
One of the key challenges of LLMs is hallucination. Retrieval Augmented Generation (RAG) reduces hallucination but cannot eliminate it. This post summarizes a new concept to address this shortcoming.
There is an exciting new paper Self-RAG: Learning to Retrieve, Generate and Critique through Self-Reflections. One of the authors is Avi Sil from IBM with whom I have the pleasure to work together.
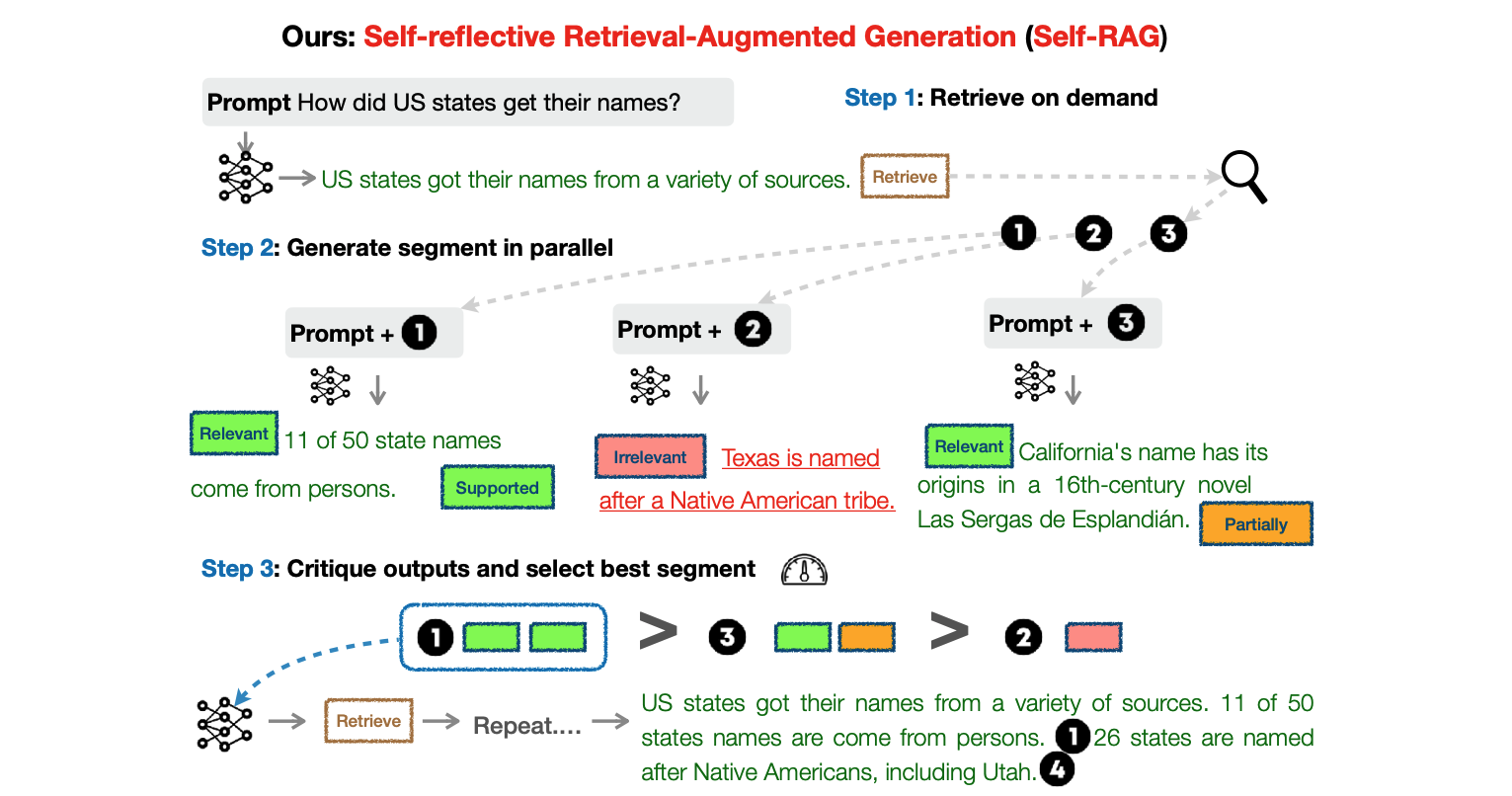
Decoder-based LLMs are designed to generate next tokens. Once tokens have been generated, the models cannot automatically correct themselves. However, in subsequent invocations they can check their own generations. The new paper leverages this capability. As displayed in the diagram at the top of this post, the model generates multiple responses in parallel and judges which of these responses are the best ones.
Retrieval
Like RAG, text from searches is put into the prompts to generate responses. The novelty is that this is not only done once but can happen whenever the model determines that it is necessary. The model can return a special Retrieve token which signals the application to perform a search. In this case the application queries databases, invokes APIs, etc. and puts the search results into the prompts.
In the following example ‘[Retrieval]’ is returned by the model as indication for the application to append the search result in the following ‘paragraph’ section.
1
2
3
Context: xxx
Question: xxx?
[Retrieval]<paragraph>xxx</paragraph>
Self-RAG
In addition to the special retrieve token there are three critique tokens.

- IsRel: Whether the response is relevant for the given question and context
- IsSup: Whether the response is grounded (supported) by the information in the context
- IsUse: How useful the response is, ranked from 1 to 5
In addition to the core model, there is a second model for the self-reflection. As stated in the paper GPT-4 was used to distil this knowledge. The output of this process is fed into the fine-tuning of the core model. Here is a sample prompt:
1
2
3
4
Given an instruction, make a judgment on whether finding some external documents
from the web helps to generate a better response.
... followed by few-shot demonstrations
The approach is like RLHF (Reinforcement Learning Human Feedback). From the paper: “Manual assessment reveals that GPT-4 reflection token predictions show high agreement with human evaluations”.
Here is the complete algorithm:

Data
The training dataset has been published.
1
2
3
4
Answer this question: when are the olympics going to be in the us??
[Retrieval]<paragraph>2028 Summer Olympics The NBC Universal Studio Lot is planned
to be the site of the International Broadcast Centre for the Games. ...</paragraph>
[Relevant]2028[Fully supported][Utility:5]
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.