
This post is part of a mini series which describes an AI text classification sample end to end using Watson NLP (Natural Language Understanding) and Watson Studio. This part explains how to train custom models with Watson NLP and Watson Studio.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Overview
The training is done via IBM Watson Studio. IBM partners can get a test environment on IBM TechZone.
For the training an ensemble model is used which combines three classification models. It computes the weighted mean of classification predictions using confidence scores. It depends on the syntax model and the GloVe and USE embeddings.
- CNN
- SVM with TF-IDF features
- SVM with USE (Universal Sentence Encoder) features
You can find more details about how to train Watson NLP models in the Cloud Pak for Data documentation.
Architecture:

Walk-through
Let’s take a look at Watson Studio and the notebook. See the screenshots for a detailed walk-through.
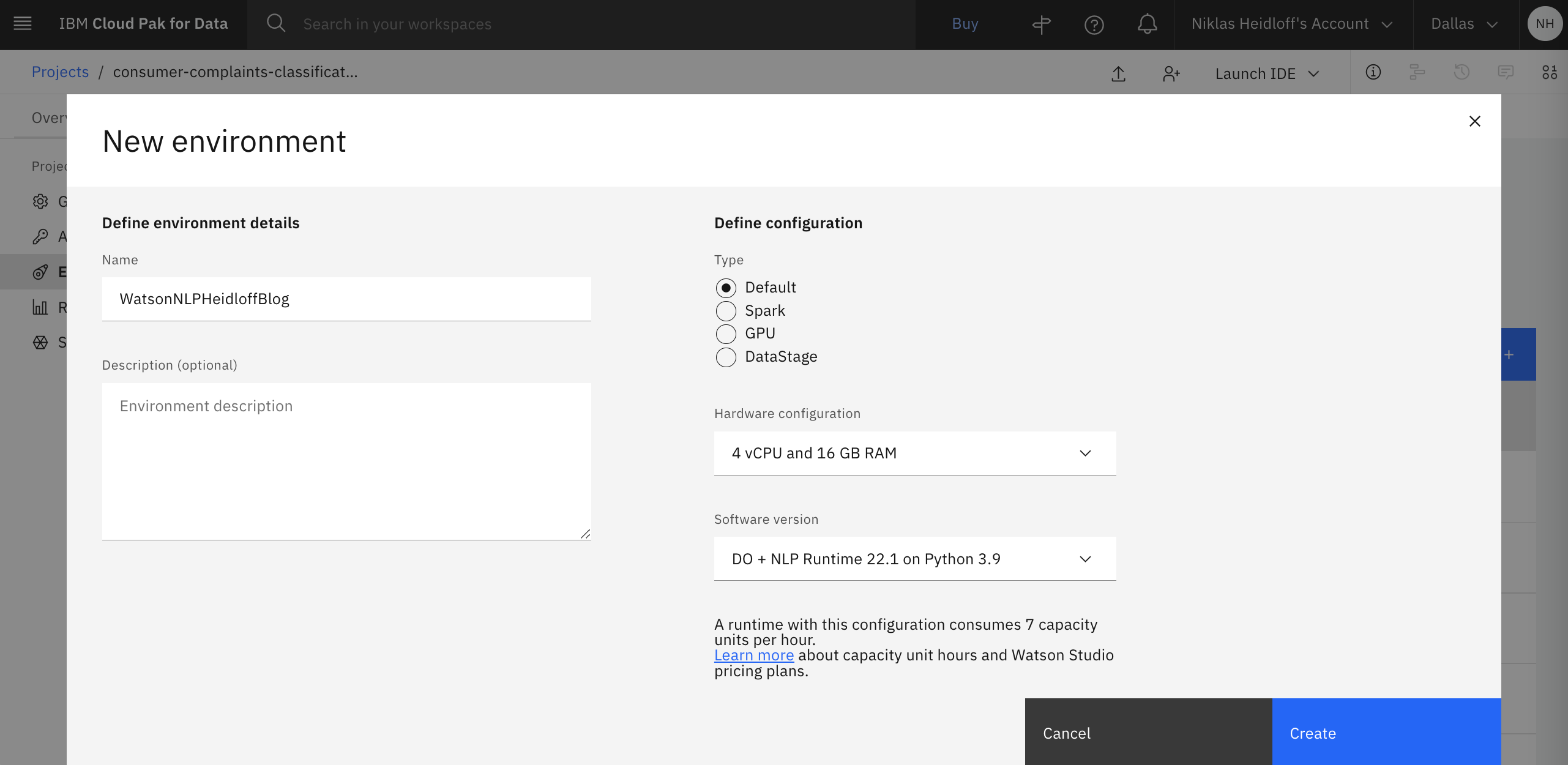
Choose the runtime template ‘DO + NLP Runtime 22.1 on Python 3.9 (4 vCPU and 16 GB RAM)’ and upload the notebook from the repo.
