
The open source project cloud-native-starter describes how to develop reactive applications with Quarkus. One of the demonstrated functions is reactive access to PostgreSQL. This article describes options how to deploy Postgres to Kubernetes environments and how to configure Quarkus to access it.
I’ve picked PostgreSQL as database for the cloud-native-starter sample application for several reasons. One reason was that Quarkus provides great guides to access Postgres via a reactive SQL client and via JPA and Panache. In order to compare the synchronous/imperative model with the asynchronous/reactive model, I’ve implemented two versions of my microservice, one using the imperative model, one using the reactive model. You can find results of this comparison in the documentation.
In both cases you need access to a PostgreSQL database first. The Quarkus guides describe how to run Postgres locally via Docker. This works when you develop microservices locally which access local databases. If you want to run your microservices in Kubernetes environments, accessing local databases is tricky. It’s easier to access databases running in the same Kubernetes clusters or to access hosted Postgres services.
Configuration of Quarkus Microservices
In order to access Postgres from microservices developed with Quarkus, you need to define the configuration in ‘application.properties’. When you want to use the reactive driver to access Postgres running in Kubernetes, you need configuration like this. ‘database-articles’ is the Kubernetes service name and ‘my-postgresql-operator-dev4devs-com’ is the namespace.
1
2
3
quarkus.datasource.url=vertx-reactive:postgresql://database-articles.my-postgresql-operator-dev4devs-com:5432/postgres
quarkus.datasource.username=postgres
quarkus.datasource.password=postgres
When developing your microservices locally, the URL needs to point to Postgres running in Kubernetes. This is how you find out the URL for Minikube environments:
1
2
3
$ minikubeip=$(minikube ip)
$ nodeport=$(kubectl get svc my-cluster-kafka-external-bootstrap -n kafka --ignore-not-found --output 'jsonpath={.spec.ports[*].nodePort}')
$ echo ${minikubeip}:${nodeport}
Postgres Deployment Option 1: OpenShift Web Console
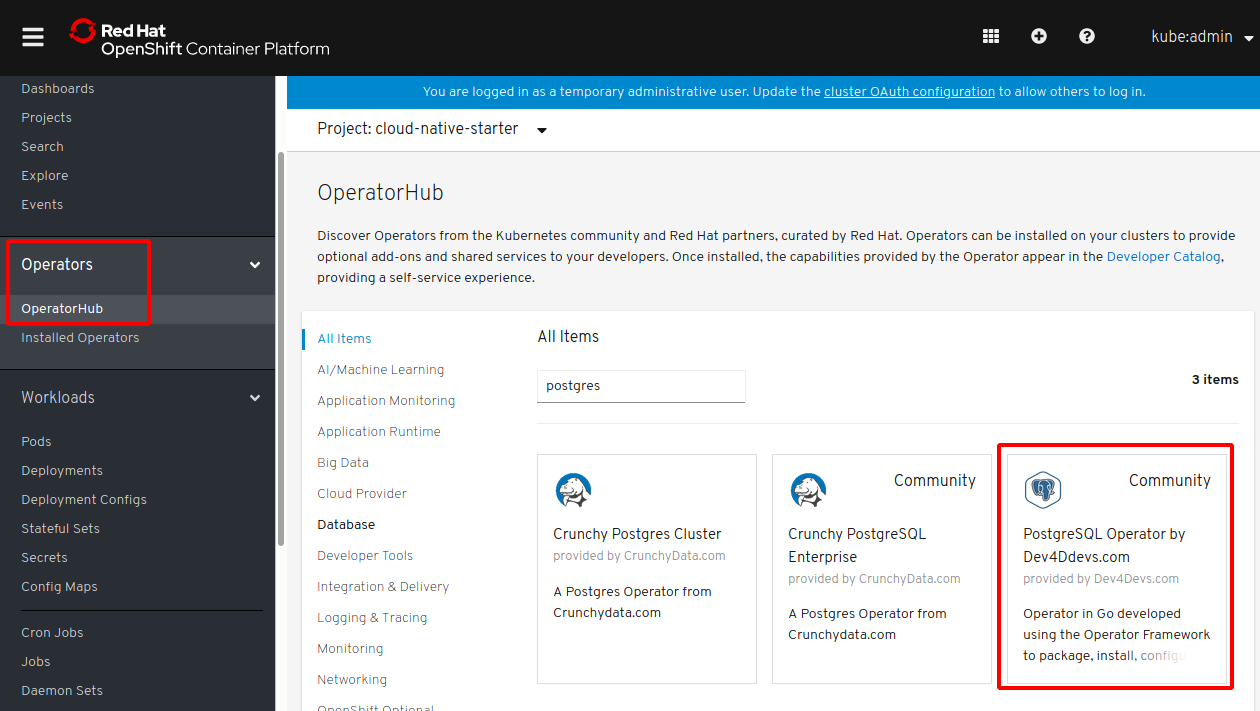
There are many different ways to deploy Postgres to Kubernetes. One way is to use operators. For the cloud-native-starter project we picked PostgreSQL Operator by Dev4Ddevs.com. Especially when you have OpenShift the installation is trivial, since a nice dashboard is provided to do this via a graphical interface.
