
IBM announced the general availability of Watson NLP and Watson Speech containers which can be run locally, on-premises or Kubernetes and OpenShift clusters. This post describes how to run Speech to Text (STT) locally.
To set some context, here are the descriptions of IBM Watson Speech Libraries for Embed and the Watson Speech to Text library.
Build your applications with enterprise-grade speech technology: IBM Watson Speech Libraries for Embed are a set of containerized text-to-speech and speech-to-text libraries designed to offer our IBM partners greater flexibility to infuse the best of IBM Research technology into their solutions. Now available as embeddable AI, partners gain greater capabilities to build voice transcription and voice synthesis applications more quickly and deploy them in any hybrid multi-cloud environment.
Watson STT library uses natural language AI technology to understand the human voice and turn it into usable, searchable text. As an embeddable AI library, developers have greater access to the best of IBM Watson Speech technology and IBM Research algorithms to build voice transcription and voice synthesis applications faster: 1. Accuracy out-of-box with advanced training techniques. 2. Customization tools to tailor the models for your specific domain.
The Watson Speech to Text library is available as containers providing REST and WebSockets interfaces. While this offering is new, the underlaying functionality has been used and optimized for a long time in IBM offerings like the IBM Cloud SaaS service STT and IBM Cloud Pak for Data. STT is a speech recognition service that offers functionalities like text recognition, audio preprocessing, noise removal, background noise separation, semantic sentence conversation, and how many speakers are in conversions.
To try it, a trial is available. The container images are stored in an IBM container registry that is accessed via an IBM Entitlement Key.
How to run STT locally via Docker
To run STT as container, the container image needs to be built first. Different speech models are provided for different languages and different voices. There is a sample that describes how to run STT with two speech models locally.