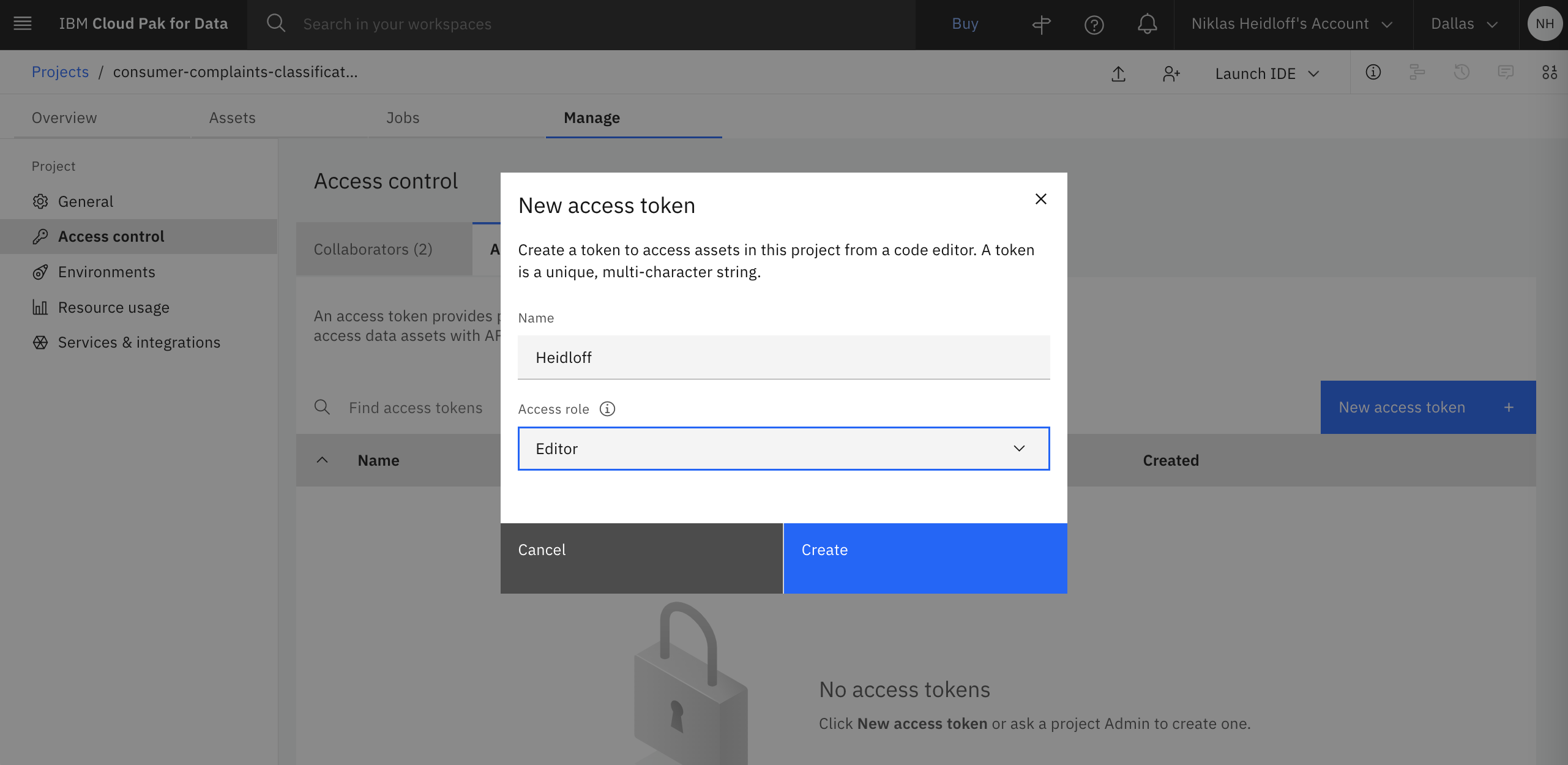
Before you run the notebook, create a project token with editor access so that the notebook can access project artifacts. Delete the first cell in the notebook and add the token to the notebook by clicking on the icon at the top with the three dots.
The ‘slightly modified’ CSV from the previous step is available on Box and is downloaded automatically by the notebook.
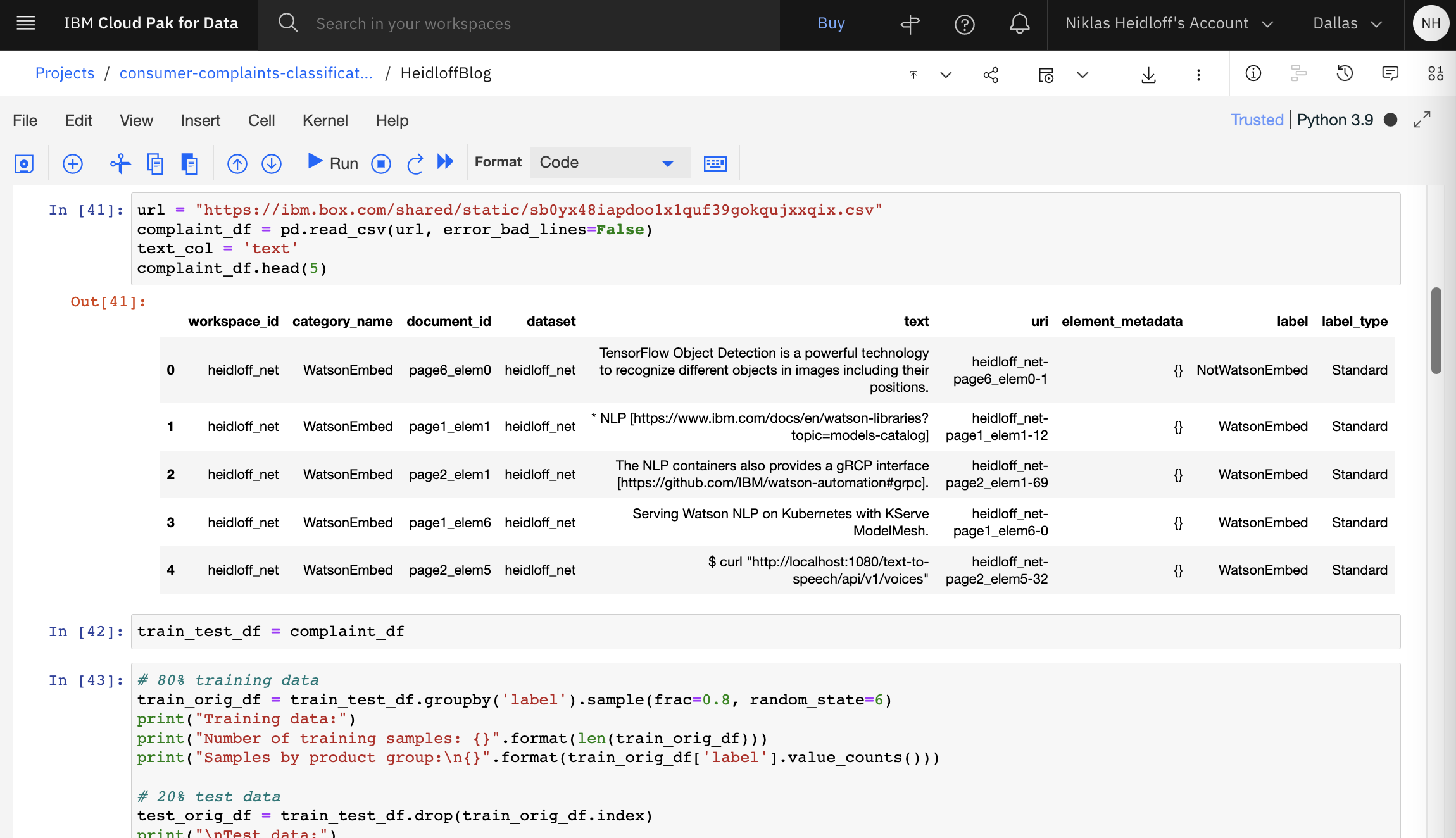
The data is split in training and testing sets.

