
Retrieval Augmented Generation (RAG) solutions like Question Answering are not easy to evaluate. This post summarizes some options with their pros and cons.
Question Answering solutions are more than only invoking one model. Documents need to be retrieved first, rerankers can help finding the most important information in documents, different Large Language Models can be utilized with different prompts, and more. To find the best possible combinations typically a lot of experiments need to be run. Results need to be tracked and they obviously need to be comparable which requires good metrics.
The goal is to automate as much as possible when running experiments. Metrics that can be created without human interactions are desirable. However, because of issues with some of these automated metrics, it often also makes sense to do human evaluations.
Ground Truth
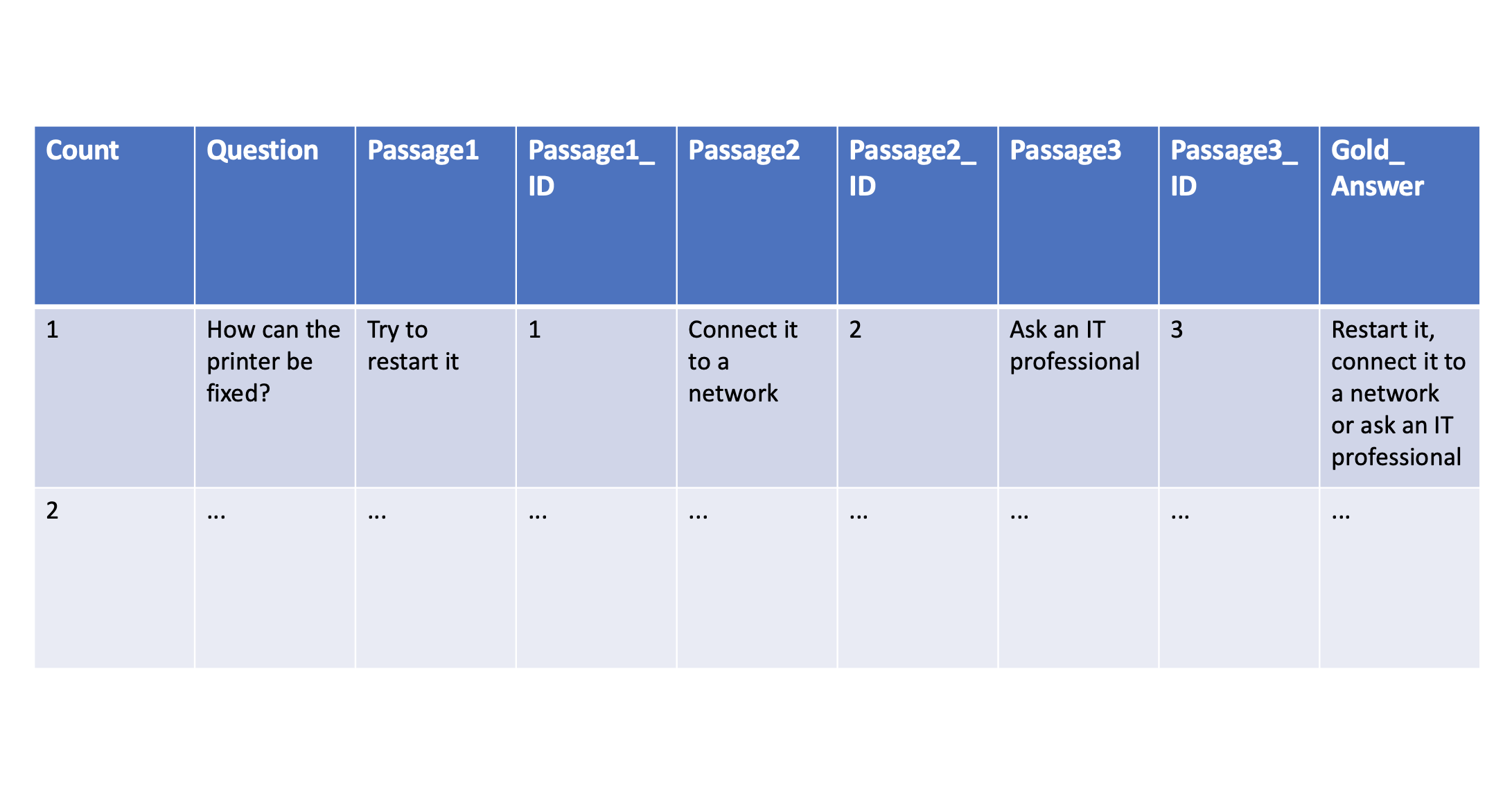
To measure the performance of different models and parameters, ground truth-based metrics can be leveraged. Experts for specific domains and data should provide at least 100 questions and expected answers, called ‘gold answers’. Read my previous post Generative AI for Question Answering Scenarios for details.
Since the answer generation pipelines contain multiple steps, not only the final answers should be measured but also whether the right documents or passages could be found in the earlier steps. In the graphic at the top of this post there are also columns for the top three passages/documents and their ids.
As straight forward as it might sound initially, checking whether the right documents could be found is sometimes not trivial. The same documents might have been indexed in different ways, they might sometimes include formatting information, they might not have the same ids anymore, there might be duplicates and often longer documents are split in smaller passages. In that case passages often overlap to some degree so that context information is not lost. In the best case the domain experts who define the ground truth document use the exact same passages that are passed into the large language model to create the answers.
Automated Metrics
There are many ways to measure the performance of Question Answering solutions, for example Bleu, Rouge, SBERT, NLI, and many more. Bleu and Rouge are easy to understand. Essentially, they compare how many words and chains of words are identical between the generated answers and the gold answers. I like this short definition from StackOverflow.
Bleu measures precision: how much the words (and/or n-grams) in the machine generated summaries appeared in the human reference summaries.
Rouge measures recall: how much the words (and/or n-grams) in the human reference summaries appeared in the machine generated summaries.
The lengths of the to be compared texts play an important role. For example, if a model only answers with ‘Yes’, it might lead to bad results in the metrics even if the answer is correct. To prevent this, mechanisms like brevity penalties are utilized.
Human Evaluations
Since the automated evaluations mentioned above, don’t cost anything, it makes sense to use them. They can help to compare different experiments with each other and can detect statistically different results.
However, human evaluations are still necessary. Golden answers provided by domain experts could include very different words compared to passages authored by the people who wrote them (for example, technical documentation writers). The answers might be much shorter, the domain experts might not be native speakers, they might like abbreviations for product names, etc. Experts can recognize and judge these differences which most automated solutions cannot detect.
Experts can also determine whether the answers are grounded in the information provided to the model. This is important to minimize hallucination as much as possible. In many cases the answer should be ‘I do not know’ (IDK), rather than allowing the model to provide answers from its memory or just coming up with something.
But there are also challenges with human evaluations. Obviously, they take a lot of time and cost money. It makes sense to identify the potentically best pipelines first and to do human evaluations on the most promising options.
Humans are human
While human evaluations are highly desirable, there are also limitations and things that should be considered when interpreting the results from experts.
- Experts have different preferences. Some might prefer short answers, other longer answers. Some might prefer summaries, others step by step instructions.
- Experts might even disagree on golden answers. Often there is no such thing like the one golden answer.
- If the same people need to evaluate very similar results in multiple stages, they might get bored and won’t spend the necessary time on this work.
- If the experts are supposed to provide gold answers, some might come up with something on their own, others simply copy and paste some text from the found documents.
- Experts do different levels of due diligence and have different skills.
- Experts are not always native speakers.
- Not all experts might follow the same instructions, for example how to rate answers for deviant questions.
Next Steps
It’s important to collect as much data as possible from the experts. Once enough annotations have been created on specific datasets, it might be possible to automate future evaluations based on the previous expert input.
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.