
This post is part of a mini series which describes an AI text classification sample end to end using Watson NLP (Natural Language Understanding) and Watson Studio. This part explains how to build images with Watson NLP and custom models and how to run predictions against the containers.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Overview
The custom image will contain the Watson NLP runtime, the custom classification model and the out of the box IBM Watson NLP Syntax model.
Architecture:
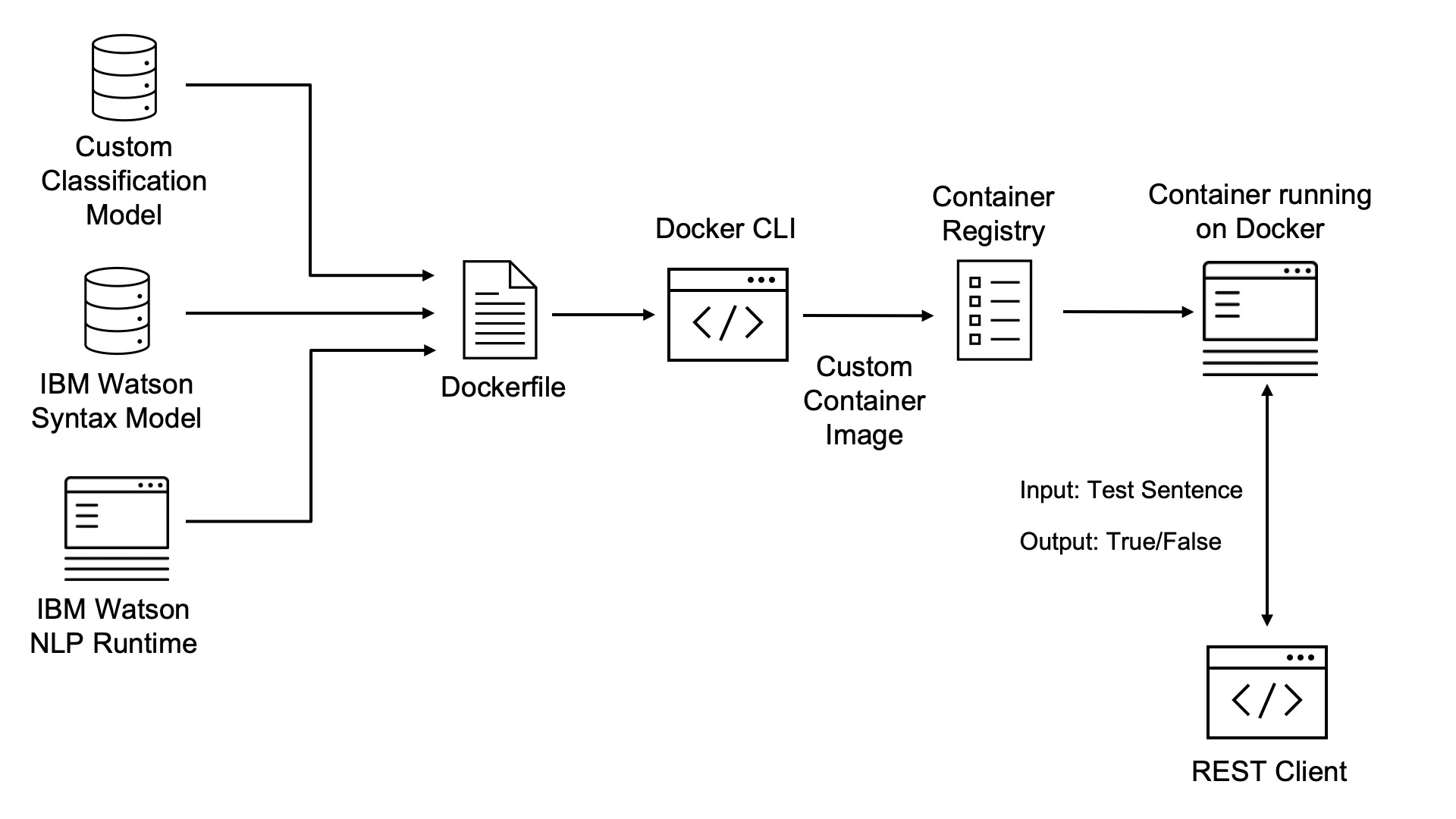
Walk-through
Let’s take a look how the image is built and the container is run. See the screenshots for a detailed walk-through.
The trained model is stored in the Watson Studio project.
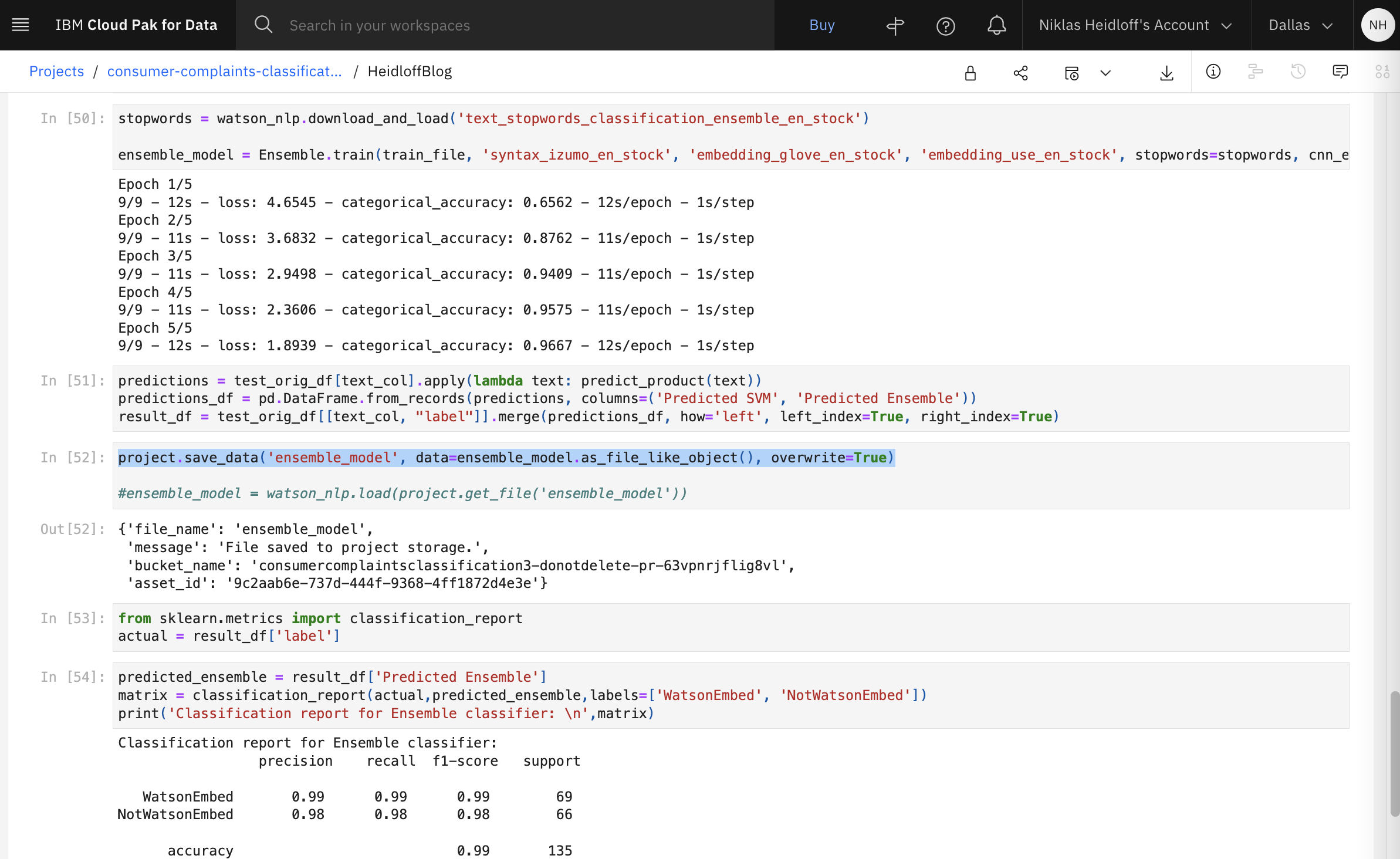
Download ensemble_model.zip to the directory ‘models’, rename it to ‘ensemble_model_heidloff.zip’, unzip it and delete it.
Run these commands to build the image. Make sure 1. the syntax model and 2. your ensemble_model_heidloff model are in the models directory.
1
2
3
$ docker login cp.icr.io --username cp --password <your-entitlement-key>
$ chmod -R 777 models/ensemble_model_heidloff
$ docker build . -f containers/Dockerfile -t watson-nlp-with-classification-model
Run the container locally via Docker:
1
2
3
4
5
$ docker run --name watson-nlp-with-classification-model --rm -it \
-e ACCEPT_LICENSE=true \
-p 8085:8085 \
-p 8080:8080 \
watson-nlp-with-classification-model
You can run predictions via curl:
1
2
3
4
5
6
$ curl -s -X POST "http://localhost:8080/v1/watson.runtime.nlp.v1/NlpService/ClassificationPredict" \
-H "accept: application/json" \
-H "grpc-metadata-mm-model-id: ensemble_model_heidloff" \
-H "content-type: application/json" \
-d "{ \"rawDocument\": \
{ \"text\": \"The Watson NLP containers also provides a gRCP interface\" }}" | jq

Alternatively you can run a Node.js app. Put xml file(s) in ‘data/heidloffblog/input/testing‘. There are some sample files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
$ cd data-prep-and-predictions
$ npm install
$ node predict.js heidloffblog ../data/heidloffblog/ watson-embed-containers.xml ensemble_model_heidloff
Article IS about WatsonEmbed since the confidence level of one sentence is above 0.8
The sentence with the highest confidence is:
IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally, on-premises or Kubernetes and OpenShift clusters.
{ className: 'WatsonEmbed', confidence: 0.9859272 }
$ node predict.js heidloffblog ../data/heidloffblog/ not-watson-embed-studio.xml ensemble_model_heidloff
Article IS NOT about WatsonEmbed since the confidence level of no sentence is above 0.8
The sentence with the highest confidence is:
For example IBM provides Watson Machine Learning to identify the best algorithm.
{ className: 'WatsonEmbed', confidence: 0.6762146 }

What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.