My colleague Harald Uebele describes in his documentation the exact steps. In the cloud-native-starter project we’ve used CodeReady Containers to run OpenShift 4 locally. As soon as OpenShift 4 will be available on the IBM Cloud, the same instructions should work there as well.
This screenshot shows where you can initiate the deployment from the OpenShift web console.
Postgres Deployment Option 2: Kubernetes with persistent Volume
The same operator can be deployed to Minikube. Since Minikube doesn’t come with the Operator Lifecycle Manager preinstalled, it needs to be installed first. The following scripts deploy everything needed including the setup of a database.
1
2
3
4
5
6
$ git clone https://github.com/IBM/cloud-native-starter.git
$ cd cloud-native-starter/reactive
$ sh scripts/start-minikube.sh
$ sh scripts/deploy-postgres-operator.sh
$ sh scripts/deploy-postgres-database.sh
$ sh scripts/show-urls.sh
The output of the last command prints out the URL of Postgres which you need to define in the ‘application.properties’ file above.
Postgres Deployment Option 3: Kubernetes without persistent Volume
The deployment option 2 uses a persistent volume. For Minikube this is not an issue. Some other Kubernetes environments might have limitations in some cases, for example when they are provided for free. That’s why we’ve added another option to deploy Postgres to Kubernetes.
Note that this option is only (sometimes) useful for development and not for production. Data is lost every time the container is restarted.
The deployment is very easy. All you need is one yaml file with the configuration and one ‘kubectl’ CLI command to create the Kubernetes resources. We’ve also written a script:
1
2
3
4
5
$ git clone https://github.com/IBM/cloud-native-starter.git
$ cd cloud-native-starter/reactive
$ sh scripts/start-minikube.sh
$ sh scripts/deploy-postgres.sh
$ sh scripts/show-urls.sh
IBM provides a free Kubernetes cluster for development and testing. My colleague Thomas Südbröcker describes how to set it up in his documentation.
The free Kubernetes cluster has some limitations. One is that persistent volumes are not fully enabled. That’s why we use in the cloud-native-starter project the Postgres image that doesn’t require a persistent volume.
Postgres Admin Client
I’ve also written a script to deploy pgAdmin. This is useful during development to test whether databases could be accessed successfully. To install it, run this command (user: admin, password: admin):
1
2
$ sh scripts/deploy-postgres-admin.sh
$ minikube service pgadmin -n demo --url
Next Steps
If you want to learn more about reactive programming and reactive access to Postgres, try out the code yourself.
Read the other articles of this series:
- Development of Reactive Applications with Quarkus
- Accessing Apache Kafka from Quarkus
- Accessing PostgreSQL in Kubernetes from Quarkus
- Reactive Messaging Examples for Quarkus
- Developing reactive REST APIs with Quarkus
- Invoking REST APIs asynchronously with Quarkus
- Comparing synchronous and asynchronous Access to Postgres