
This post is part of a mini series which describes an AI text classification sample end to end using Watson NLP (Natural Language Understanding) and Watson Studio. This part explains how to label sentences via the open source tool Label Sleuth.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Overview
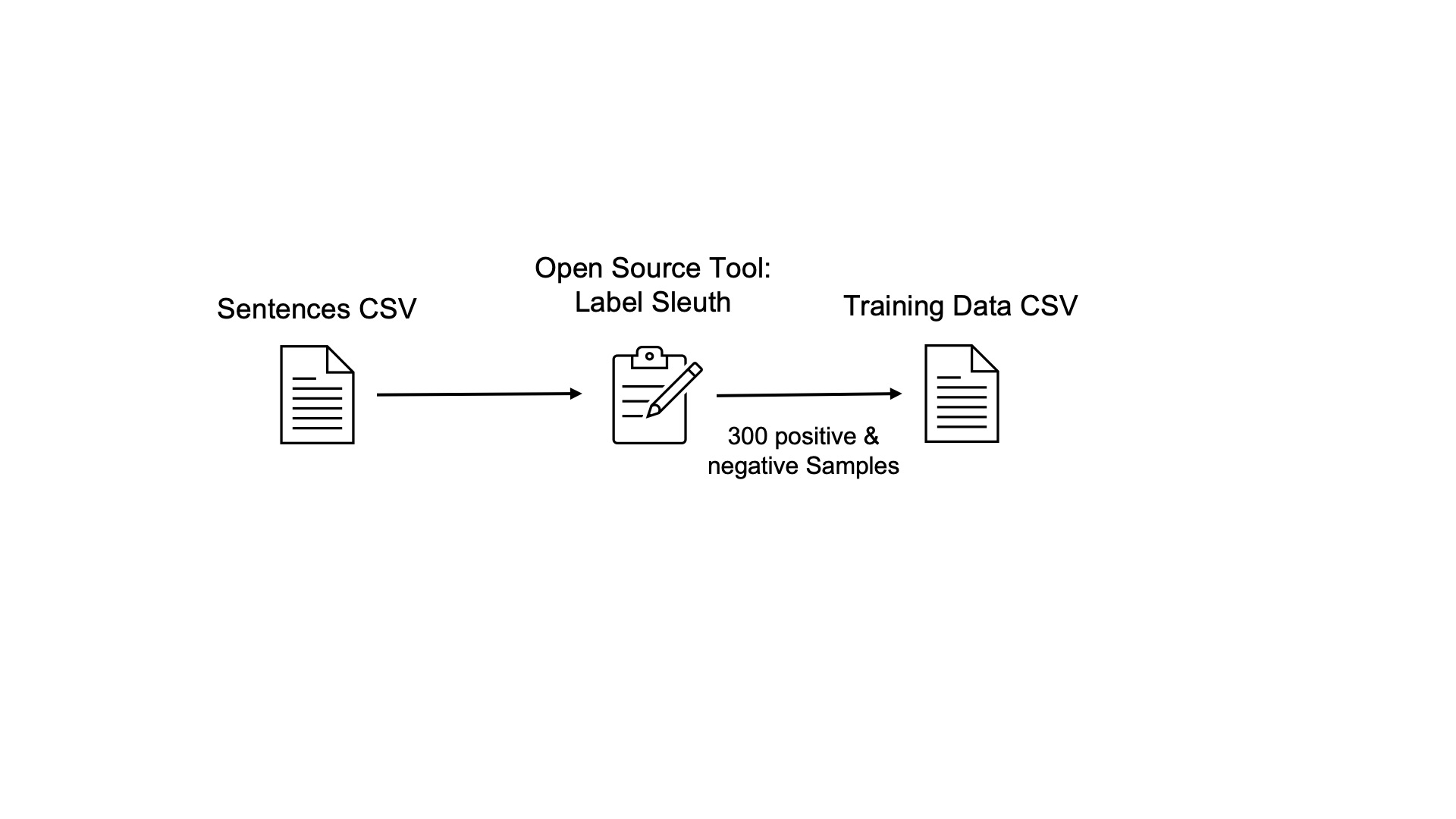
To classify blog posts from heidloff.net whether or not they are related to ‘Watson Embed’, sentences are labelled. If at least one sentence of a post is related to Watson Embed, the whole post is classified as Watson Embed.
To train models, good data needs to be available. In this scenario 200-300 positive sentences and 200-300 negative sentences need to be labelled by domain experts.
The labelling is done via the open source project from IBM, called Label Sleuth. The tool provides an easy to use web browser experience which provides suggestions what and how to label next entries. Note that not all sentences need to be labeled, but only the important ones. De-facto this removes noise from the original blog posts, for example headers, footers, generic code lines etc.
Architecture:
Walk-through
Let’s take a look at the tool. See the screenshots for a detailed walk-through.
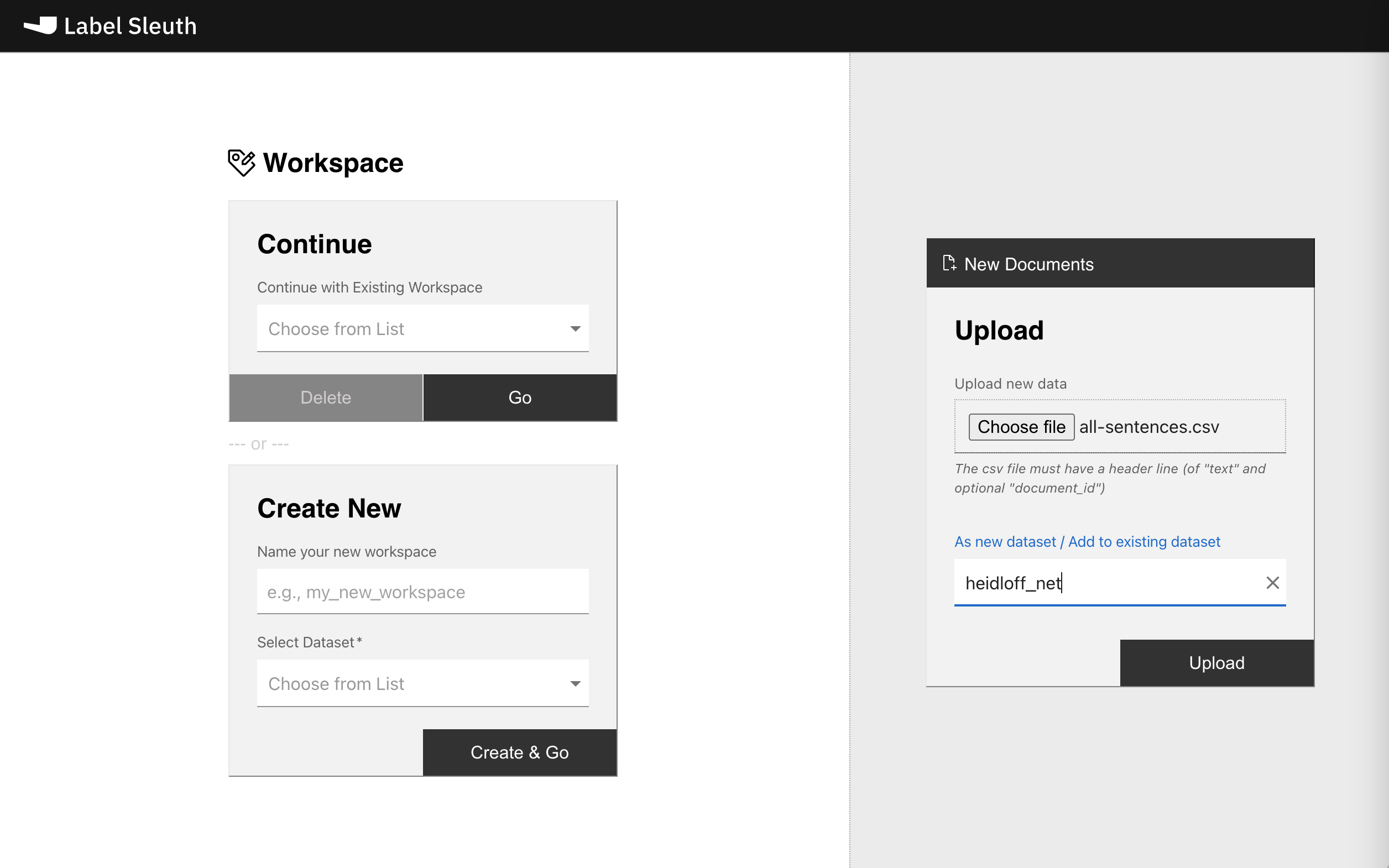
First the data is imported:
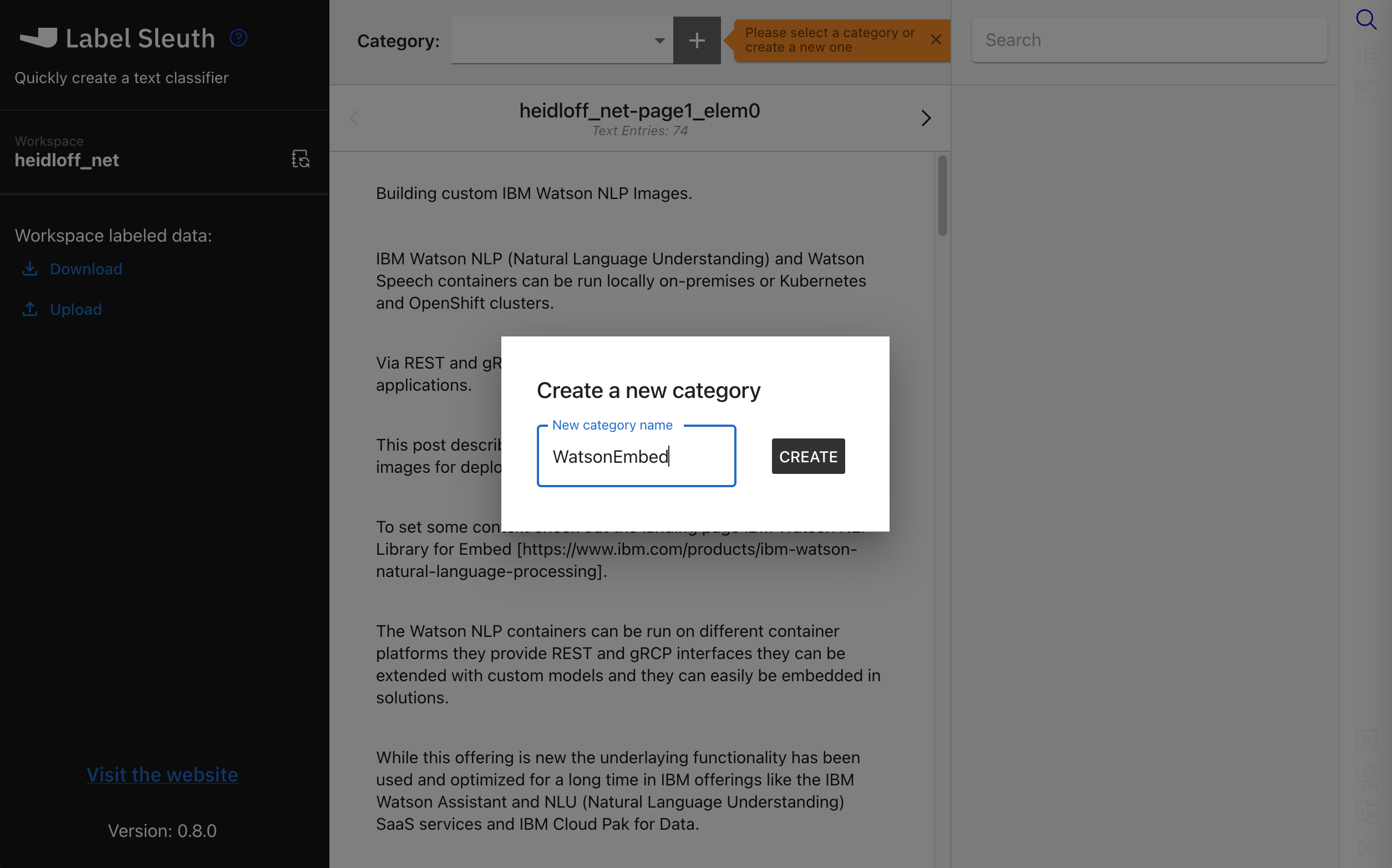
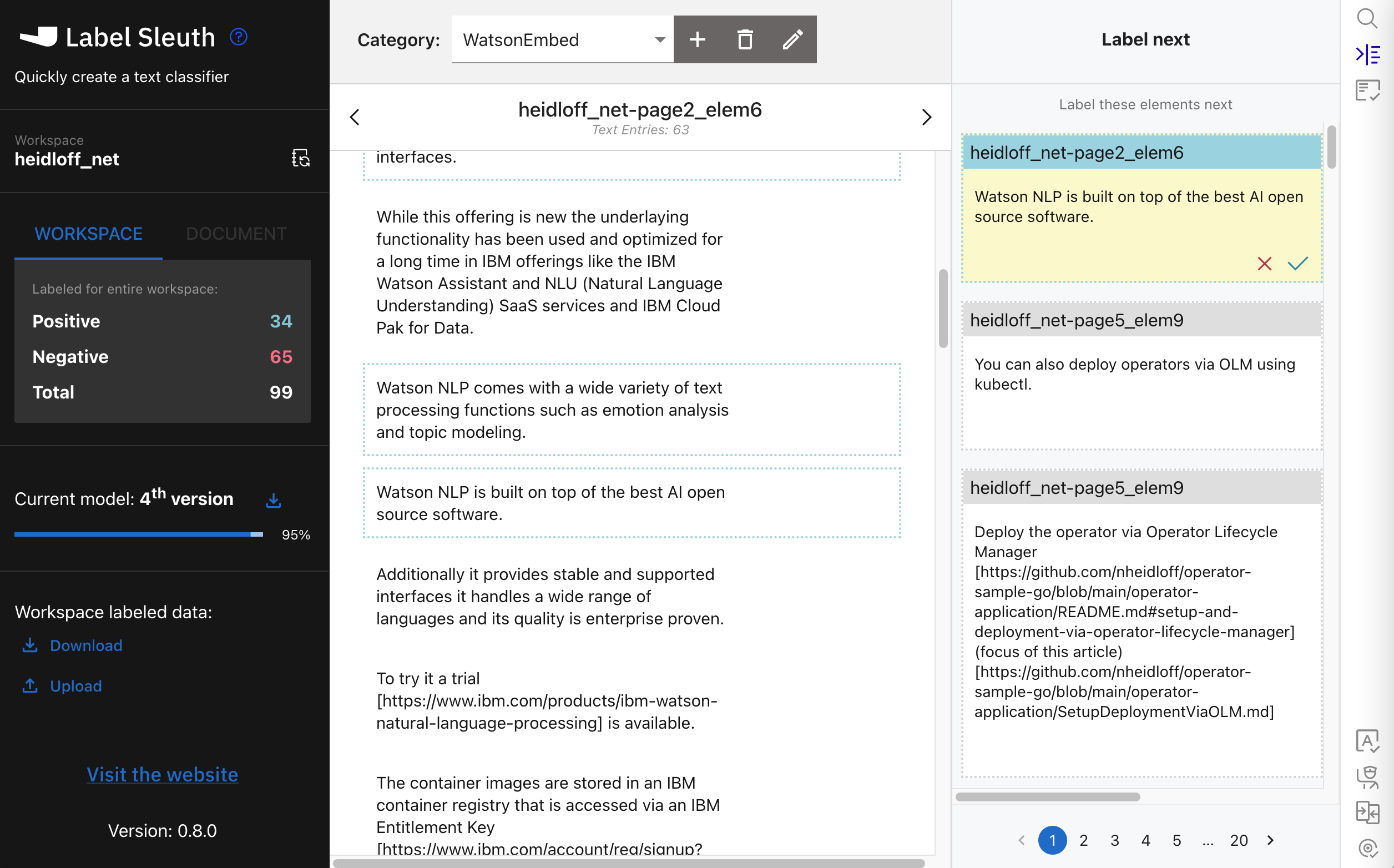
A category is created:
Typically you start by invoking a full text search for keywords to label obvious sentences first.
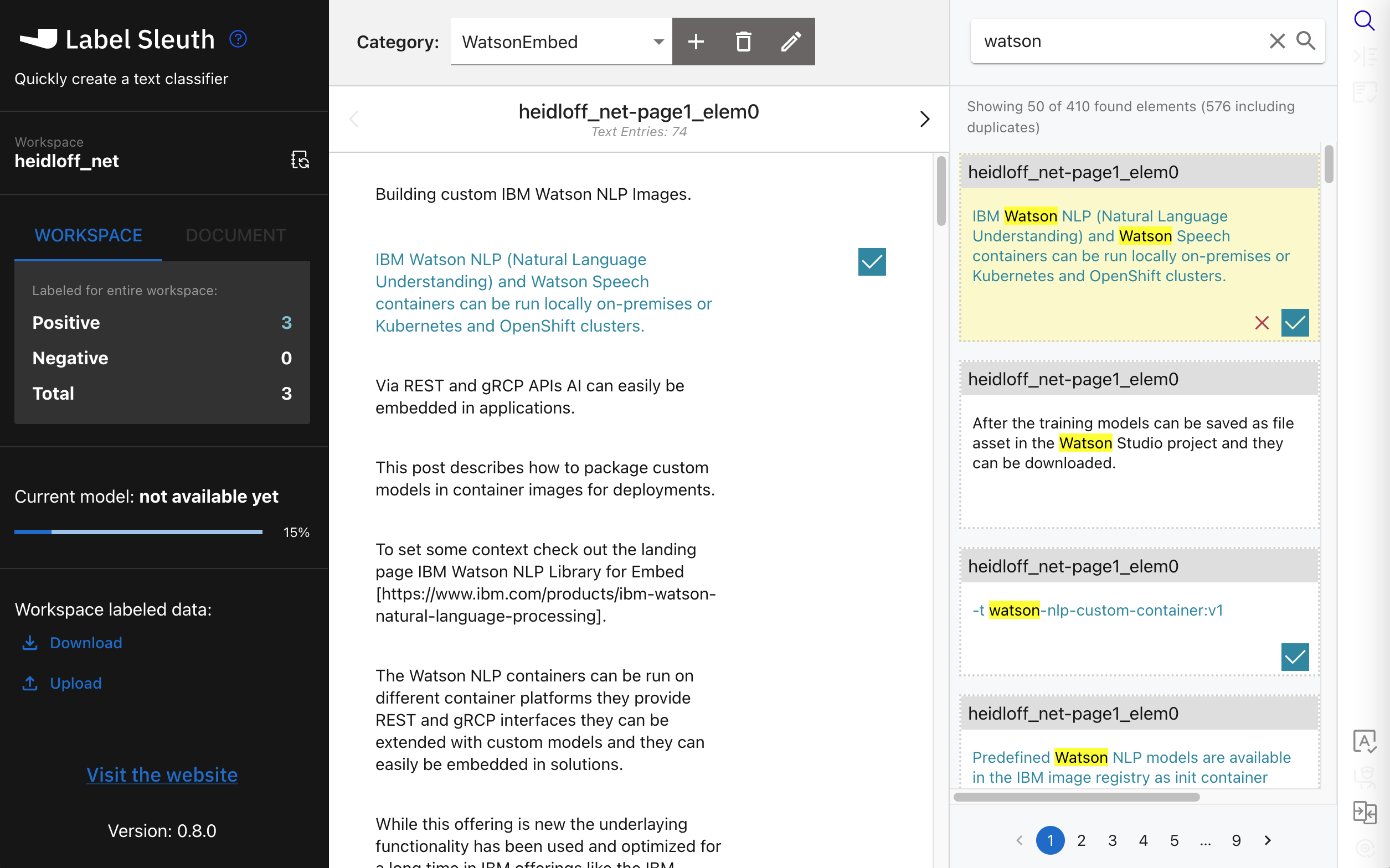
After you’ve labelled 20 sentences, a model is trained. This model is only used by the tool to provide suggestions what to label or verify next.
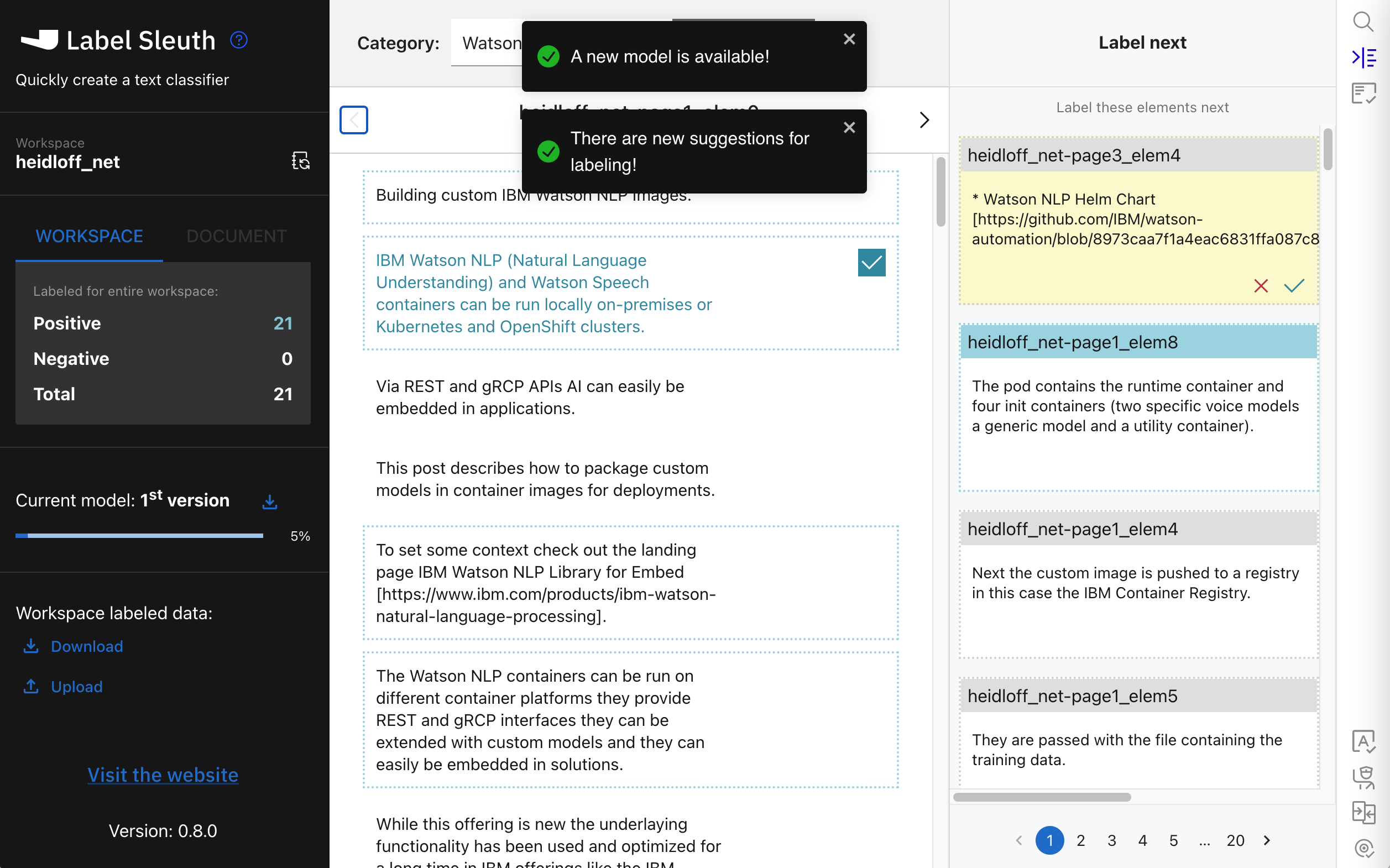
In the ‘Label next’ column, suggested sentences are displayed. The blue ones are suggested to be labelled as positive, the grey ones negative.
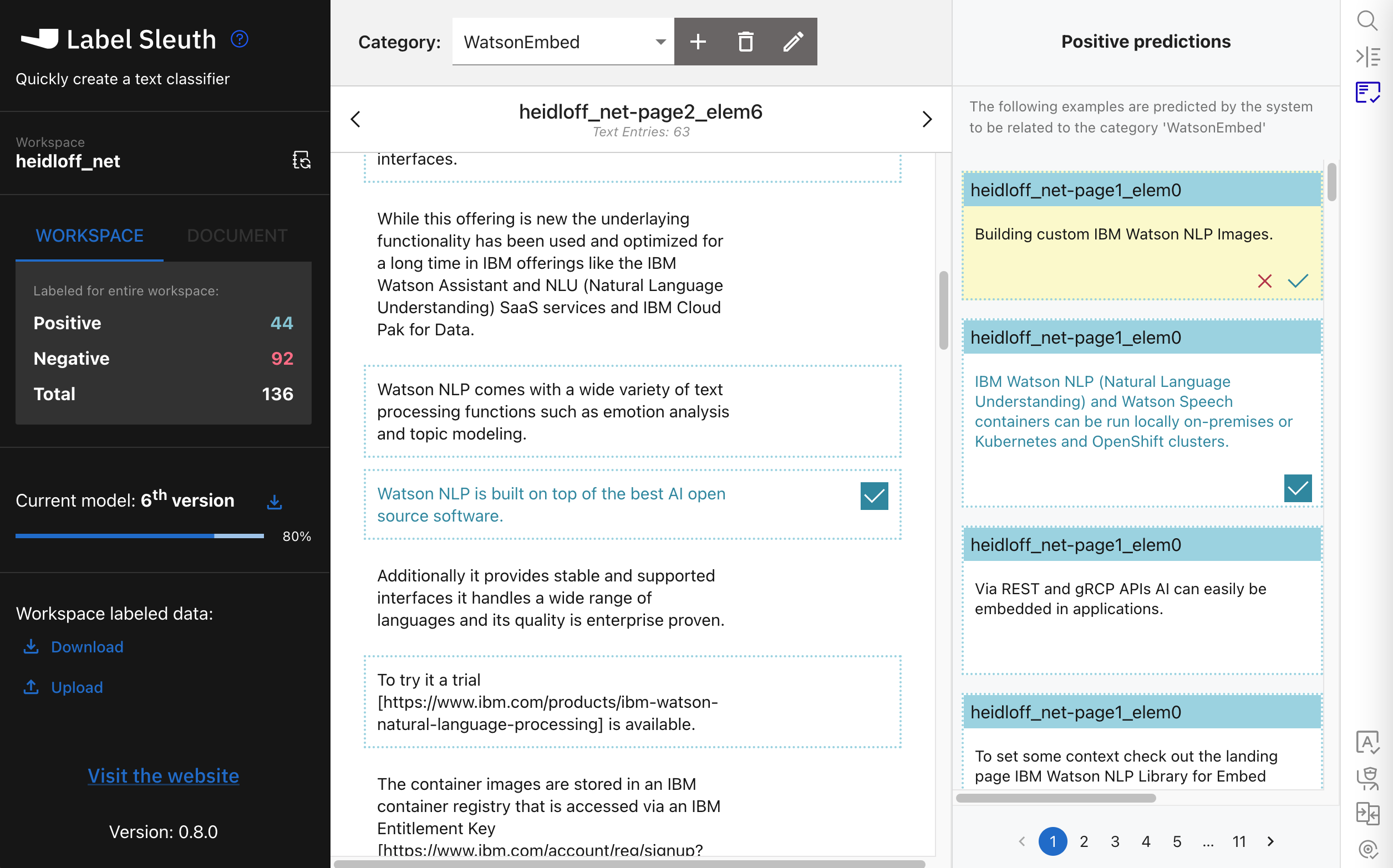
In the column ‘Positive predictions’ you can verify predictions from Label Sleuth. If they are wrong, it’s important to correct them since they are the most critical ones to improve the recall rate.
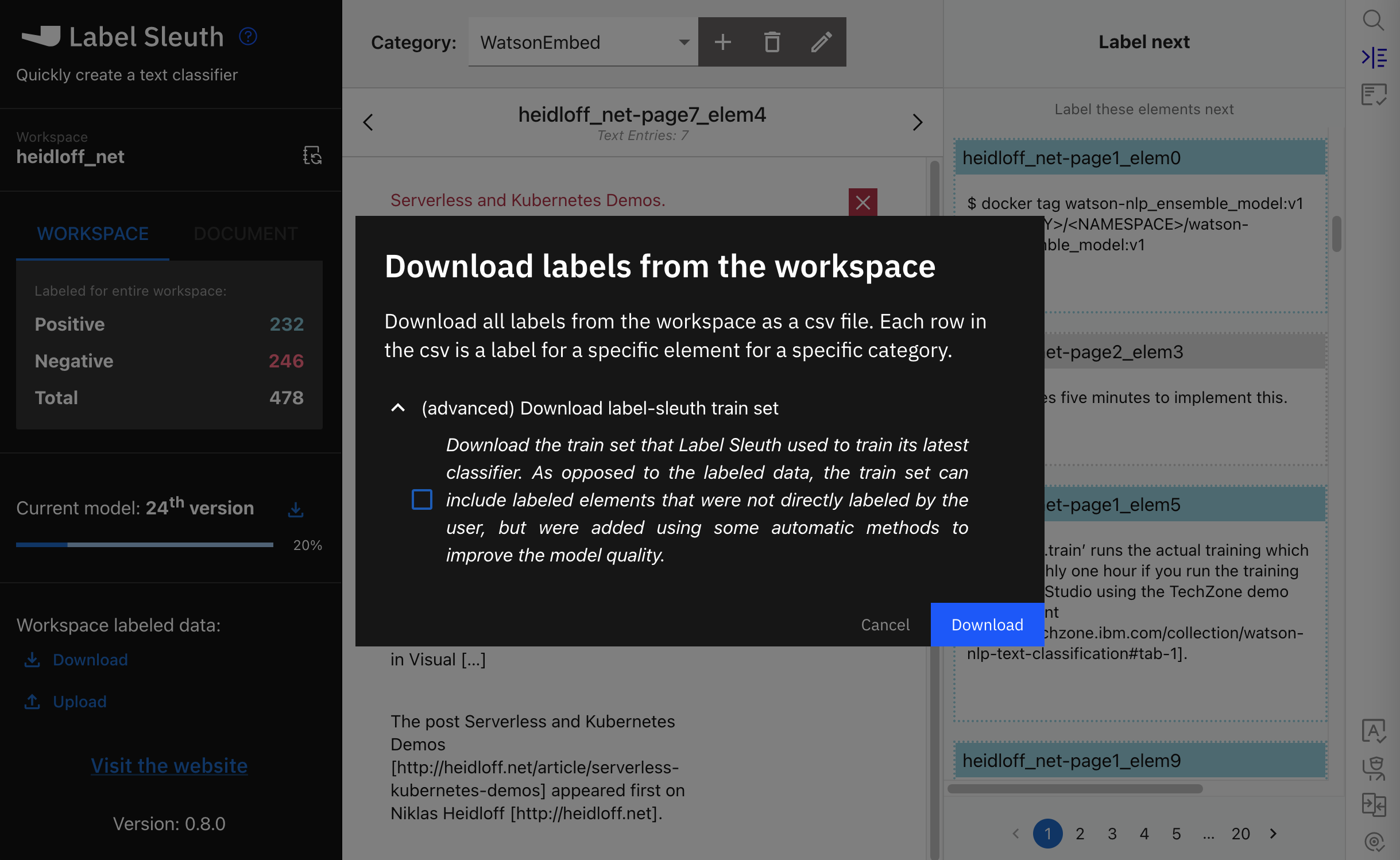
As more sentences are labelled Label Sleuth keeps training new models. You’ll notice that more and more sentences are predicted correctly. Once there are enough labels, the output can be downloaded as CSV file which will be the input for the later text classification model training.
What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.