
There are different ways to train and tune LLM models. This post summarizes some interesting findings from a research paper whether prompts can change the behavior of models.
There are several options to optimize Large Language Models:
- Pre-training
- Classic fine-tuning by changing all weights
- LoRA fine-tuning by changing only a few weights
- Prompt engineering by providing samples
An important question is which of these options is the most effective one and which one can overwrite previous optimizations. This post focusses on whether prompts can overwrite trained and tuned models via a technique called In-Context Learning.
Challenges
Fine-tuning models can certainly help to get models to do what you want them to do. However, there are some potential issues:
- Catastrophic forgetting: This phenomenon describes a behavior when fine-tuning or prompts can overwrite the pre-trained model characteristics.
- Overfitting: If only a certain AI task has been fine-tuned, other tasks can suffer in terms of performance.
In general, fine-tuning should be used wisely and best practices should be applied, for example, the quality of the data is more important than the quantity and multiple AI tasks should be fine-tuned at the same time vs after each other.
In-Context Learning
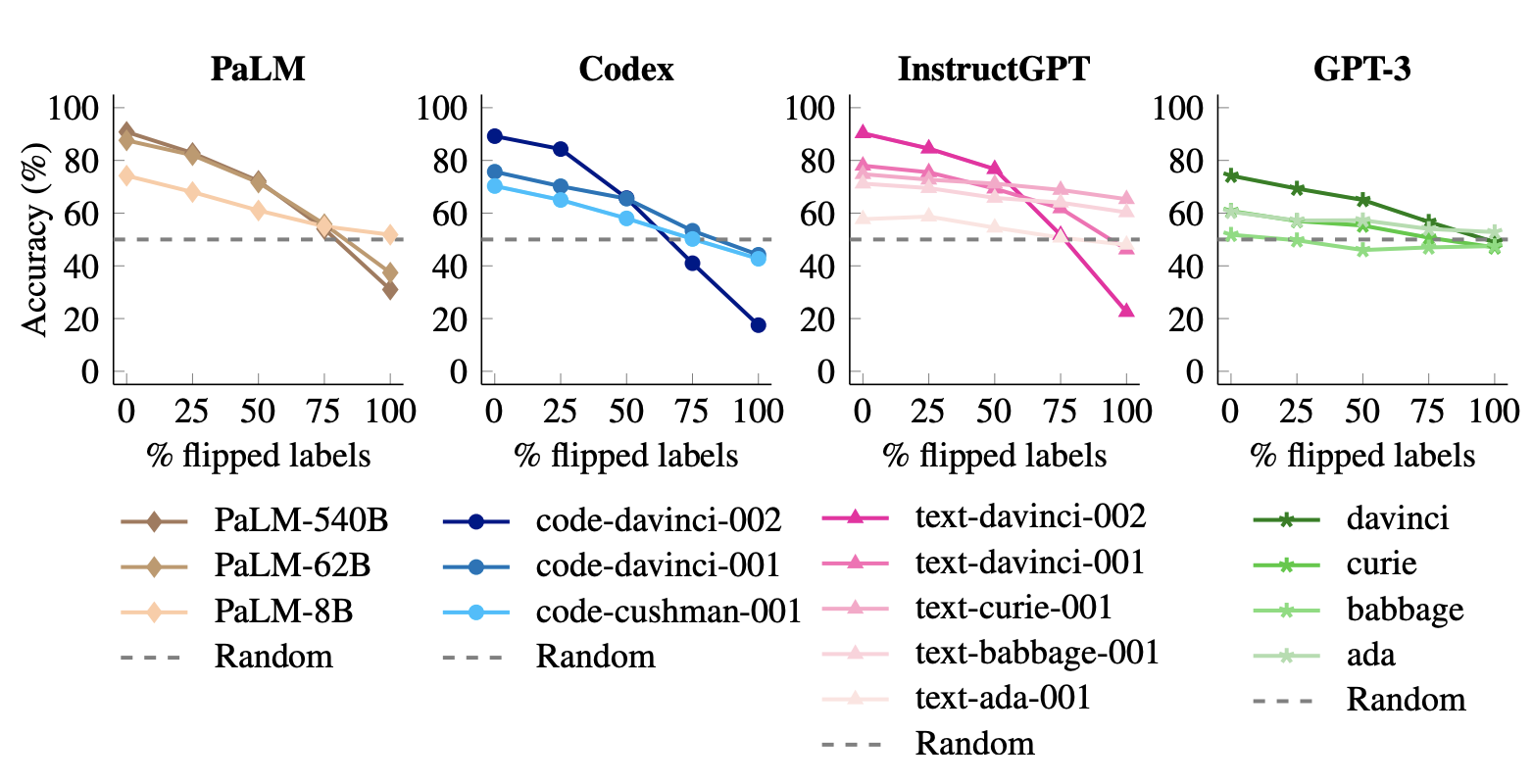
The authors of the paper Larger Language Models do In-context Learning differently ran some interesting experiments. To find out how much prompts can influence the behavior of trained and fine-tuned models, they used a Flipped-Label approach. For example, they told the models in the prompts that ‘positive’ really means ‘negative’ or that ‘sun’ really means ‘stone’. Via this technique they could figure out whether the pretrained and potentially fine-tuned behavior is stronger or the prompts.
These results indicate that large models can override prior knowledge from pretraining with input–label mappings presented in-context. […] ability to override prior knowledge with input–label mappings only appears in large models
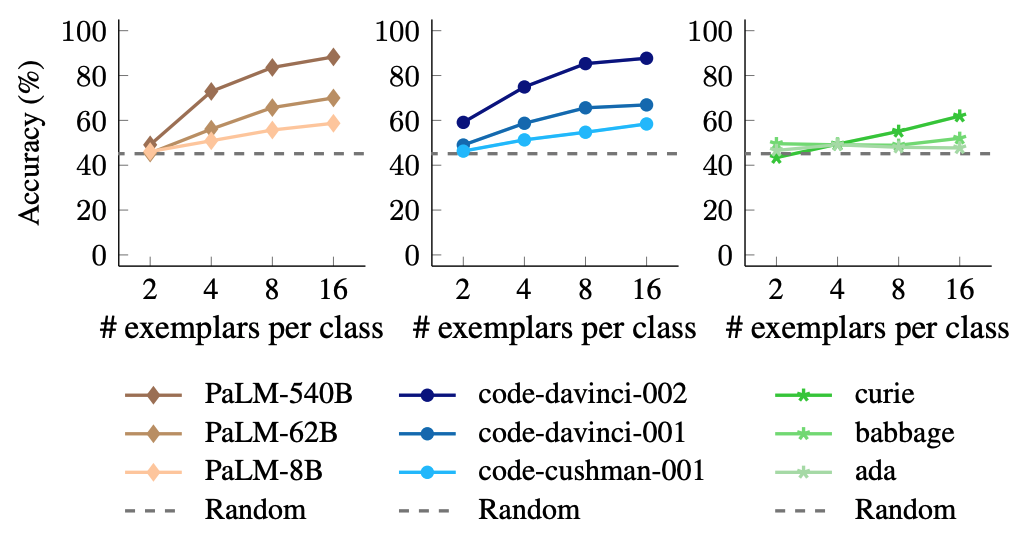
Interestingly, only a few samples in the prompts are necessary to overwrite the out of the box model behavior for larger models. The dark brown and dark blue lines are from the largest models.
Summary
There is not the one right way to optimize models. Instead, different approaches need to be evaluated and compared.
There are other publications that state that some already fine-tuned models like FLAN cannot be overwritten by prompts that easily.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.