
This post is part of a mini series which describes an AI text classification sample end to end using Watson NLP (Natural Language Understanding) and Watson Studio. This part explains how to deploy one pod to Kubernetes with the Watson NLP runtime container and two init containers containing the custom model and the syntax model.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Overview
Watson NLP can be deployed to Kubernetes environments like Minikube as one pod. The pod contains the Watson NLP runtime container and two additional init containers. The init containers contain custom or out of the box models and store them on a shared volume so that the runtime container can access them.
Architecture:
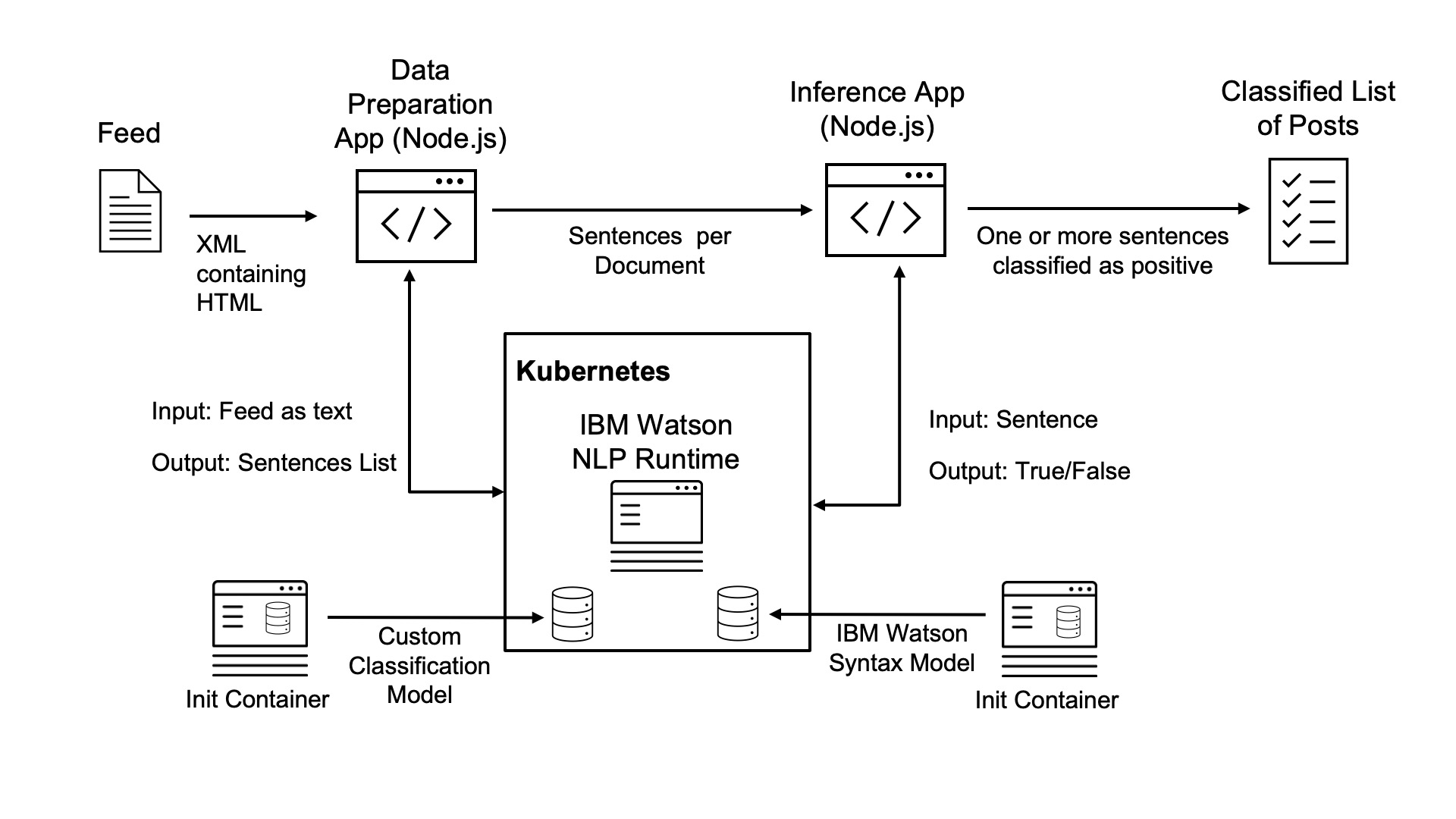
Walk-through
Let’s take a look how to deploy everything to Minikube. See the screenshots for a detailed walk-through.
With the watson-embed-model-packager tool custom images can be created with custom models.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ python3 -m venv client-env
$ source client-env/bin/activate
$ pip install watson-embed-model-packager
$ tree models
models
└── ensemble_model_heidloff
├── cnn_model
│ ├── ...
├── ...
├── ensemble_model
└── use_svm_model
$ python3 -m watson_embed_model_packager setup --library-version watson_nlp:3.2.0 --local-model-dir models --output-csv ./containers/heidloffblog/heidloffblog.csv
$ brew install minikube
$ minikube start --cpus 12 --memory 16000 --disk-size 50g
$ eval $(minikube -p minikube docker-env)
$ python3 -m watson_embed_model_packager build --config ./containers/heidloffblog/heidloffblog.csv
Minikube needs to be started with enough resources. Since I had issues pulling the large images, I used the following workaround. Usually the Watson NLP images are pulled from the IBM Cloud Pak registry and custom model images from a private enterprise registry.
1
2
3
4
5
6
7
8
9
10
11
$ brew install minikube
$ minikube start --cpus 12 --memory 16000 --disk-size 50g
$ eval $(minikube -p minikube docker-env)
$ docker login cp.icr.io --username cp --password <entitlement_key>
$ docker pull cp.icr.io/cp/ai/watson-nlp-runtime:1.0.18
$ docker pull cp.icr.io/cp/ai/watson-nlp_syntax_izumo_lang_en_stock:1.0.7
$ docker tag watson-nlp_ensemble_model_heidloff virtual/watson-nlp_ensemble_model_heidloff:0.0.1
$ docker images | grep watson-nlp
virtual/watson-nlp_ensemble_model_heidloff 0.0.1
cp.icr.io/cp/ai/watson-nlp-runtime 1.0.18
cp.icr.io/cp/ai/watson-nlp_syntax_izumo_lang_en_stock 1.0.7
Next a namespace is created and Watson NLP is deployed with the two models via Helm chart.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ kubectl create namespace watson-demo
$ kubectl config set-context --current --namespace=watson-demo
$ kubectl create secret docker-registry \
--docker-server=cp.icr.io \
--docker-username=cp \
--docker-password=<your IBM Entitlement Key> \
-n watson-demo \
ibm-entitlement-key
$ git clone https://github.com/cloud-native-toolkit/terraform-gitops-watson-nlp
$ cp ./containers/heidloffblog/values.yaml ../terraform-gitops-watson-nlp/chart/watson-nlp/values.yaml
$ cd terraform-gitops-watson-nlp/chart/watson-nlp
$ helm install -f values.yaml watson-embedded .
$ kubectl get pods -n watson-demo --watch
$ kubectl get deployment/watson-embedded-watson-nlp -n watson-demo
$ kubectl get svc/watson-embedded-watson-nlp -n watson-demo
$ kubectl port-forward svc/watson-embedded-watson-nlp 8080
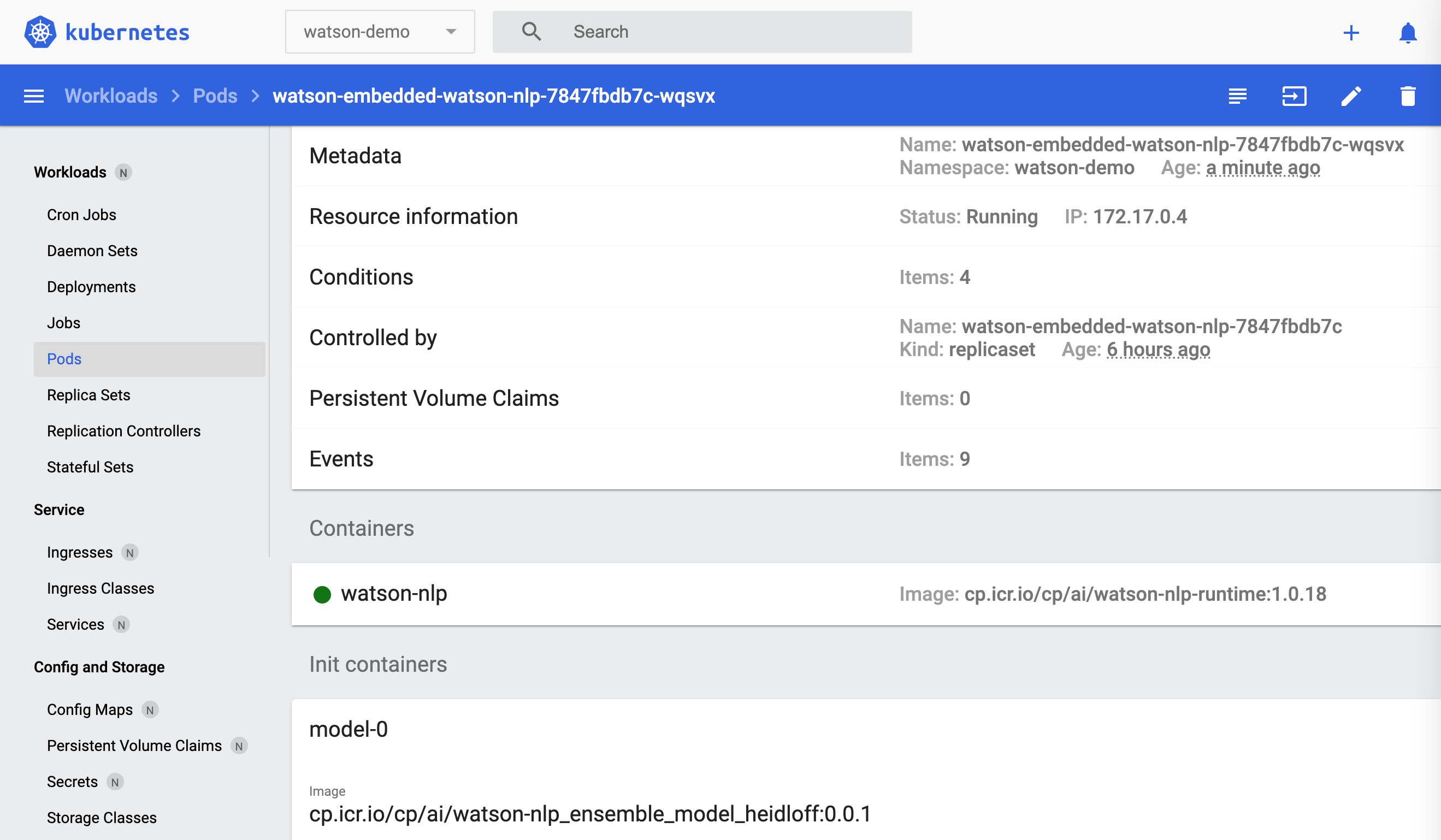
After this the REST APIs can be invoked to run predictions.
1
2
3
4
5
6
$ curl -s -X POST "http://localhost:8080/v1/watson.runtime.nlp.v1/NlpService/ClassificationPredict" \
-H "accept: application/json" \
-H "grpc-metadata-mm-model-id: ensemble_model_heidloff" \
-H "content-type: application/json" \
-d "{ \"rawDocument\": \
{ \"text\": \"The Watson NLP containers also provides a gRCP interface\" }}" | jq
What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.