
The context windows of Large Language Models define how much input can be provided in prompts. Fine-tuning of LLMs with longer context windows is resource intensive and expensive. With the new LongLoRA technique this can be done more efficiently.
LLMs are stateless. To preserve state of longer multi-turn conversations, the conversation history is passed in subsequent prompts. Scenarios like summarizing book chapters or generating source code often require long context windows too.
The paper Efficient Fine-tuning of Long-Context Large Language Models describes an innovative technique to fine-tune LLMs with long context windows.
Results
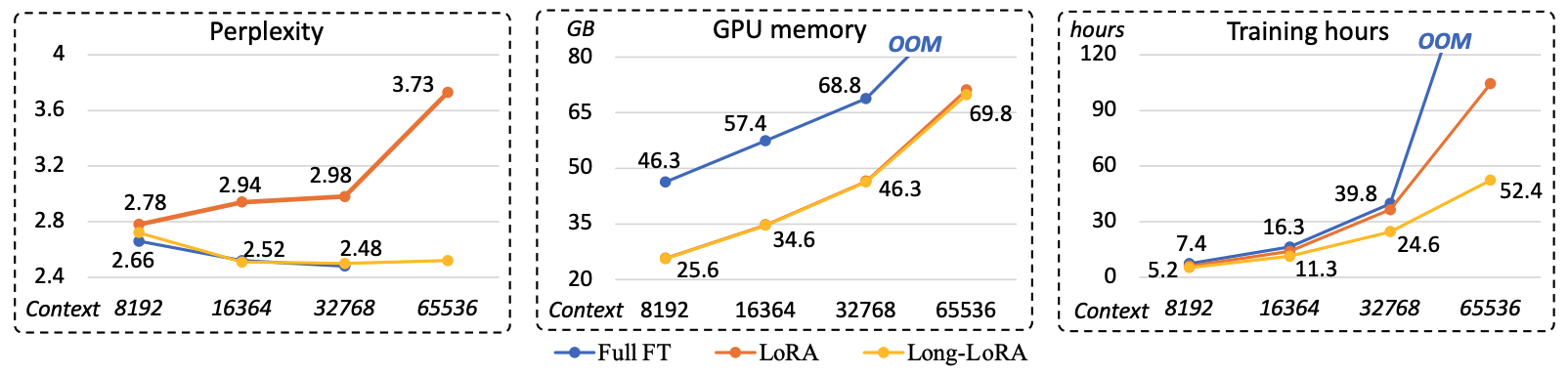
Via LongLoRA the fine-tuning efficiency is increased a lot. The diagram shows that perplexity (quality/performance) is almost identical to classic fine-tuning. At the same time training hours and GPU memory go down significantly.
The provided sample models are based on LLaMA and have up to 100k tokens context windows.
Concepts
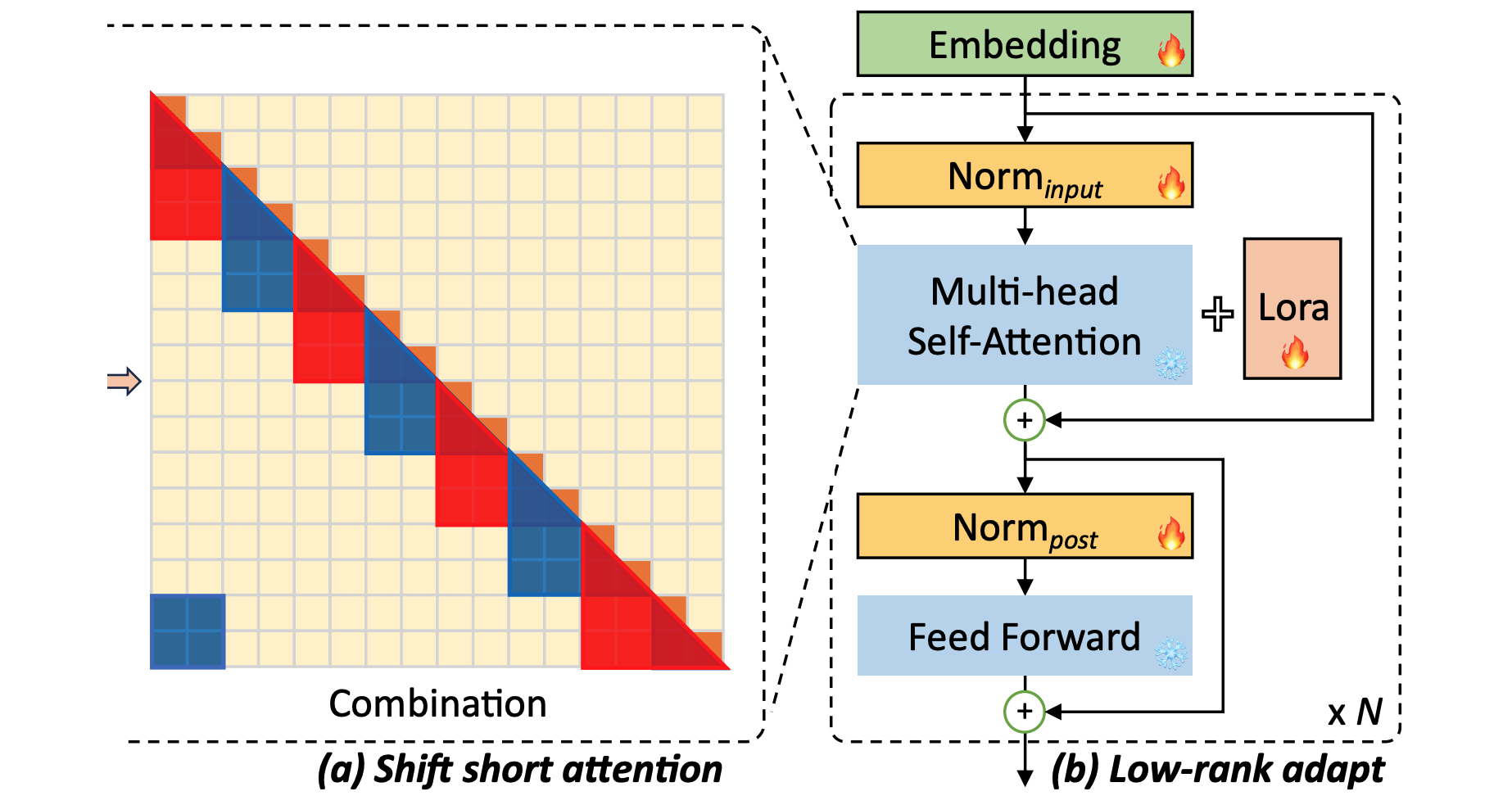
The core idea behind LongLoRA is Shift Short Attention (S2 Attention). Rather than passing the complete input, the content is split in smaller parts. The trick is not only to split the content, but to have overlaps. This is necessary to avoid loosing context.
Let’s say you want to train a model with an 8k context window. Input could be split in multiple parts with maximal lengths of 2k tokens as used for classic fine-tuning:
- 1, 2, …, 2047, 2048
- 2049, 2050, …, 4095, 4096
- 4097, 4098, …, 6143, 6144
- 6145, 6146, …, 8191, 8192
The approach above does not work since the relations between the different parts of the documents get lost which is why overlaps are utilized by LongLoRA.
- 1, …, 2048
- 1025, …, 3072
- 2049, …, 4096
- 3073, …, 5120
- 4097, …, 6144
- 5121, …, 7168
- 6145, …, 8192
- 7169, …, 8192, 1, …, 1024
In addition to S2 Attention, LongLoRA also leverages the same concepts of classic LoRA where most of the model weights are frozen and only a small subset of parameters is trained. As displayed in the diagram at the top of this post, the embedding and normalization layers are trainable as well.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.