it helps me to look at more complete applications with use cases that come closer to what developers need when building enterprise applications. Because of this I’ve implemented a sample application which shows various aspects of reactive programming and reactive systems and which can be easily deployed on Kubernetes platforms.
Architecture of the Sample Application
Rather than reinventing the wheel, I reused the scenario from the cloud-native-starter project which shows how to develop and operate synchronous microservices that use imperative programming.
The sample comes with a web application which displays links to articles with author information in a simple web application. The web application invokes the web-api service which implements a backend-for-frontend pattern and invokes the articles and authors service. The articles service stores data in a Postgres database. Messages are sent between the microservices via Kafka. This diagram describes the high level architecture:
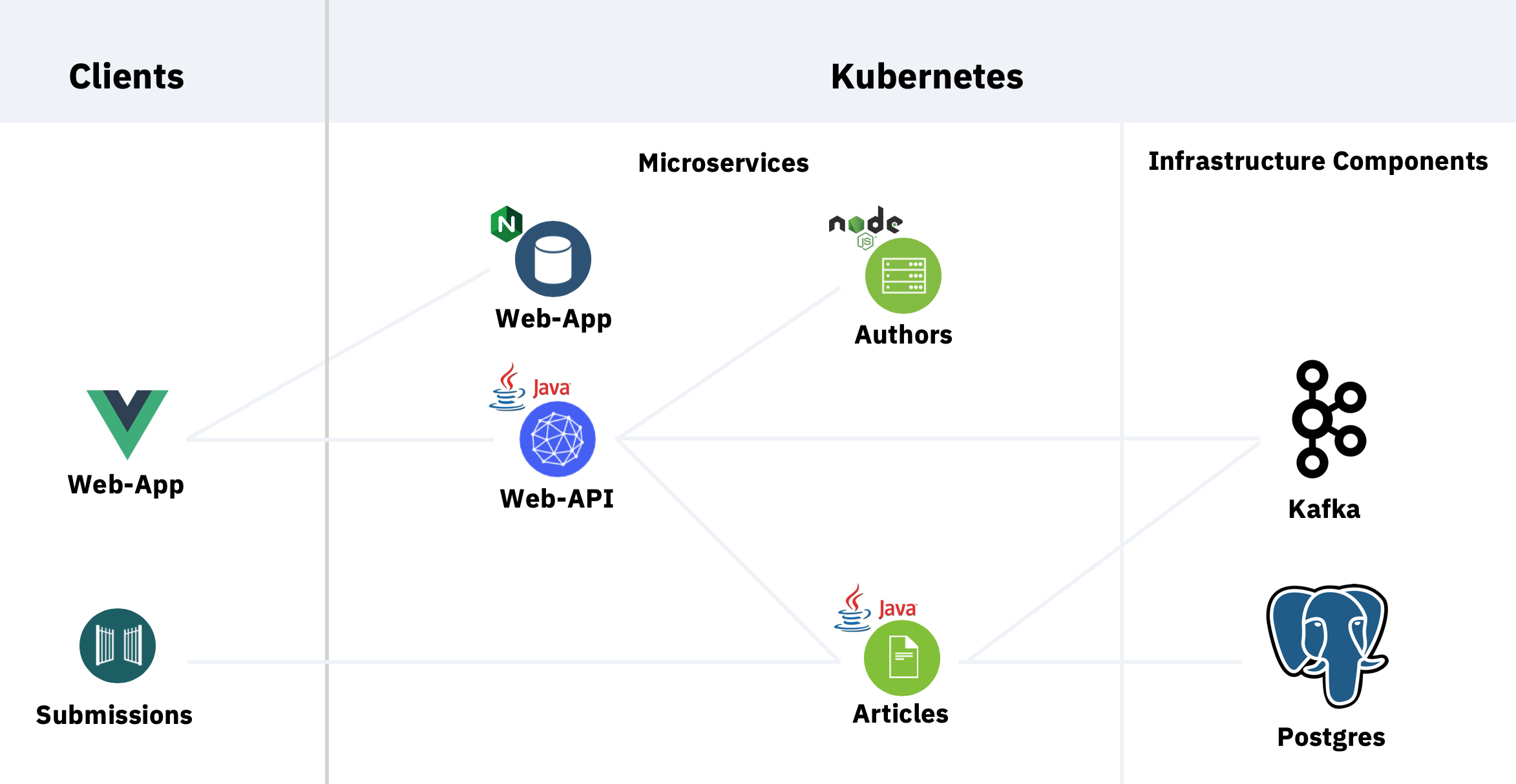
Technologies and Functionality
The sample leverages heavily Quarkus which is “a Kubernetes Native Java stack […] crafted from the best of breed Java libraries and standards”. Additionally Eclipse MicroProfile, Eclipse Vert.x, Apache Kafka, PostgreSQL, Eclipse OpenJ9 and Kubernetes are used.
Over the next days I’ll try to blog about the following functionality:
- Sending in-memory messages via MicroProfile
- Sending in-memory messages via Vertx event bus
- Sending and receiving Kafka messages via MicroProfile
- Sending Kafka messages via Kafka API
- Reactive REST endpoints via CompletionStage
- Reactive REST invocations via Vertx Axle Web Client
- Reactive REST invocations via MicroProfile REST Client
- Exception handling in chained reactive invocations
- Timeouts via CompletableFuture
- Resiliency of reactive microservices
- Reactive CRUD operations for Postgres
The sample application demonstrates several scenarios and benefits of reactive applications.
Scenario 1: Reactive Messaging
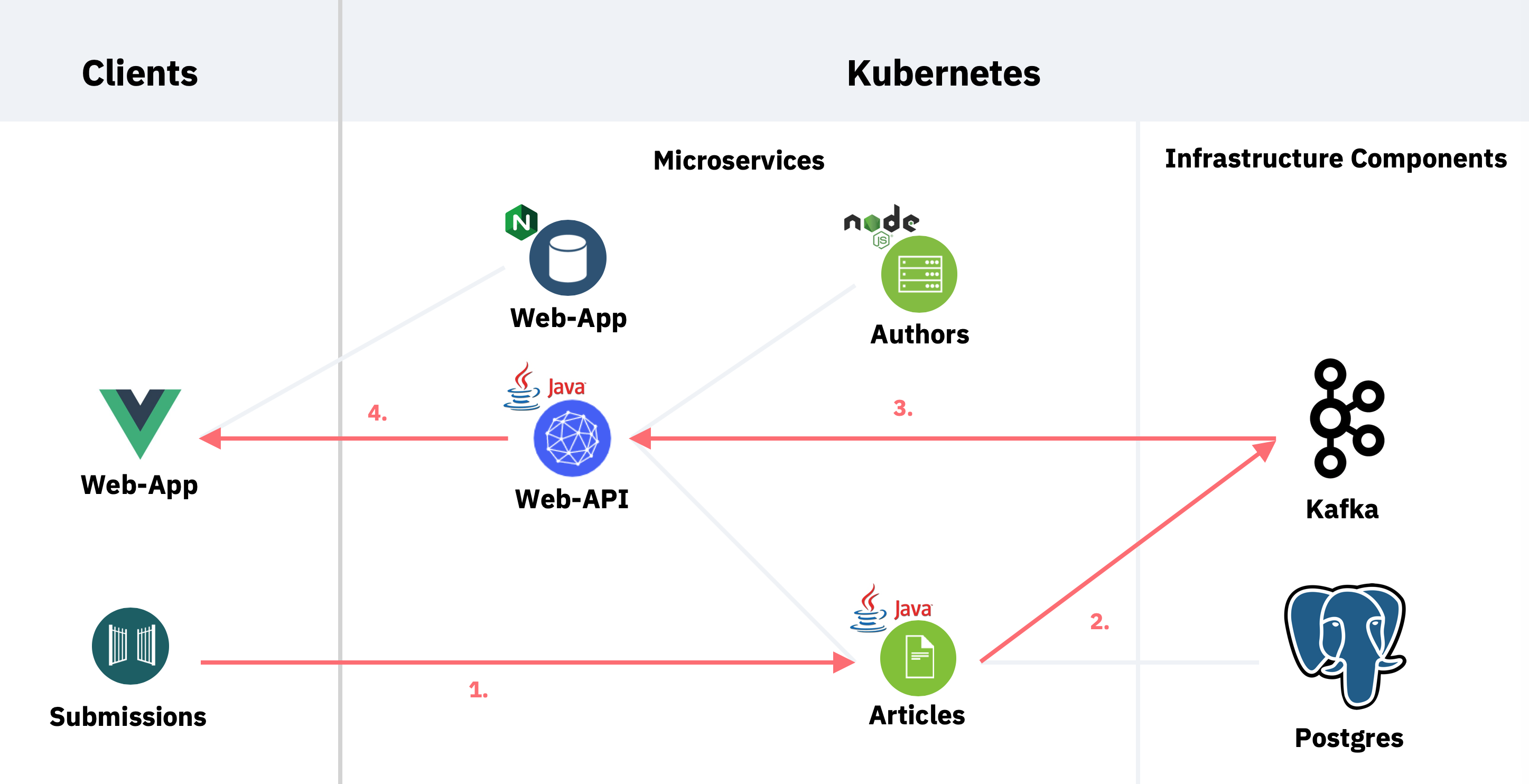
One benefit of reactive models is the ability to update web applications by sending messages, rather than pulling for updates. This is more efficient and improves the user experience.