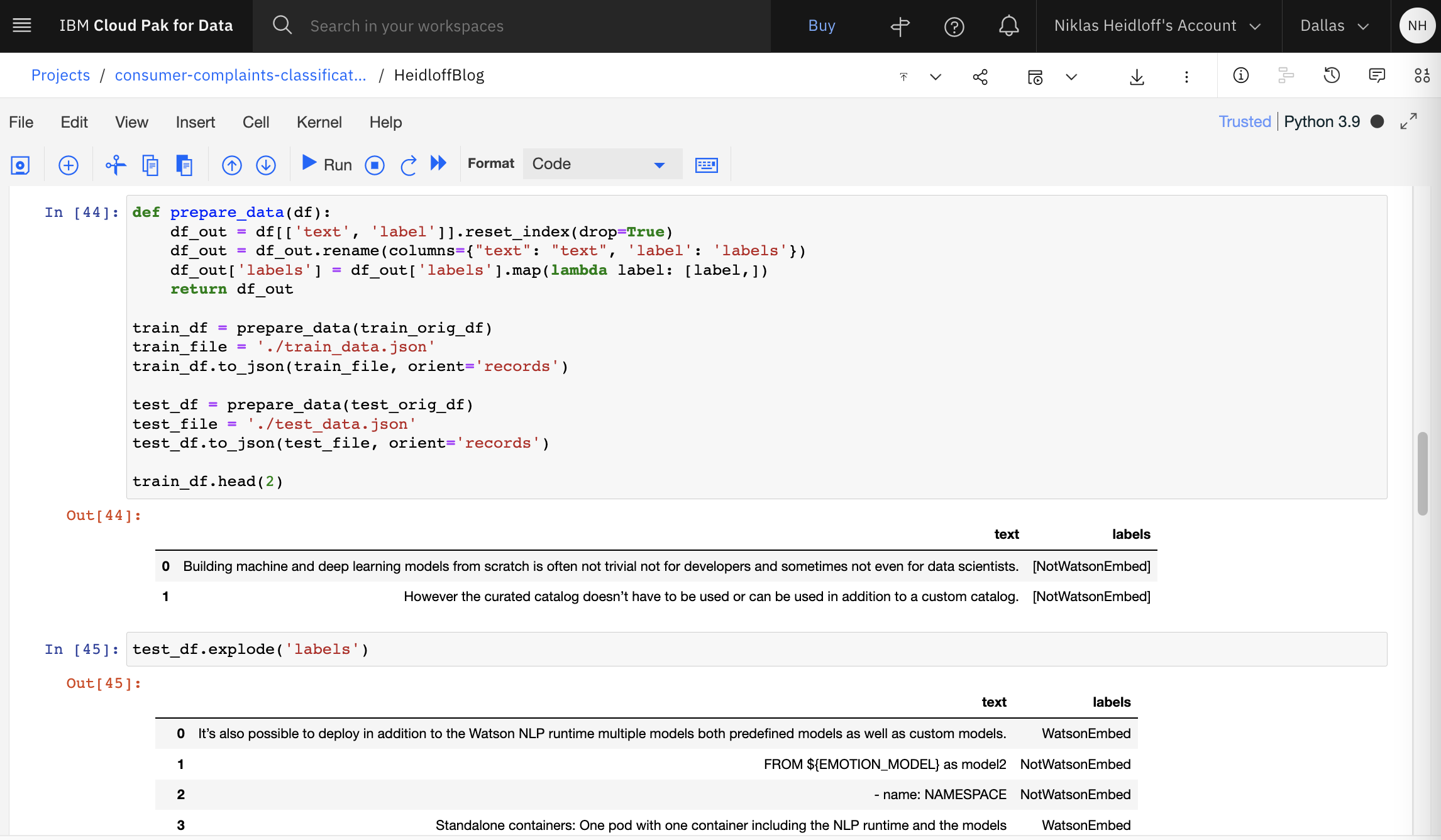
The data is modified to match the expected input of Watson NLP.
Here are snippets from the notebook how to run the training.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
syntax_model = watson_nlp.load(watson_nlp.download('syntax_izumo_en_stock'))
use_model = watson_nlp.load(watson_nlp.download('embedding_use_en_stock'))
training_data_file = train_file
data_stream_resolver = DataStreamResolver(target_stream_type=list, expected_keys={'text': str, 'labels': list})
training_data = data_stream_resolver.as_data_stream(training_data_file)
text_stream, labels_stream = training_data[0], training_data[1]
syntax_stream = syntax_model.stream(text_stream)
use_train_stream = use_model.stream(syntax_stream, doc_embed_style='raw_text')
use_svm_train_stream = watson_nlp.data_model.DataStream.zip(use_train_stream, labels_stream)
def predict_product(text):
ensemble_preds = ensemble_model.run(text)
predicted_ensemble = ensemble_preds.to_dict()["classes"][0]["class_name"]
return (predicted_ensemble, predicted_ensemble)
stopwords = watson_nlp.download_and_load('text_stopwords_classification_ensemble_en_stock')
ensemble_model = Ensemble.train(train_file, 'syntax_izumo_en_stock', 'embedding_glove_en_stock', 'embedding_use_en_stock', stopwords=stopword
predictions = test_orig_df[text_col].apply(lambda text: predict_product(text))
predictions_df = pd.DataFrame.from_records(predictions, columns=('Predicted SVM', 'Predicted Ensemble'))
result_df = test_orig_df[[text_col, "label"]].merge(predictions_df, how='left', left_index=True, right_index=True)
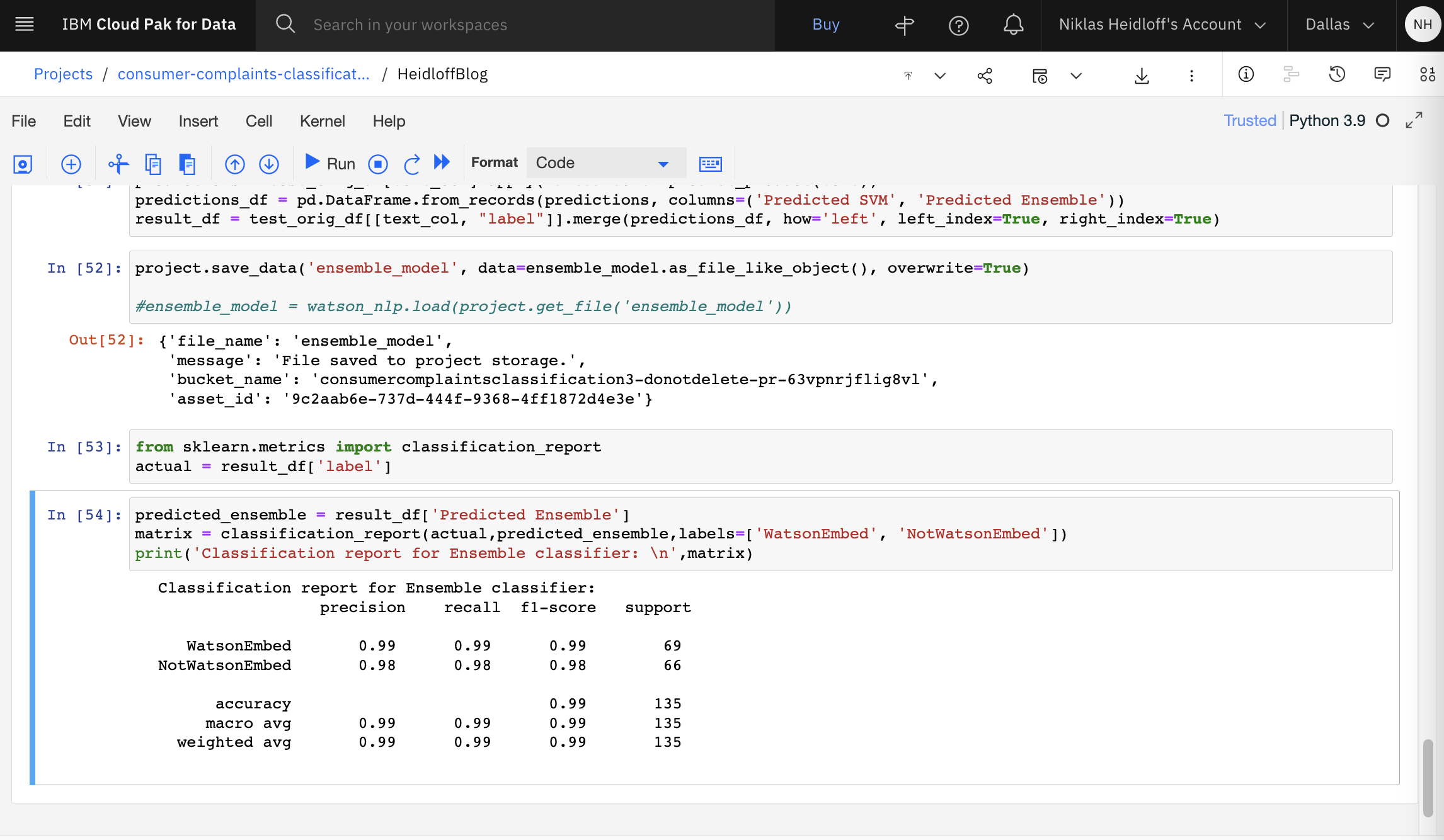
The results are displayed after the training and testing.
What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.