In a first terminal execute these commands to build and run the container:
1
2
3
4
5
$ docker login cp.icr.io --username cp --password <entitlement_key>
$ git clone https://github.com/ibm-build-lab/Watson-Speech.git
$ cd Watson-Speech/single-container-stt
$ docker build . -t speech-standalone
$ docker run -e ACCEPT_LICENSE=true --rm --publish 1080:1080 speech-standalone
In second terminal invoke these commands to invoke a REST API:
1
2
3
4
$ cd Watson-Speech/single-container-stt
$ curl "http://localhost:1080/speech-to-text/api/v1/recognize" \
--header "Content-Type: audio/wav" \
--data-binary @sample_dataset/en-quote-1.wav
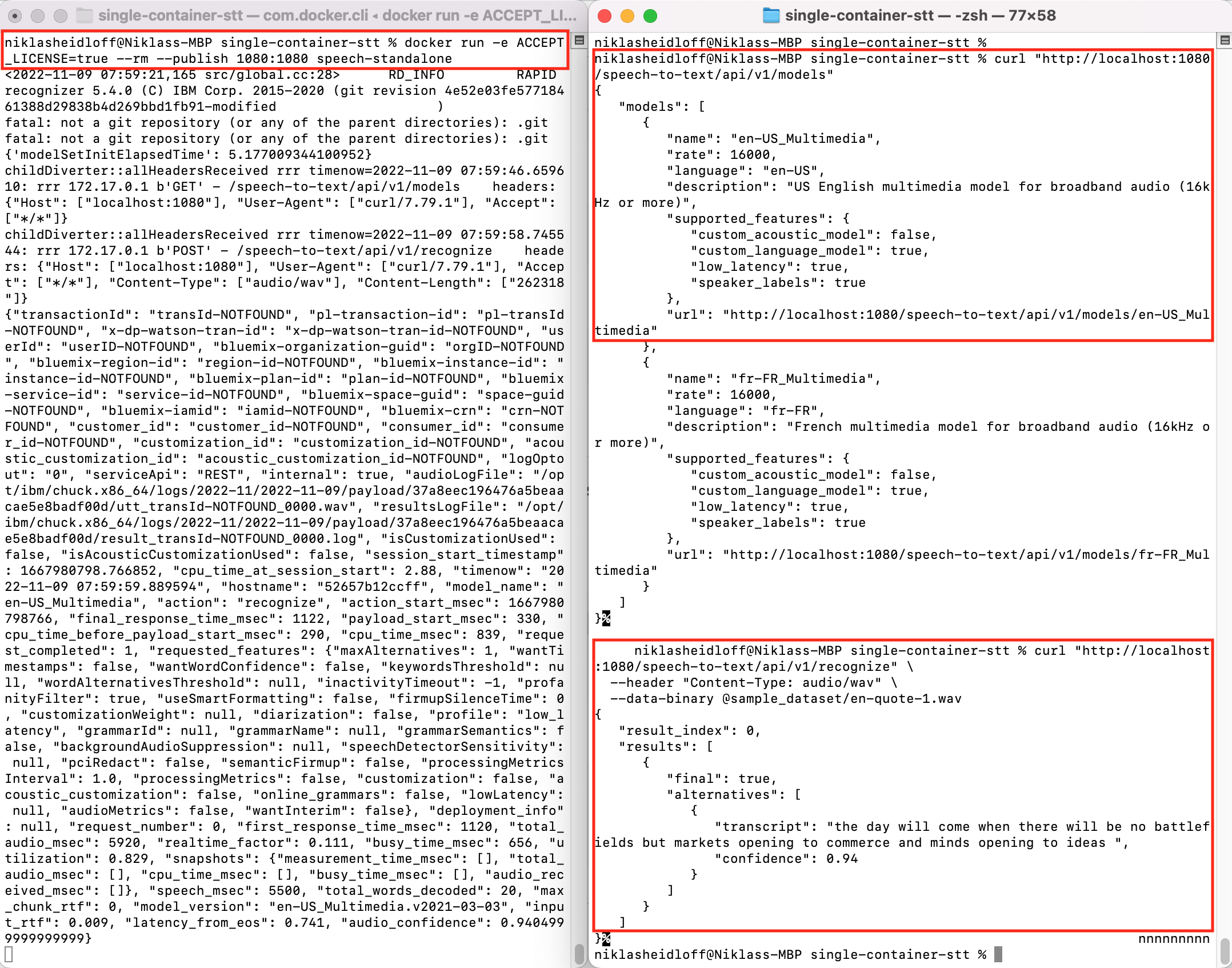
Here is a screenshot of the container in action:
To define which models you want to put in your image, a multi stage Dockerfile is used.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Model images
FROM cp.icr.io/cp/ai/watson-stt-generic-models:1.0.0 as catalog
# Add additional models here
FROM cp.icr.io/cp/ai/watson-stt-en-us-multimedia:1.0.0 as en-us-multimedia
FROM cp.icr.io/cp/ai/watson-stt-fr-fr-multimedia:1.0.0 as fr-fr-multimedia
# Base image for the runtime
FROM cp.icr.io/cp/ai/watson-stt-runtime:1.0.0 AS runtime
# Environment variable used for directory where configurations are mounted
ENV CONFIG_DIR=/opt/ibm/chuck.x86_64/var
# Copy in the catalog and runtime configurations
COPY --chown=watson:0 --from=catalog catalog.json ${CONFIG_DIR}/catalog.json
COPY --chown=watson:0 ./${LOCAL_DIR}/* ${CONFIG_DIR}/
# Intermediate image to populate the model cache
FROM runtime as model_cache
# Copy model archives from model images
RUN sudo mkdir -p /models/pool2
# For each additional models, copy the line below with the model image
COPY --chown=watson:0 --from=en-us-multimedia model/* /models/pool2/
COPY --chown=watson:0 --from=fr-fr-multimedia model/* /models/pool2/
# Run script to initialize the model cache from the model archives
COPY ./prepareModels.sh .
RUN ./prepareModels.sh
# Final runtime image with models baked in
FROM runtime as release
COPY --from=model_cache ${CONFIG_DIR}/cache/ ${CONFIG_DIR}/cache/
To find out more about Watson Speech to Text, check out these resources: