
This post is part of a mini series which describes an AI text classification sample end to end using Watson NLP (Natural Language Understanding) and Watson Studio. This part explains how to convert XML RSS feeds into one CSV with a list of all sentences.
IBM Watson NLP (Natural Language Understanding) containers can be run locally, on-premises or Kubernetes and OpenShift clusters. Via REST and gRCP APIs AI can easily be embedded in applications. IBM Watson Studio is used for the training of the model.
The code is available as open source in the text-classification-watson-nlp repo.
Here are all parts of the series:
- Introduction: Text Classification Sample for IBM Watson NLP
- Step 1: Converting XML Feeds into CSVs with Sentences
- Step 2: Labelling Sentences for Text Classifications
- Step 3: Training Text Classification Models with Watson NLP
- Step 4: Running Predictions against custom Watson NLP Models
- Step 5: Deploying custom Watson NLP Text Classification Models
Overview
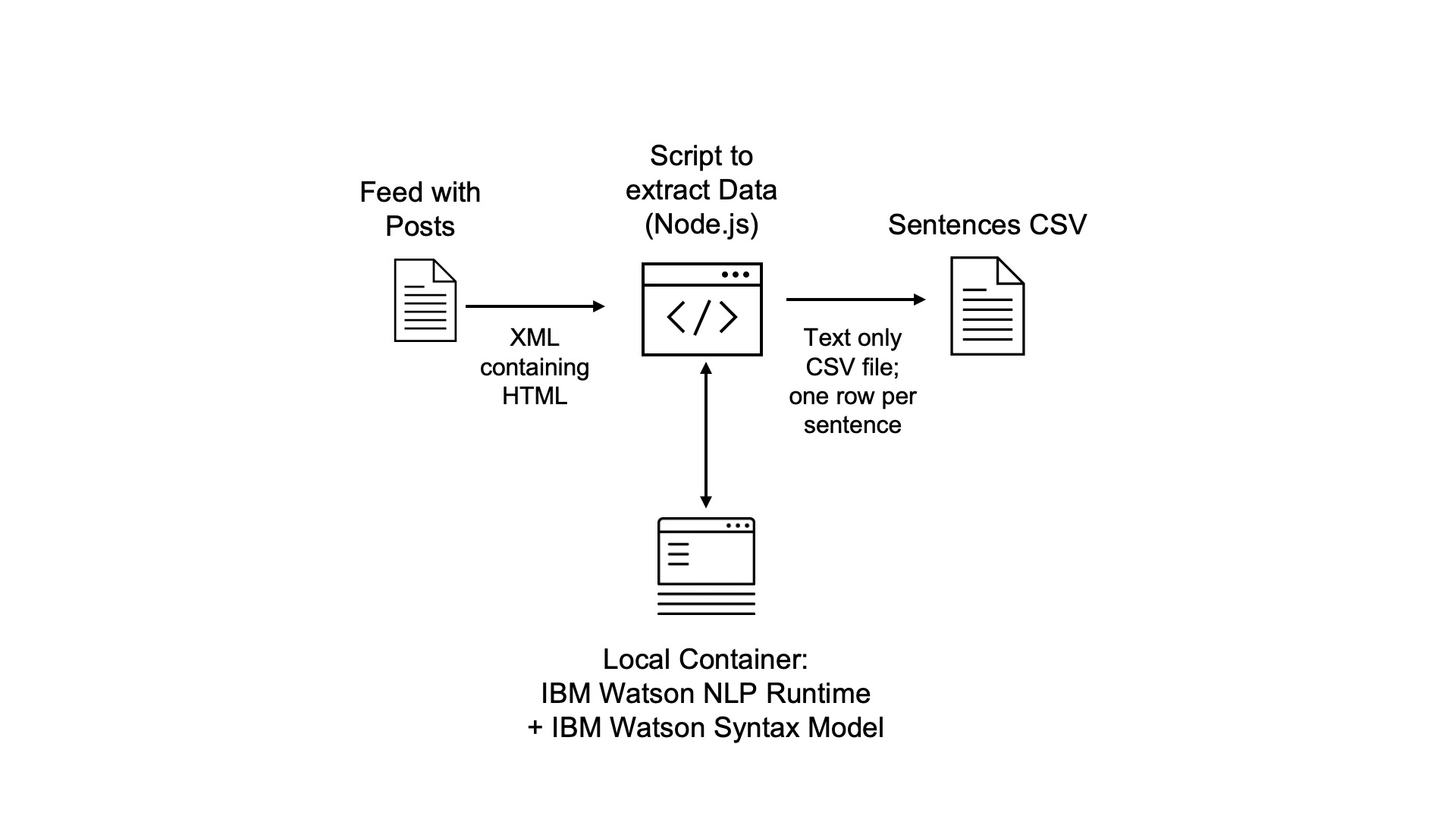
Before data can be labelled and the model can be trained, the data needs to be prepared. I’ve implemented some JavaScript code that does this automatically. The data is read from my blog and converted into a CSV file with a list of sentences for all blog posts. See the screenshots for a walk-through.
Architecture:
Step 1: Copy Blog Data into Repo
The original data from the blog is located in data/heidloffblog/input/feed-pages. The data was read via RSS feeds ‘http://heidloff.net/feed/?paged=1’ and copied manually into the repo.
Step 2: Split each Blog Post into separate File
There are 8 pages with 80 posts. The split script splits each page in 10 elements stored in data/heidloffblog/input/training.
1
2
3
$ cd data-prep-and-predictions
$ npm install
$ node splitFeedPagesInElements.js
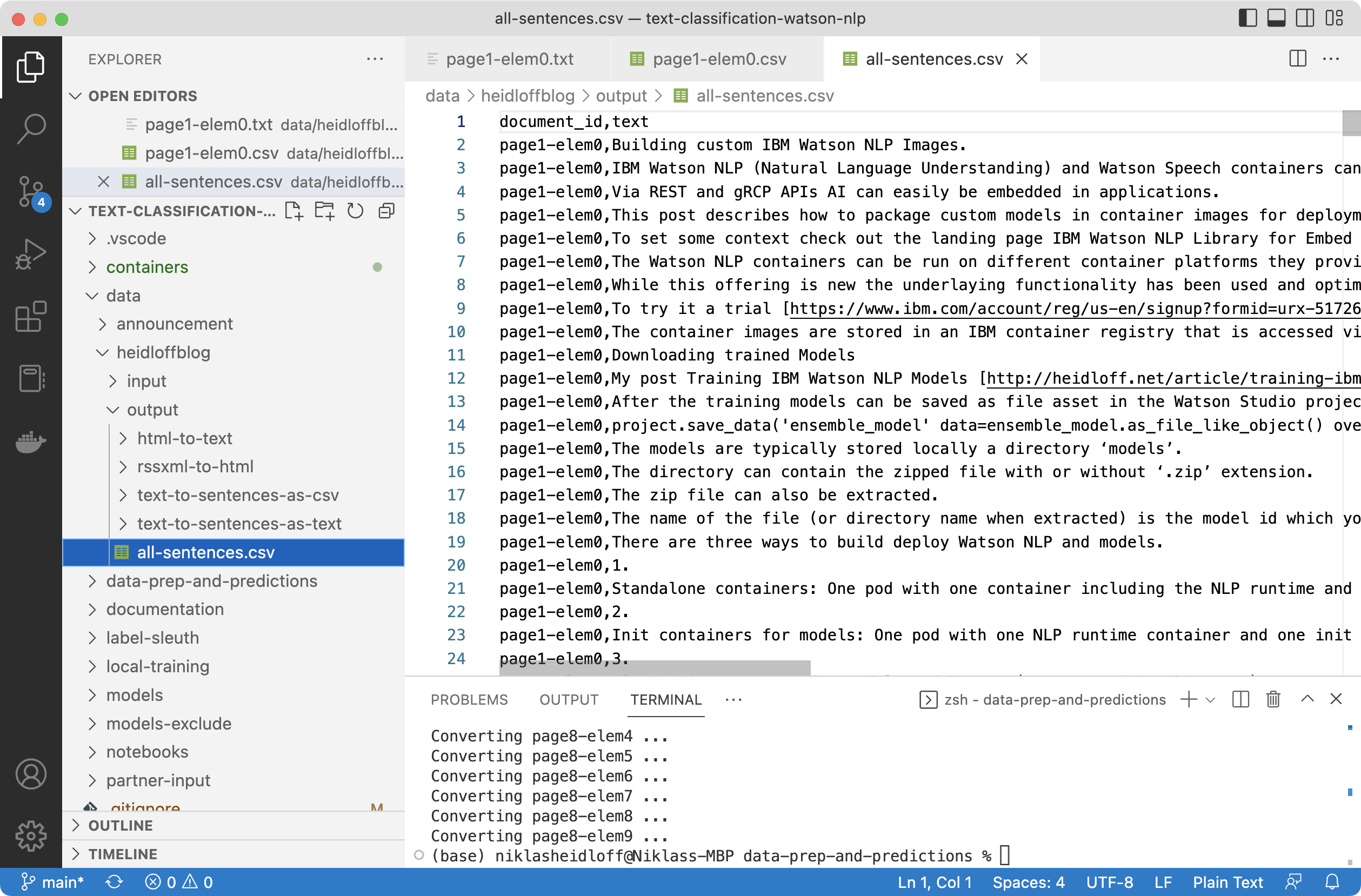
Step 3: Generate CSV File
Next the data needs to be converted in multiple steps:
This is the structure of the generated CSV file:
1
2
3
4
5
document_id,text
page1-elem0,Building custom IBM Watson NLP Images.
page1-elem0,IBM Watson NLP (Natural Language Understanding) and Watson Speech containers can be run locally on-premises or Kubernetes and OpenShift clusters.
page1-elem1,Understanding IBM Watson Containers.
page1-elem1,Via REST and gRCP APIs AI can easily be embedded in applications.
For the conversions to HTML and text open source JavaScript modules are used. For identifying sentences Watson NLP is used with the syntax stock model.
To try IBM Watson NLP, a trial is available. The container images are stored in an IBM container registry that is accessed via an IBM Entitlement Key.
Run Watson NLP with Docker locally:
1
2
3
4
5
6
7
8
9
$ docker login cp.icr.io --username cp --password <your-entitlement-key>
$ mkdir models
$ docker run -it --rm -e ACCEPT_LICENSE=true -v `pwd`/models:/app/models cp.icr.io/cp/ai/watson-nlp_syntax_izumo_lang_en_stock:1.0.7
$ docker build . -f containers/Dockerfile -t watson-nlp-with-syntax-model:latest
$ docker run --rm -it \
-e ACCEPT_LICENSE=true \
-p 8085:8085 \
-p 8080:8080 \
watson-nlp-with-syntax-model
When Watson NLP is running, the following commands create the CSV file.
1
2
3
$ cd data-prep-and-predictions
$ npm install
$ node convert.js heidloffblog ../data/heidloffblog/
What’s next?
Check out my blog for more posts related to this sample or get the code from GitHub. To learn more about IBM Watson NLP and Embeddable AI, check out these resources.