
This post describes the ‘Chain of Thought’ pattern for large language models. The technique is simple, but at the same time powerful to help AI models to understanding reasoning.
Some of my previous posts demonstrated the power of prompts and instructions-based fine-tuning. Good prompts and high-quality data in the right format required for fine-tuning can make a big difference.
Chain of Thought
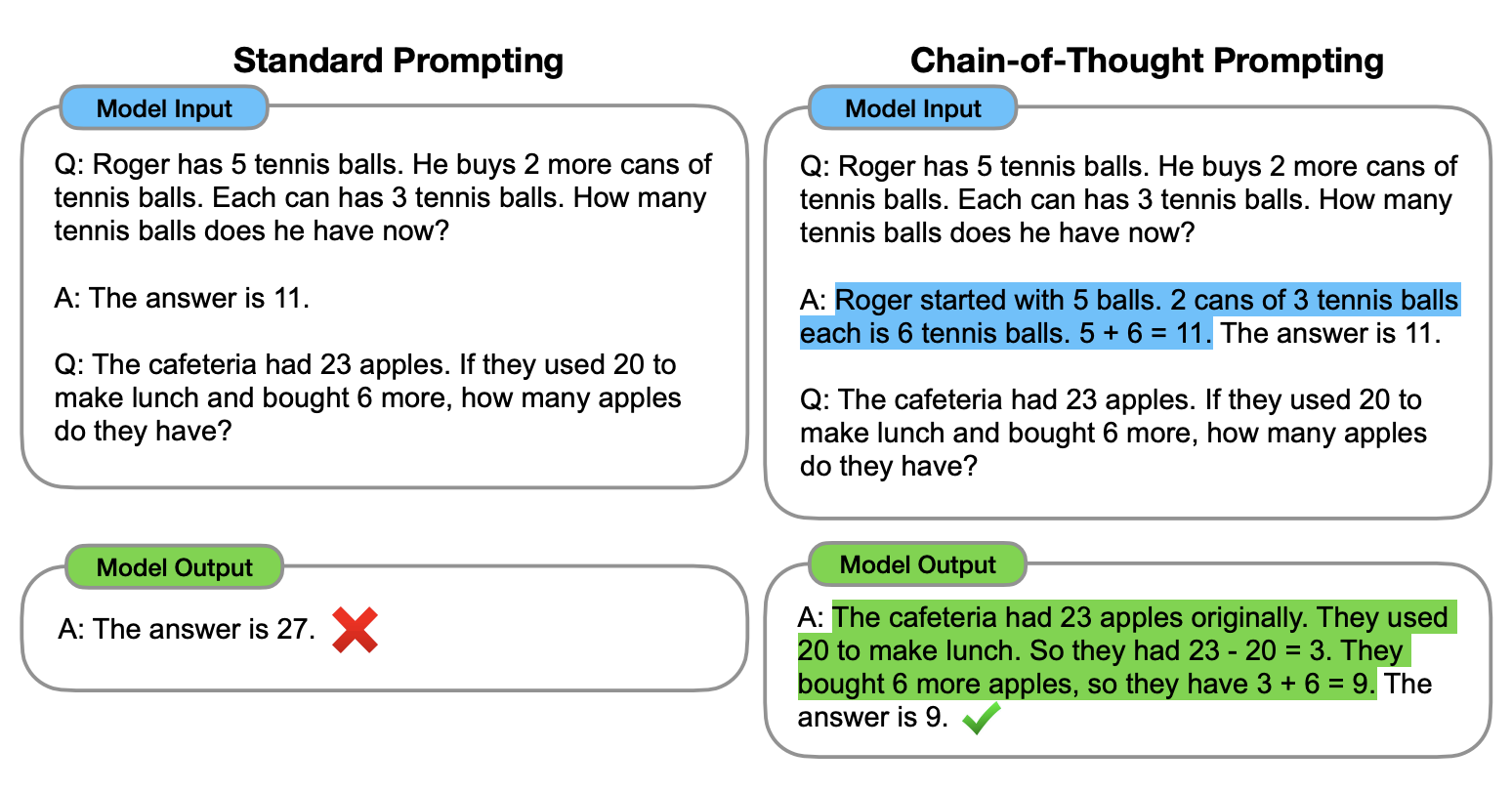
Let’s look at the sample at the top of this post which is from the paper Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. As always it helps to provide samples in the prompt (Few-Shot Prompting). While in the left column the right answer cannot be provided, the slightly different prompt in the right column supports the model to find the answer.
The trick is to define not only the answer in the sample, but also the chain of thought how the answer for the sample could be found. In this case the model is guided what to do for similar questions. Check out Learning Prompt for details.
