
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and WebSockets APIs AI can easily be embedded in applications. This post describes how to run Watson Text To Speech locally in Minikube.
To set some context, check out the landing page IBM Watson Speech Libraries for Embed.
The Watson Text to Speech library is available as containers providing REST and WebSockets interfaces. While this offering is new, the underlaying functionality has been used and optimized for a long time in IBM offerings like the IBM Cloud SaaS service for TTS and IBM Cloud Pak for Data.
To try it, a trial is available. The container images are stored in an IBM container registry that is accessed via an IBM Entitlement Key.
How to run TTS locally via Minikube
My post Running IBM Watson Text to Speech in Containers explained how to run Watson TTS locally in Docker. The instructions below describe how to deploy Watson Text To Speech locally to Minikube via kubectl and yaml files.
First you need to install Minikube, for example via brew on MacOS. Next Minikube needs to be started with more memory and disk size than the Minikube defaults. I’ve used the settings below which is more than required, but I wanted to leave space for other applications. Note that you also need to give your container runtime more resources. For example if you use Docker Desktop, navigate to Preferences-Resources to do this.
1
2
$ brew install minikube
$ minikube start --cpus 12 --memory 16000 --disk-size 50g
The namespace and secret need to be created.
1
2
3
4
5
6
7
8
$ kubectl create namespace watson-demo
$ kubectl config set-context --current --namespace=watson-demo
$ kubectl create secret docker-registry \
--docker-server=cp.icr.io \
--docker-username=cp \
--docker-password=<your IBM Entitlement Key> \
-n watson-demo \
ibm-entitlement-key
Clone a repo with the Kubernetes yaml files to deploy Watson Text To Speech.
1
2
3
$ git clone https://github.com/nheidloff/watson-embed-demos.git
$ kubectl apply -f watson-embed-demos/minikube-text-to-speech/kubernetes/
$ kubectl get pods --watch
To use other speech models, modify deployment.yaml.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- name: watson-tts-en-us-allisonv3voice
image: cp.icr.io/cp/ai/watson-tts-en-us-allisonv3voice:1.0.0
args:
- sh
- -c
- cp model/* /models/pool2
env:
- name: ACCEPT_LICENSE
value: "true"
resources:
limits:
cpu: 1
ephemeral-storage: 1Gi
memory: 1Gi
requests:
cpu: 100m
ephemeral-storage: 1Gi
memory: 256Mi
volumeMounts:
- name: models
mountPath: /models/pool2
When you open the Kubernetes Dashboard (via ‘minikube dashboard’), you’ll see the deployed resources. The pod contains the runtime container and four init containers (two specific voice models, a generic model and a utility container).
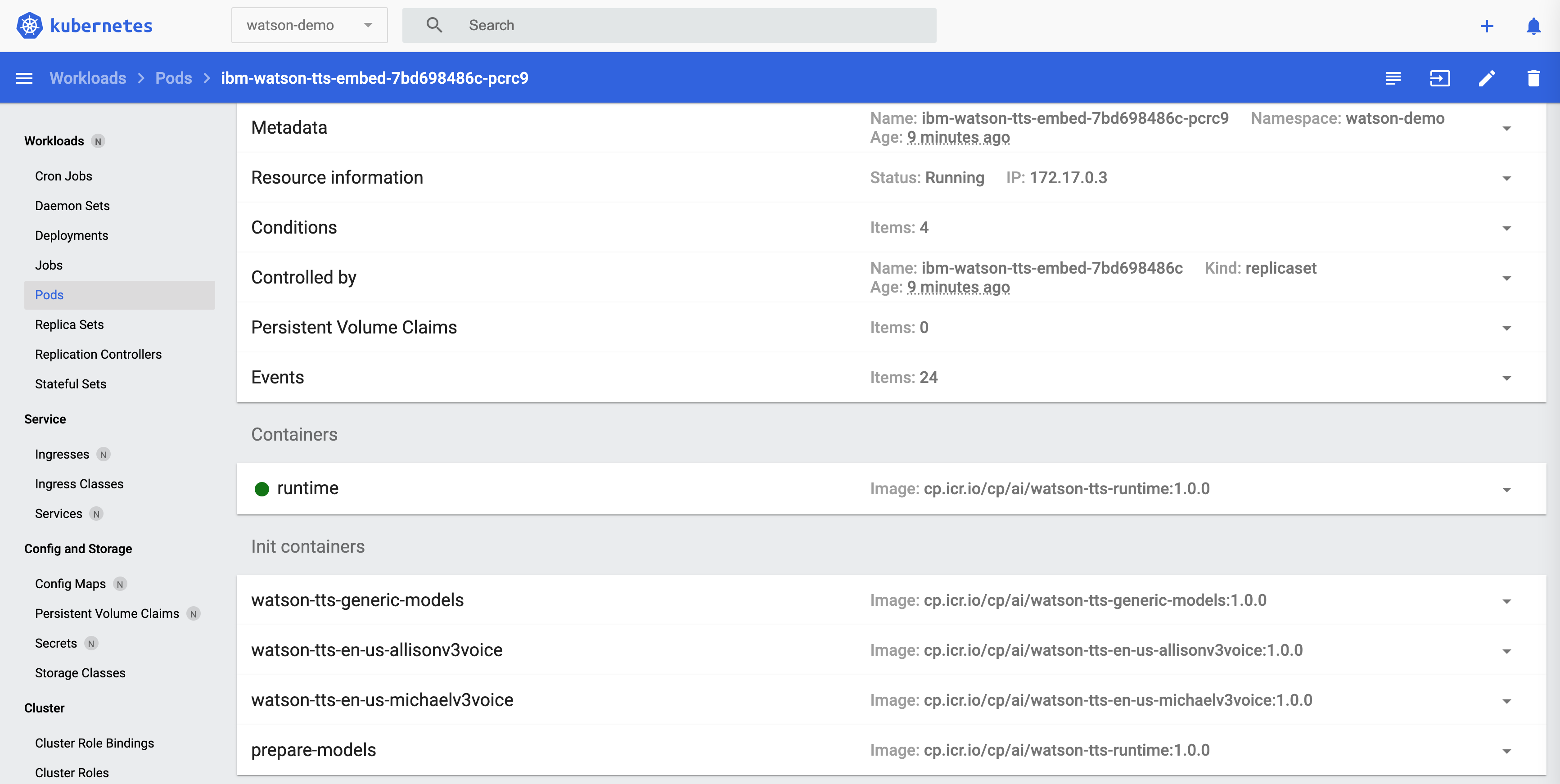
To invoke Watson Text To Speech, port forwarding can be used.
1
$ kubectl port-forward svc/ibm-watson-tts-embed 1080
The result of the curl command will be written to output.wav.
1
2
3
4
5
$ curl "http://localhost:1080/text-to-speech/api/v1/synthesize" \
--header "Content-Type: application/json" \
--data '{"text":"Hello world"}' \
--header "Accept: audio/wav" \
--output output.wav
To find out more about Watson Text To Speech and Watson for Embed in general, check out these resources:
- Watson Text To Speech Documentation
- Watson Text To Speech Model Catalog
- Watson Text To Speech SaaS API docs
- Trial
- Entitlement key
- Automation for Watson NLP Deployments
- Running IBM Watson NLP locally in Containers
- Running IBM Watson Speech to Text in Containers
- Running IBM Watson Text to Speech in Containers