
Many developers, including myself, want to use AI in their applications. Building machine learning models however, often requires a lot of expertise and time. This article describes a technique called AutoML which can be used by developers to build models without having to be data scientists. While developers only have to provide the data and define the goals, AutoML figures out the best model automatically.
There are several ways for developers to use AI without having to be a data scientist:
- Cognitive Services
- Reusable Models
- AutoML
Cognitive Services
Cognitive services are provided by most cloud providers these days. For example IBM offers as part of the Watson Developer Cloud services for speech recognition, natural language understanding, visual recognition and assistants. Developers can use these services out of the box or customize them declaratively. The services can be accessed via REST APIs or language libraries.
Reusable Models
Cognitive services like the Watson services cover common AI scenarios. For more specific scenarios developers can sometimes use existing models that have been open sourced. The visual recognition models for mobile devices from Google are a good example. They can be customized via transfer learning without having to write code.
Another example is the IBM Model Asset Exchange which comes with two types of models: Models that can be re-used directly and models with instructions how to train and customize them. The models are put in Docker containers and can be invoked via REST APIs.
AutoML
While cognitive services and reusable models cover many scenarios, sometimes you need to build your own models for your individual requirements and that is often not a trivial task. Personally I took some ML/DL classes, understand the basics and can run the tutorials, but I have a hard time to create my own models for my own specific requirements.
This is were AutoML comes in. Basically AutoML is a set of capabilities that allows developers and data scientists to provide data, to define potential features (input) and to define the labels (output). AutoML takes care of the heavy lifting and figures out the best features, the best algorithms and the best hyperparameters.
To learn more about AutoML I encourage you to watch the TensorFlow Dev Summit 2018 keynote and the talk from Andreas Mueller. I also like the recent series of blog entries on fast.ai.
There are several different AutoML open source libraries and commercial offerings available which use different approaches to find the best model. For example IBM provides Watson Machine Learning to identify the best algorithm. Additionally with Watson Deep Learning hyperparameters can be identified.
auto-sklearn
There seem to be several promising open source libraries. Unfortunately I couldn’t use a lot of them for license reasons. One AutoML library that looks interesting is auto-sklearn which won the 2016 KDnuggets competition. There seems to be an improved successor of this library which won the 2018 competition but I couldn’t find that code which is why my sample below uses the publicly available version.
Running auto-sklearn in IBM Watson Studio
auto-sklearn comes with a hello world sample. You can use a slightly different version of this sample in a notebook in Watson Studio.
First you need to define a custom Anaconda-based environment with auto-sklearn.
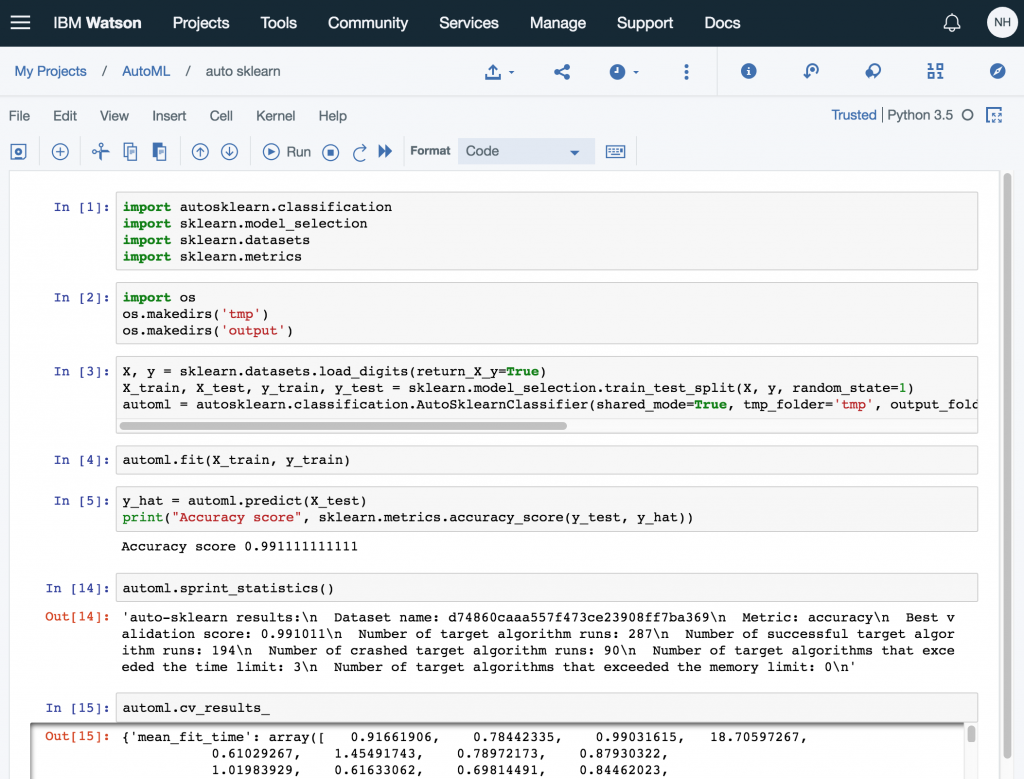
When I tried to run the unmodified sample, I ran into permission issues when accessing the file system. It turned out that the library uses absolute paths to which the notebooks don’t have access. Fortunately auto-sklearn let me change these directories so that I could use relative directories to which notebooks have full access. Here is the modified code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
import os
os.makedirs('tmp')
os.makedirs('output')
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, random_state=1)
automl = autosklearn.classification.AutoSklearnClassifier(shared_mode=True, tmp_folder='tmp', output_folder='output', delete_tmp_folder_after_terminate=False, delete_output_folder_after_terminate=False)
automl.fit(X_train, y_train)
y_hat = automl.predict(X_test)
print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))
automl.sprint_statistics()
automl.cv_results_
This is a screenshot of the notebook:
Want to run this sample yourself? All you need to do is to get a free IBM Cloud account and create a notebook in Watson Studio.