
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. This post describes how to train a simple model for text classfication.
To set some context, check out the landing page IBM Watson NLP Library for Embed. The Watson NLP containers can be run on different container platforms, they provide REST and gRCP interfaces, they can be extended with custom models and they can easily be embedded in solutions. While this offering is new, the underlaying functionality has been used and optimized for a long time in IBM offerings like the IBM Watson Assistant and NLU (Natural Language Understanding) SaaS services and IBM Cloud Pak for Data.
To try it, a trial is available. The container images are stored in an IBM container registry that is accessed via an IBM Entitlement Key.
Training Watson NLP Models
Watson NLP comes with many predefined models that can either be re-used without any modifications or that can be customized and extended. One way to deploy Watson NLP is to deploy the Watson runtime container plus one init container per model. The init containers store their models in the same volume, so that the runtime container can access them. The runtime container provides REST and gRPC interfaces which can be invoked by applications to run predictions.
To train custom models, Watson Studio needs to be used at this point. Let’s take a look at a simple example. IBM provides a sample notebook to classify consumer complaints about financial products and services. This could be used, for example to route a complaint to the appropriate staff member. The data that is used in this notebook is taken from the Consumer Complaint Database that is published by the Consumer Financial Protection Bureau, a U.S. government agency.
Step 1: Import Libraries
First the Watson NLP library needs to be imported which is part of Watson Studio.
1
2
3
4
5
6
7
8
!pip install ibm-watson
import watson_nlp
...
from watson_core.data_model.streams.resolver import DataStreamResolver
from watson_core.toolkit import fileio
from watson_nlp.blocks.classification.svm import SVM
from watson_nlp.workflows.classification import Ensemble
from watson_core.toolkit.quality_evaluation import QualityEvaluator, EvalTypes
Step 2: Load Data
For convenience reasons, the data can be downloaded from Box. This is the original structure of the data.

Step 3: Clean up Data and prepare Training
The dataset is divided in training and test data.
1
2
3
4
# 80% training data
train_orig_df = train_test_df.groupby('Product').sample(frac=0.8, random_state=6)
# 20% test data
test_orig_df = train_test_df.drop(train_orig_df.index)
Unnecessary columns are dropped and columns are renamed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def prepare_data(df):
# only the text column and the target label *Product* are needed
df_out = df[['Consumer complaint narrative', 'Product']].reset_index(drop=True)
# rename to the identifiers expected by Watson NLP
df_out = df_out.rename(columns={"Consumer complaint narrative": "text", 'Product': 'labels'})
# the label column should be an array (although we have only one label per complaint)
df_out['labels'] = df_out['labels'].map(lambda label: [label,])
return df_out
train_df = prepare_data(train_orig_df)
train_file = './train_data.json'
train_df.to_json(train_file, orient='records')
test_df = prepare_data(test_orig_df)
test_file = './test_data.json'
test_df.to_json(test_file, orient='records')
test_df.explode('labels')
This is the resulting structure which can be used for the training.

Step 4: Train Model
In this example ensemble methods are applied which “use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone”. The following models are downloaded:
1
2
3
syntax_model = watson_nlp.load(watson_nlp.download('syntax_izumo_en_stock'))
use_model = watson_nlp.load(watson_nlp.download('embedding_use_en_stock'))
stopwords = watson_nlp.download_and_load('text_stopwords_classification_ensemble_en_stock')
The ensemble model depends on the syntax model and the GloVe and USE embeddings. They are passed with the file containing the training data. ‘Ensemble.train’ runs the actual training which takes roughly one hour, if you run the training in Watson Studio using the TechZone demo environment.
1
2
from watson_nlp.workflows.classification import Ensemble
ensemble_model = Ensemble.train(train_file, 'syntax_izumo_en_stock', 'embedding_glove_en_stock', 'embedding_use_en_stock', stopwords=stopwords, cnn_epochs=5)
Step 5: Evaluate Model
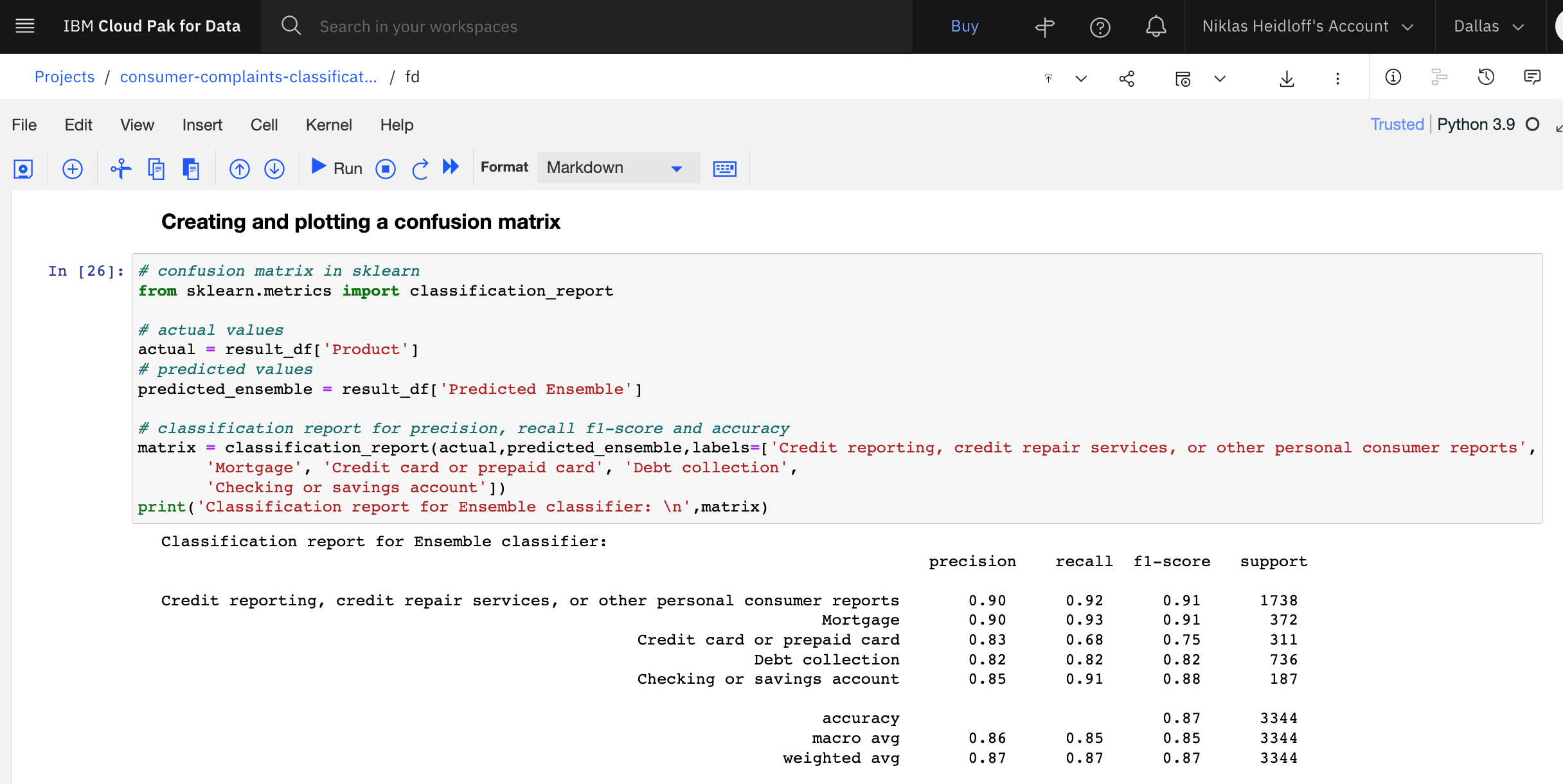
In the last step the trained model is evaluated by using the test dataset which was not part of the training.
To understand the results, you need to know what precision, recall and f1-score mean. Read the article How to measure an AI models performance or watch the video What is Precision, Recall, and F1-Score?.
Summary from the article:
- Precision can be thought of as a measure of exactness
- Recall can be thought of as a measure of completeness
- F1-score is a combination of Precision and Recall. A good F1 score means that you have low false positives and low false negatives
Accuracy is used when the True Positives and True negatives are more important while F1-score is used when the False Negatives and False Positives are crucial.
Here are the results:
To find out more about Watson NLP and Watson for Embed in general, check out these resources: