
Quarkus supports imperative as well as reactive programming styles. In this article I compare access times to Postgres from Java based microservices developed with Quarkus. For synchronous invocations Panache is used, for asynchronous access Vert.x Axle.
I’ve created a sample application that comes with the cloud-native-starter project. The ‘articles’ microservice accesses the database running in Kubernetes. To keep the scenario simple, only one REST API is tested which reads articles from Postgres.
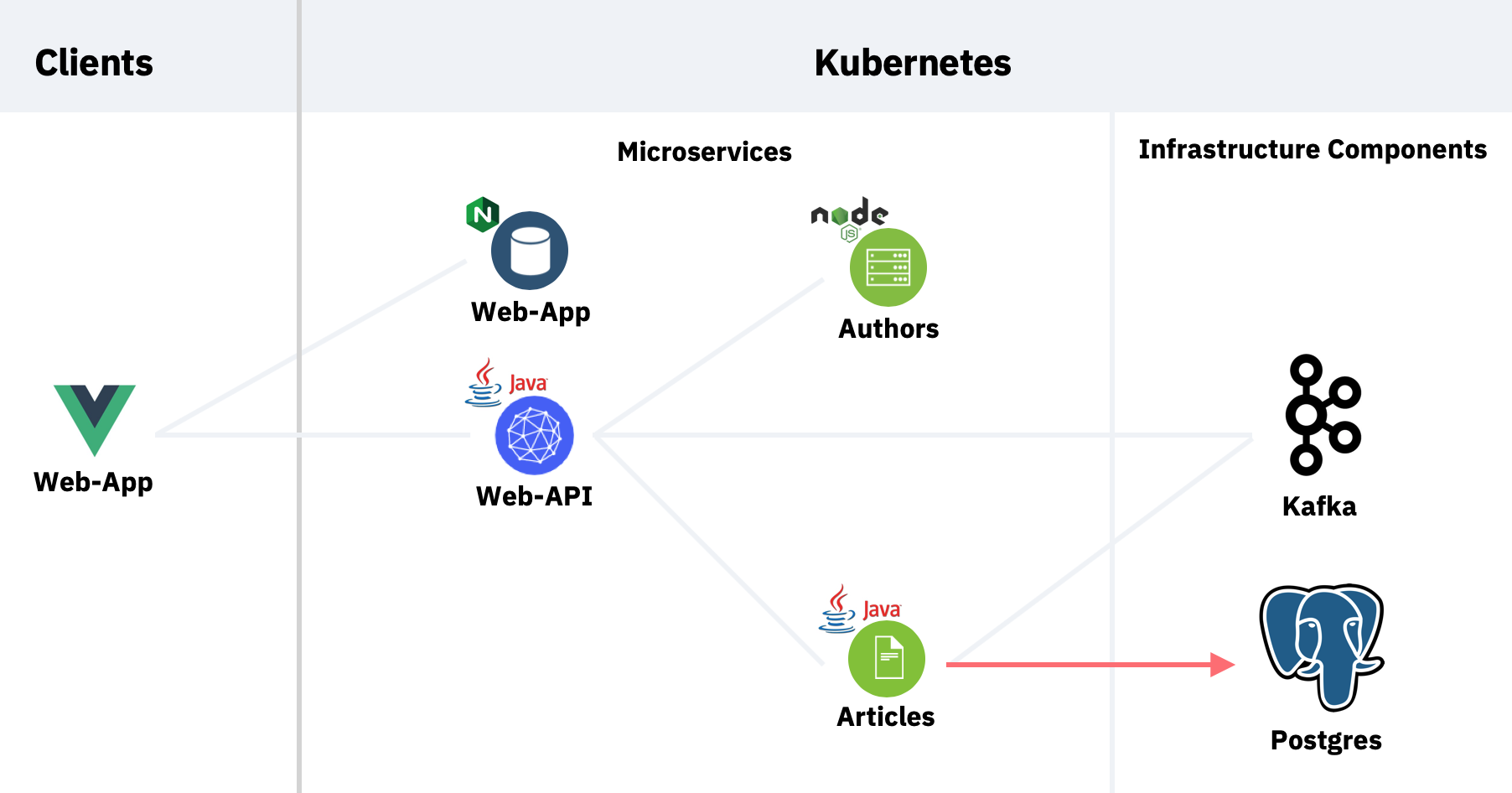
There are two implementations of the articles service:
- Imperative/synchronous: The REST endpoint has been implemented with JAX-RS (synchronous). The service reads articles from Postgres via Panache (see Quarkus guide Simplified Hibernate ORM with Panache).
- Reactive/asynchronous: The REST endpoint has been implemented with Vert.x, CompletionStage and CompletableFuture asynchronously. The service reads articles asynchronously from Postgres via Vert.x Axle (see Quarkus guide Reactive SQL Clients).
The reactive stack of this sample provides response times that take less than half of the time compared to the imperative stack: Reactive: 142 ms (0:42 min total) – Imperative: 265 ms (1:20 min total). Check out the documentation for details.
While this scenario is not necessarily representative, I think it demonstrates nicely the efficiency of reactive programming.
I’ve run a second performance test where a more complete cloud-native application is tested. Check out the documentation.
Synchronous Access via Panache
Panache is basically an extension of JPA which makes persistence really easy. After you’ve defined the dependencies and the configuration in application.properties, you can define the entity (see code):
1
2
3
4
5
6
7
8
9
10
11
12
13
import javax.persistence.Cacheable;
import javax.persistence.Entity;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
@Entity
@Cacheable
public class Article extends PanacheEntity {
public Article() {}
public String title;
public String url;
public String author;
public String creationDate;
}
Panache comes with built in convenience methods to access databases, for example ‘listAll’ to read all articles (see code):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.Response;
...
@Path("/v1/articles")
@ApplicationScoped
@Produces("application/json")
@Consumes("application/json")
public class ArticleResource {
@GET
public List<Article> get() {
return Article.listAll(Sort.by("creationdate"));
}
}
Asynchronous Access with Vert.x Axle
After you’ve defined the dependencies and the configuration in application.properties, the articles can be read from the database via the following code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import io.vertx.axle.sqlclient.Row;
import io.vertx.axle.sqlclient.RowSet;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
...
public class PostgresDataAccess {
...
@Inject
io.vertx.axle.pgclient.PgPool client;
@PostConstruct
void initdb() {
client.query("DROP TABLE IF EXISTS articles").thenCompose(r -> client.query(
"CREATE TABLE articles (id SERIAL PRIMARY KEY, title TEXT NOT NULL, url TEXT, author TEXT, creationdate TEXT)"))
.toCompletableFuture().join();
}
public CompletableFuture<List<Article>> getArticlesReactive() {
CompletableFuture<List<Article>> future = new CompletableFuture<List<Article>>();
client.query("SELECT id, title, url, author, creationdate FROM articles ORDER BY id ASC").toCompletableFuture()
.orTimeout(MAXIMAL_DURATION, TimeUnit.MILLISECONDS).thenAccept(pgRowSet -> {
List<Article> list = new ArrayList<>(pgRowSet.size());
for (Row row : pgRowSet) {
list.add(from(row));
}
future.complete(list);
}).exceptionally(throwable -> {
future.completeExceptionally(new NoConnectivity());
return null;
});
return future;
}
private static Article from(Row row) {
Article article = new Article();
article.id = row.getLong("id").toString();
article.title = row.getString("title");
article.author = row.getString("author");
article.creationDate = row.getString("creationdate");
article.url = row.getString("url");
return article;
}
When using the reactive approach, as far as I know, the schema needs to be created programmatically. Additionally the data from the databases needs to be converted into Java objects manually. Hopefully these two areas will be simplified similarly to how this is done with JPA and Panache.
Closing Thoughts
All samples of this article are included in the open source project cloud-native-starter. Check it out to see the code in action.
This article is part of a series. Read the other articles of this series to learn about reactive programming: