
IBM announced the general availability of Watson NLP (Natural Language Understanding) and Watson Speech containers which can be run locally, on-premises or Kubernetes and OpenShift clusters. This post describes how to run Watson NLP locally.
To set some context, here is the description of IBM Watson NLP Library for Embed.
Enhance your applications with best-in-class Natural Language AI: Introducing IBM Watson NLP Library for Embed, a containerized library designed to empower IBM partners with greater flexibility to infuse powerful natural language AI into their solutions. It combines the best of open source and IBM Research NLP algorithms to deliver superior AI capabilities developers can access and integrate into their apps in the environment of their choice. Offered to partners as embeddable AI, a first of its kind software portfolio that offers best of breed AI from IBM.
The Watson NLP library is available as containers providing REST and gRPC interfaces. While this offering is new, the underlaying functionality has been used and optimized for a long time in IBM offerings like the IBM Watson Assistant and NLU (Natural Language Understanding) SaaS services and IBM Cloud Pak for Data.
Watson NLP comes with a wide variety of text processing functions, such as emotion analysis and topic modeling. Watson NLP is built on top of the best AI open source software. Additionally it provides stable and supported interfaces, it handles a wide range of languages and its quality is enterprise proven.
To try it, a trial is available. The container images are stored in an IBM container registry that is accessed via an IBM Entitlement Key.
How to run NLP locally via Docker
To run NLP as container locally, you first need to define which models you want to use which address different use cases. By only picking the ones you need, the size of the containers is reduced. You can also train your own models which I want to blog about separately.
To define your models, save the following script to ‘runNLP.sh’ and modify the fourth line. The script pulls down the models and puts them in a volume that is accessed by the NLP runtime container.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#!/usr/bin/env bash
IMAGE_REGISTRY=${IMAGE_REGISTRY:-"cp.icr.io/cp/ai"}
RUNTIME_IMAGE=${RUNTIME_IMAGE:-"watson-nlp-runtime:1.0.18"}
export MODELS="${MODELS:-"watson-nlp_syntax_izumo_lang_en_stock:1.0.7,watson-nlp_syntax_izumo_lang_fr_stock:1.0.7"}"
IFS=',' read -ra models_arr <<< "${MODELS}"
# Create a shared volume and initialize with open permissions
docker volume rm model_data 2>/dev/null || true
docker volume create --label model_data
docker run --rm -it -v model_data:/model_data alpine chmod 777 /model_data
# Put models into the shared volume
for model in "${models_arr[@]}"
do
docker run --rm -it -v model_data:/app/models -e ACCEPT_LICENSE=true $IMAGE_REGISTRY/$model
done
# Run the runtime with the models mounted
docker run ${@} \
--rm -it \
-v model_data:/app/model_data \
-e ACCEPT_LICENSE=true \
-e LOCAL_MODELS_DIR=/app/model_data \
-p 8085:8085 \
-p 8080:8080 \
$tls_args $IMAGE_REGISTRY/$RUNTIME_IMAGE
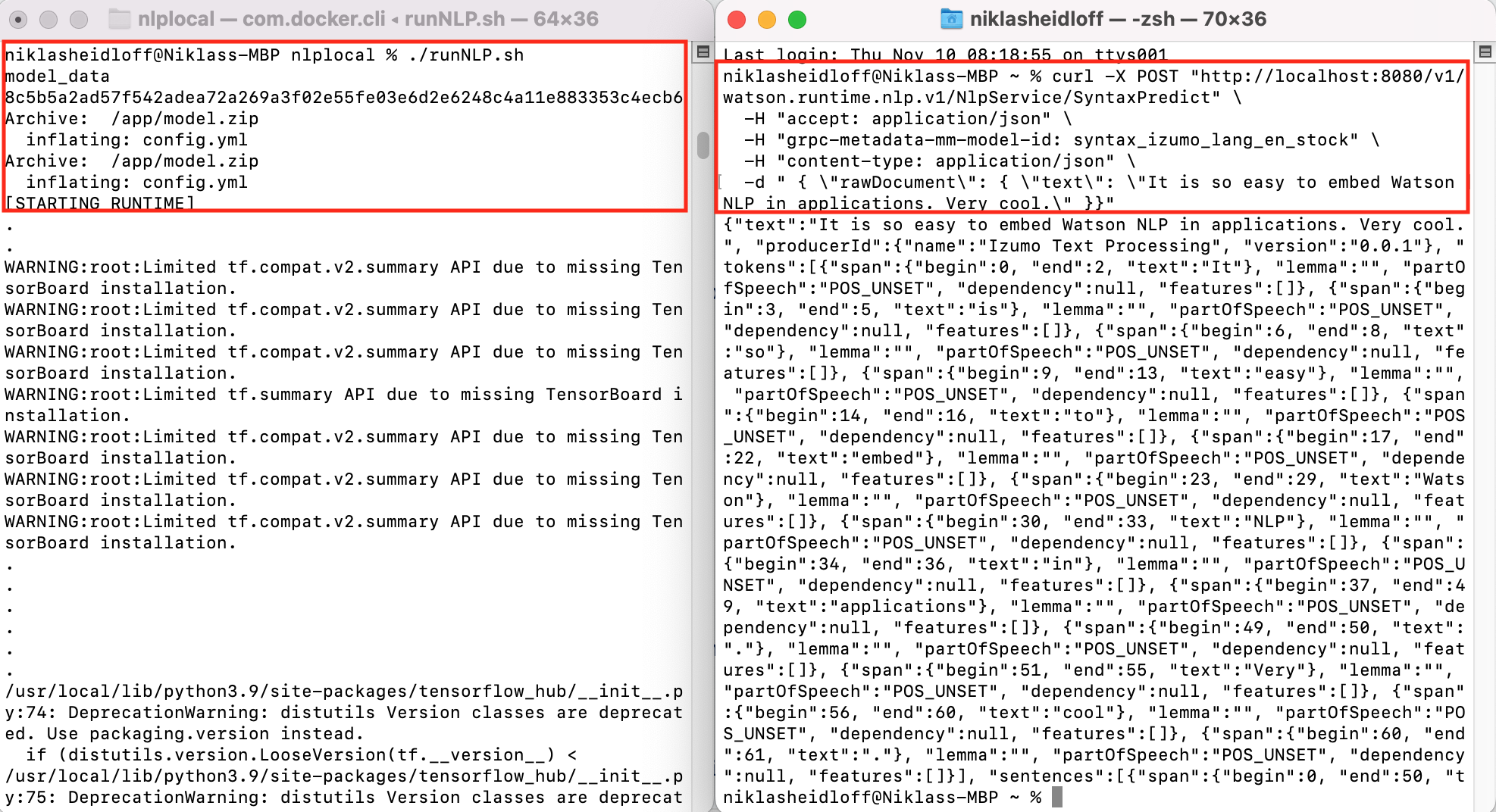
To download the models and run the container, invoke these commands in a first terminal:
1
2
$ docker login cp.icr.io --username cp --password <entitlement_key>
$ ./runNLP.sh
In second terminal invoke this command to invoke a REST API:
1
2
3
4
5
$ curl -X POST "http://localhost:8080/v1/watson.runtime.nlp.v1/NlpService/SyntaxPredict" \
-H "accept: application/json" \
-H "grpc-metadata-mm-model-id: syntax_izumo_lang_en_stock" \
-H "content-type: application/json" \
-d " { \"rawDocument\": { \"text\": \"It is so easy to embed Watson NLP in applications. Very cool.\" }}"
Here is a screenshot of the container in action:
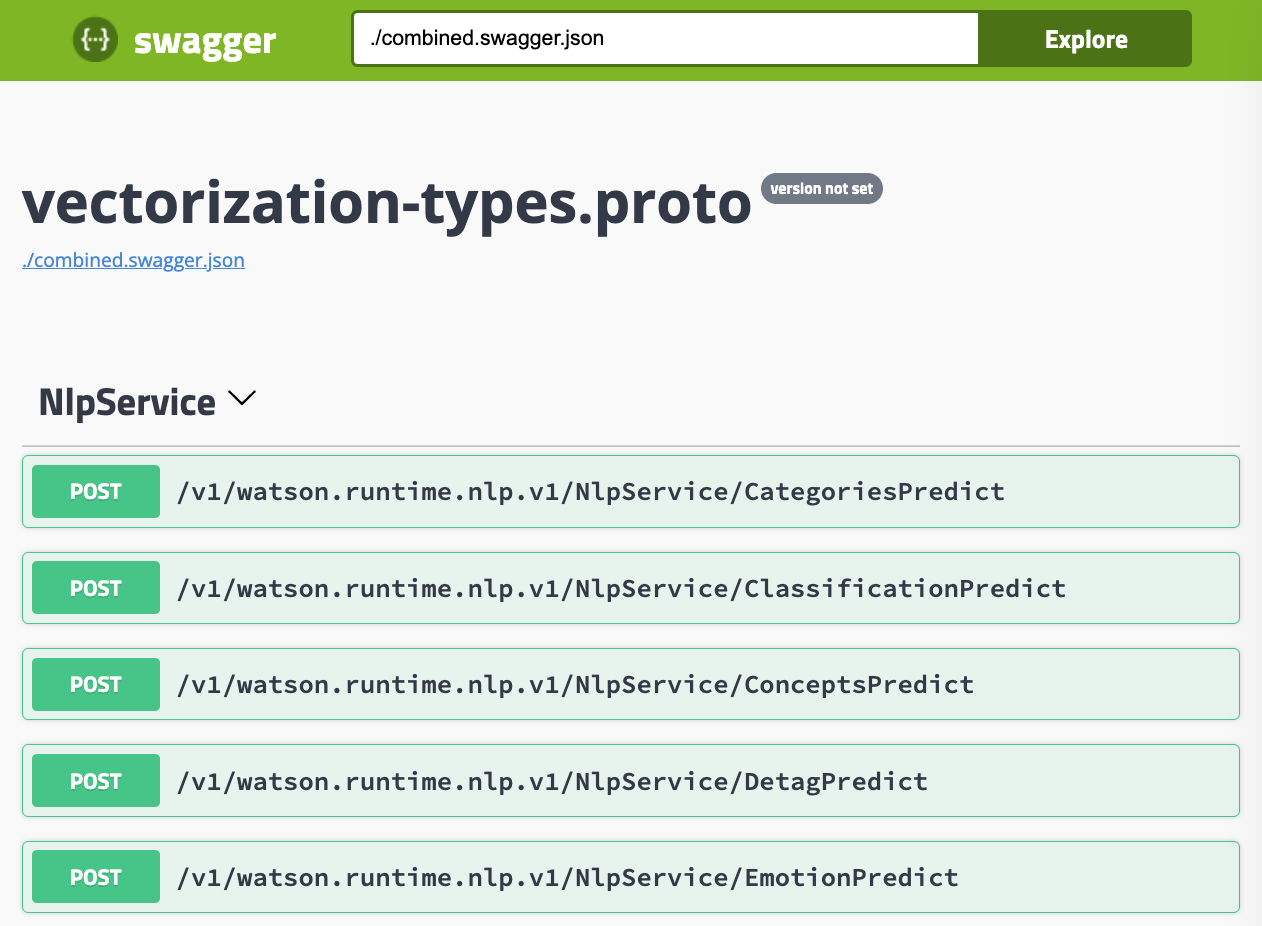
You can invoke the Swagger (OpenAI) user interface by opening http://localhost:8080/swagger.
The NLP containers also provides a gRCP interface.
To find out more about Watson NLP, check out these resources: