

IBM announced the general availability of the first models in the watsonx Granite model series which are decoder based Foundation Models trained with enterprise-focused datasets curated by IBM.
IBM’s Granite model series is a collection of generative AI models to advance the infusion of generative AI into business applications and workflows. IBM’s Granite models apply generative AI to the modalities of language and code. IBM also confirmed that the standard contractual intellectual property protections for IBM products will apply to IBM-developed watsonx AI models.
IBM provides an IP indemnity (contractual protection) for its foundation models, enabling its clients to be more confident AI creators by using their data, which is the source of competitive advantage in generative AI. Clients can develop AI applications using their own data along with the client protections, accuracy and trust afforded by IBM foundation models.
There are several resources that describe the models:
- Paper: Granite Foundation Models
- Landing page: Foundation models in watsonx.ai
- Documentation: Supported foundation models available with watsonx.ai
- Announcement: IBM Announces Availability of watsonx Granite Model Series, Client Protections for IBM watsonx Models
Model Card
Granite implements a standard decoder only transformer architecture for retrieval augmented generation, summarization, content generation, named entity recognition, insight extraction, and classification.
There are three versions available: granite.13b, granite.13b.instruct and granite.13b.chat. As described in the paper, granite.13b.instruct, has undergone supervised fine-tuning to enable better instruction following so that the model can be used to complete enterprise tasks via prompt engineering. granite.13b.chat, has undergone a novel contrastive fine-tuning after supervised fine-tuning to further improve the model’s instruction following, mitigate certain notions of harms, and encourage its outputs to follow certain social norms and have some notion of helpfulness.
The new models have 13 billion parameters. Because of the smaller size, these models have the potential to be more efficient than larger models since they can fit onto a single A100-80 GB GPU which can also help lower the total cost of ownership.
The Granite 13b models have been trained with 1 trillion tokens based on a 6.48 TB dataset. As tokenizer the GPT-NeoX 20B tokenizer is utilized.
The models have a larger context window of 8K tokens.
At this point language support is English.
Data
The Granite models are trained on business-relevant domains, including financial, legal, IT, coding, and academic domains. IBM searches for and remove duplication, and employs URL block-lists, filters for objectionable content and document quality, sentence splitting, and tokenization techniques, all prior to model training. During the data training process, IBM works to prevent misalignments in the model outputs and uses supervised fine-tuning to enable better instruction following so that the model can be used to complete enterprise tasks via prompt engineering.
To be open and transparent, IBM has published the 14 data sources that have been utilized for the pre-training:
- arXiv
- Common Crawl
- GitHub Clean
- Hacker News
- OpenWeb Text
- Project Gutenberg
- Stack Exchange
- Wikimedia
- and more
There are additional datasets targeted for enterprise scenarios like finances and legal.
IBM relies on its internal end-to-end data and AI model lifecycle governance process. The initial data clearance process assures that no datasets are used to train IBM foundation models, including the Granite series, without careful consideration. After this pre-processing is done:
- Text extraction
- De-duplication
- Language identification
- Sentence splitting
- Hate, abuse and profanity annotation
- Document quality annotation
- URL block-listing annotation
- Filtering
- Tokenization
As documented in the paper to provide trust for IBM’s clients and partners, a lot of data is filtered out. From the 6.48 TB of data, 2.07 TB are left for the tokenization leading to 1 trillion tokens.
Benchmarks
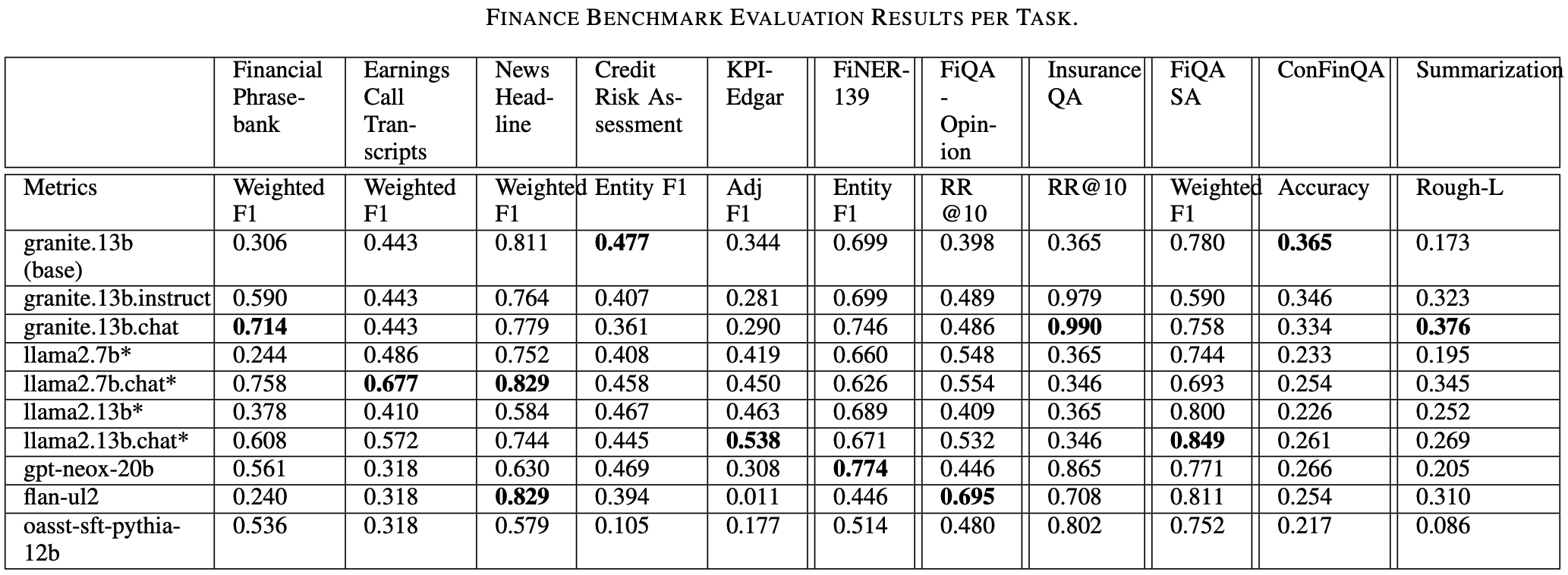
The paper also contains HELM benchmarks from Stanford university.The granite.13b.chat and granite.13b.instruct models were respectively the top-2 and top-3 models evaluated under 17B parameters in size.
For enterprise benchmarks in the financial services domain the Granite models are among the best models.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.