Zero Shot Chain of Thought
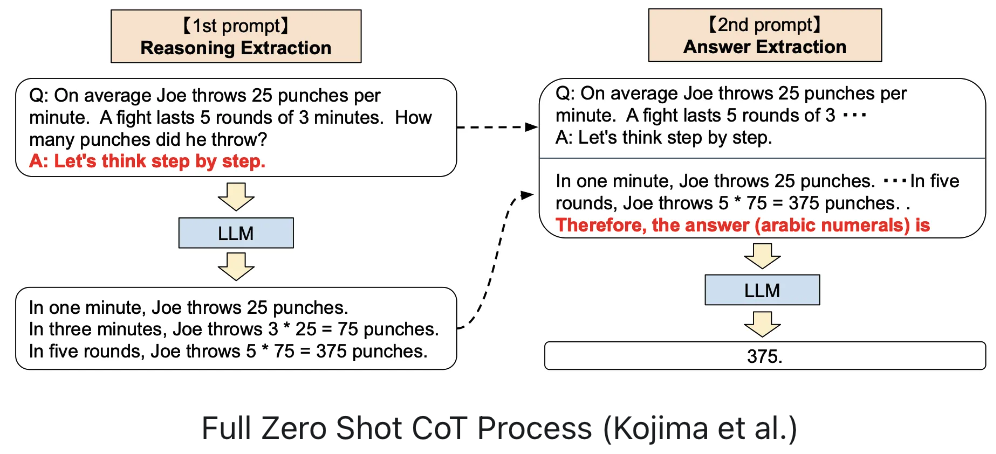
There is also a variation where no samples are utilized, called Zero Shot Chain of Thought. The (first) prompt is extended with an instruction “Let’s think step by step”.
Technically, the full Zero-shot-CoT process involves two separate prompts/completions. In the below image, the top bubble on the left generates a chain of thought, while the top bubble on the right takes in the output from the first prompt (including the first prompt itself), and extracts the answer from the chain of thought. This second prompt is a self augmented prompt.
Tree of Thoughts
In May the paper Tree of Thoughts: Deliberate Problem Solving with Large Language Models was published which goes one step further.
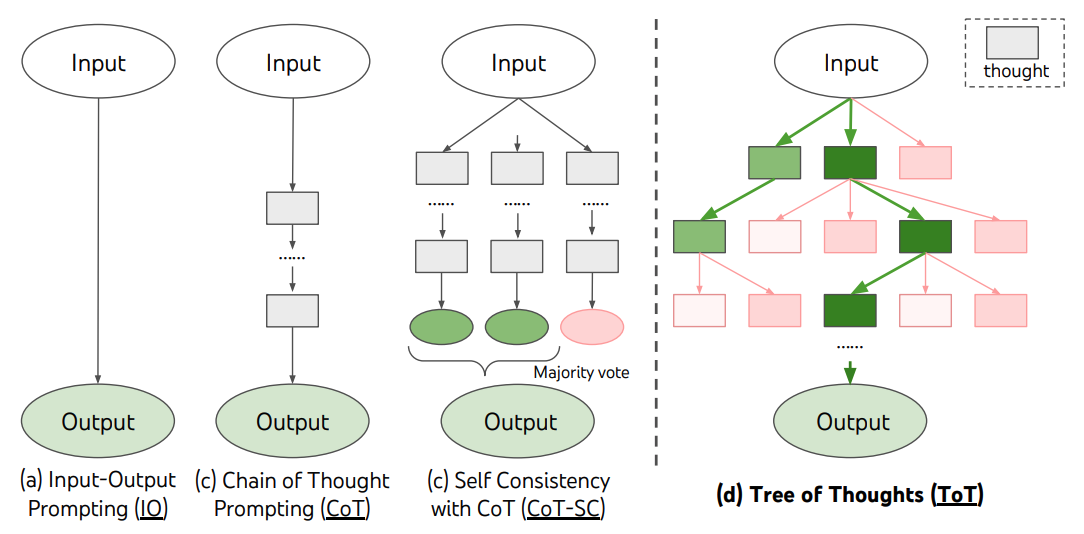
Tree-of-Thought improves prompting of large language models (LLMs) by generalizing the concept of Chain-of-Thought prompting and introduces a tree search across language model thoughts, including state evaluation and backtracking. Experiments on toy tasks show large improvements over both classic and Chain-of-Thought prompting.
LLMs (especially decoders) focus on generating text, token by token. When they start generating answers, they don’t know how to end. They might go down a wrong path when choosing next words (e.g. via greedy decoding) and they don’t have a way to recover. But after they have generated text, they can be asked whether their own answers make sense, so that they can correct themselves.
This mechanism is what Tree of Thoughts leverages. It also uses Chain of Thought but it lets the model create multiple first potential thoughts (in the chain of thoughts) from which it picks itself the best one. After it has found the best first thought, it produces alternatives for the next thoughts. This ‘thinking’ takes time as it does for humans as well. The model is invoked multiple times and weak answers are ignored.
I like this video which explains the concept well.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.