Articles can be created via REST API. The web application receives a notification and adds the new article to the page.
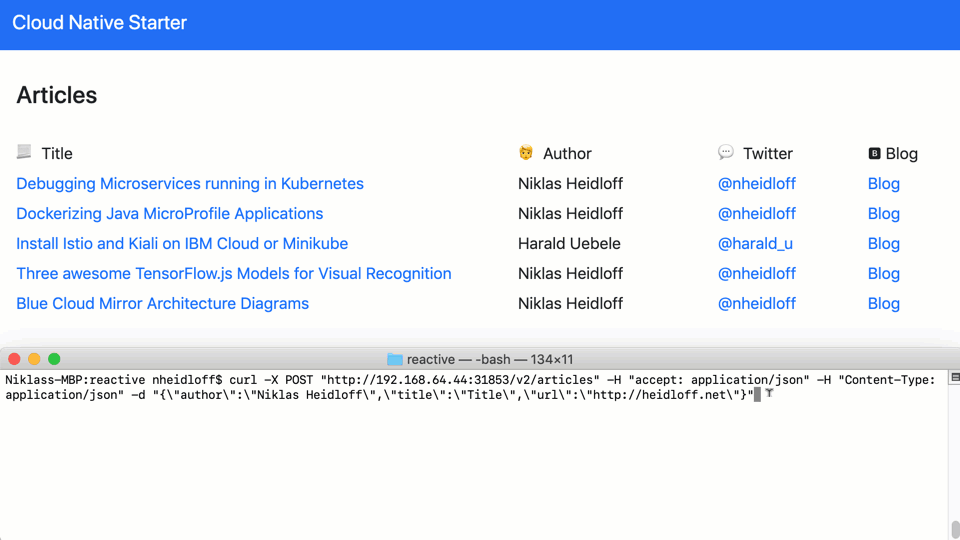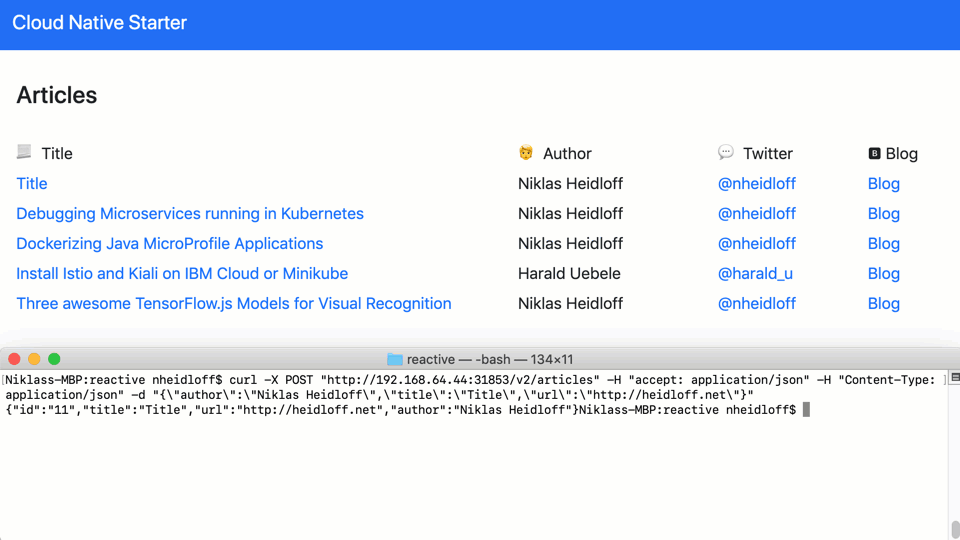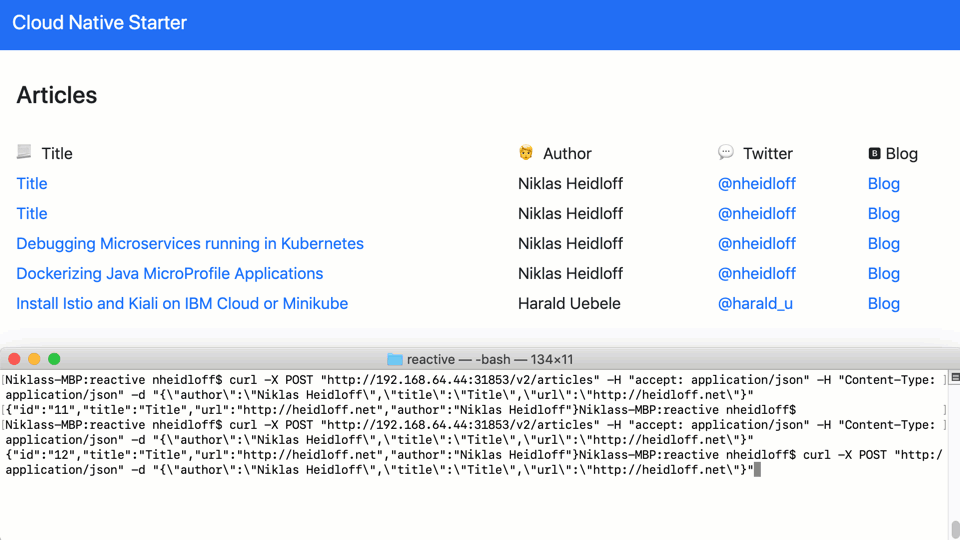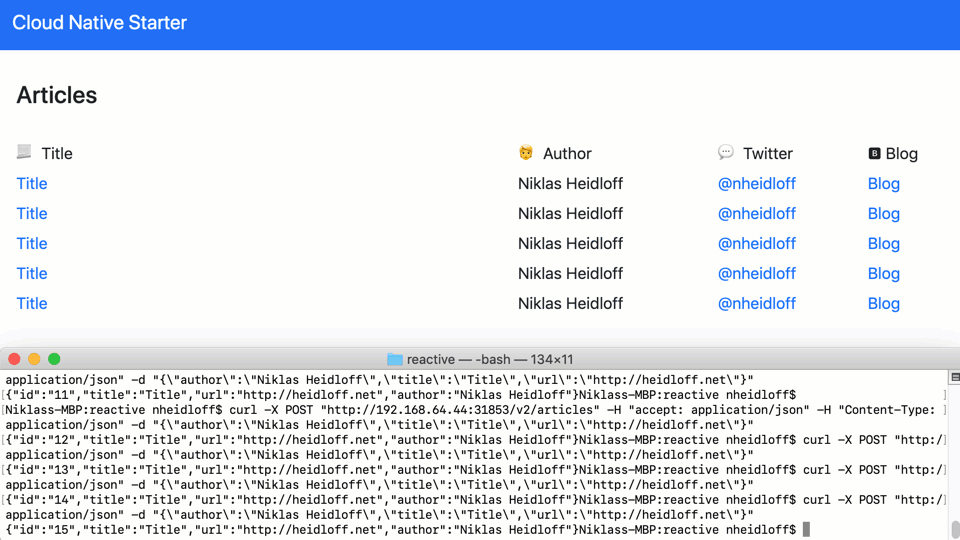
This diagram explains the flow:
Scenario 2 – Reactive REST Endpoints for higher Efficiency
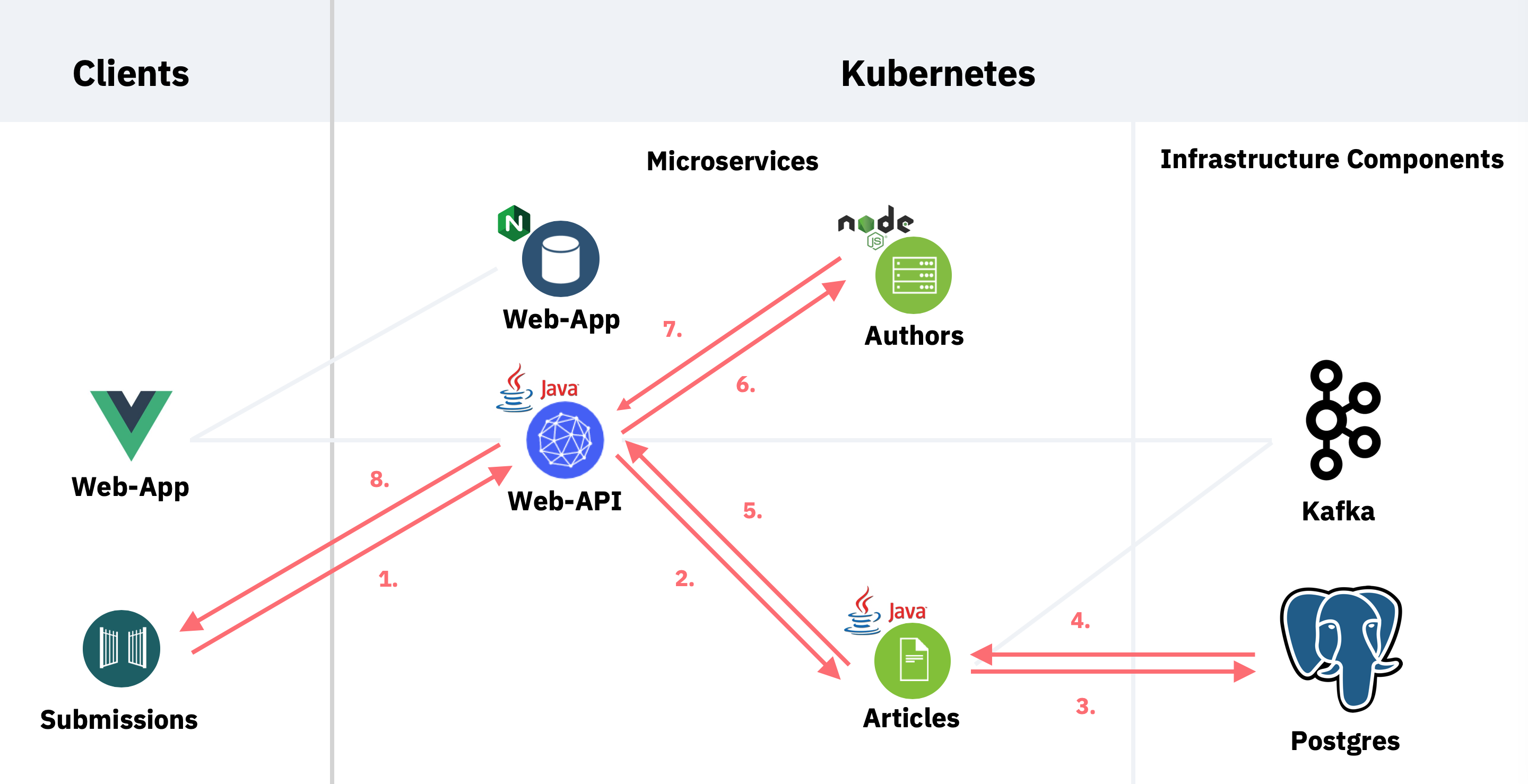
Another benefit of reactive systems and reactive REST endpoints is efficiency. This scenario describes how to use reactive systems and reactive programming to achieve faster response times. Especially in public clouds where costs depend on CPU, RAM and compute durations this model saves money.
The project contains the endpoint ‘/articles’ of the web-api service in two different versions, one uses imperative code, the other one reactive code.
The reactive stack of this sample provides response times that take less than half of the time compared to the imperative stack: Reactive: 793 ms – Imperative: 1956 ms.
Read the documentation for details.
This diagram explains the flow:
This is the result of the imperative version after 30000 invocations:

This is the result of the reactive version after 30000 invocations:

Supported Kubernetes Environments
We have put a lot of effort in making the setup of the sample as easy as possible. For all components and services there are scripts to deploy and configure everything. For example if you have Minikube installed, the setup shouldn’t take longer than 10 minutes.
Closing Thoughts
A big thank you goes to Harald Uebele and Thomas Südbröcker for their ongoing support. Especially I want to thank Harald for writing the deployment scripts for CodeReady Containers and Thomas for writing the deployment scripts for IBM Cloud Kubernetes Service. Additionally I want to thank Sebastian Daschner for providing feedback and sending pull requests.
Try out the code yourself!
Read the other articles of this series:
- Development of Reactive Applications with Quarkus
- Accessing Apache Kafka from Quarkus
- Accessing PostgreSQL in Kubernetes from Quarkus
- Reactive Messaging Examples for Quarkus
- Developing reactive REST APIs with Quarkus
- Invoking REST APIs asynchronously with Quarkus
- Comparing synchronous and asynchronous Access to Postgres