
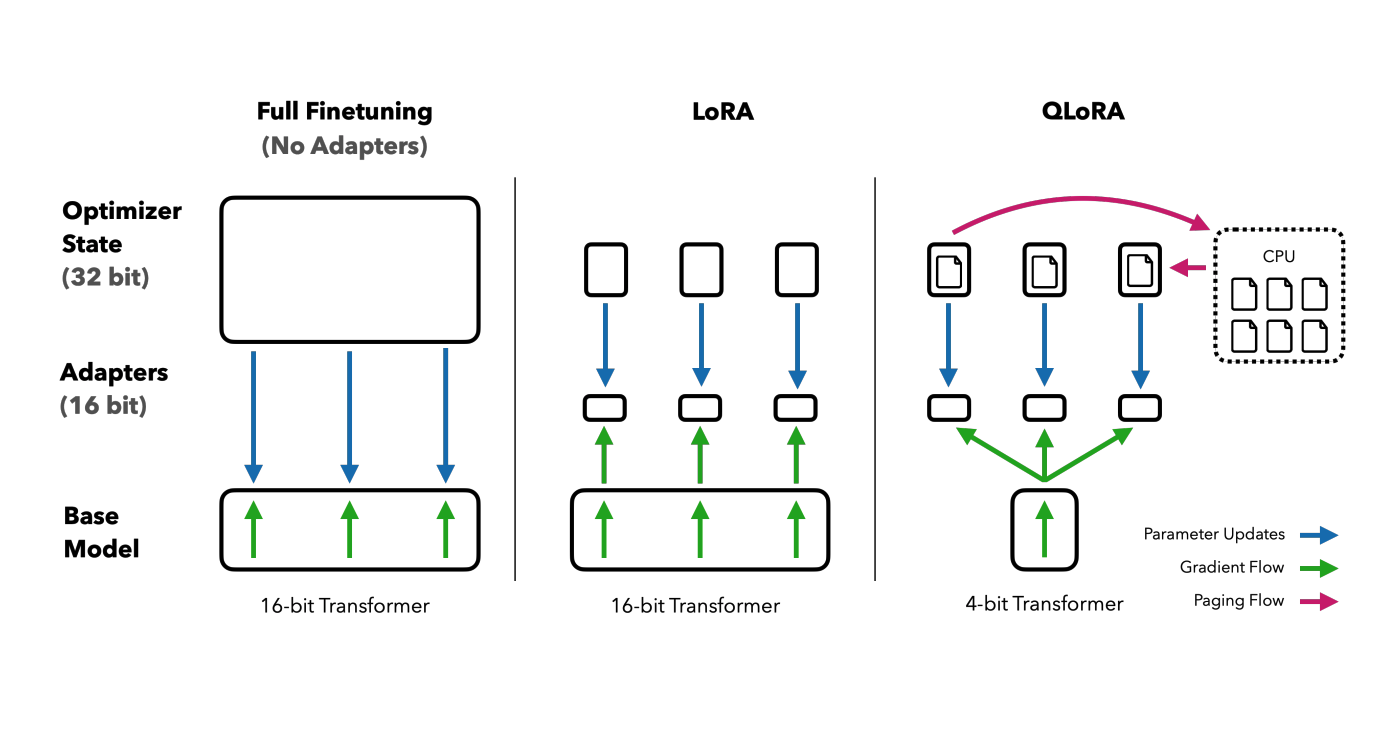
LoRA-based fine-tuning of Large Language Models freezes the original weights and only trains a small number of parameters making the training much more efficient. QLoRA goes one step further and reduces the necessary memory for trainings by quantizing the pretrained model weights.
LLMs are neural networks of nodes with connections between them that have certain weights, also referred to as parameters. Weights of models can be stored in different datatypes. In general, the bigger the datatypes are, the more precise the models can be. At the same time these bigger datatypes require more memory so that you need to have more resources and/or longer training time.
Almost no Tradeoff
While I initially thought that this quantization comes at the expense of performance, it turns out that the performance is almost identical.
QLoRA reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU.
Let’s look at the accuracy comparisons from the paper QLoRA: Efficient Finetuning of Quantized LLMs. BFloat16 (32-bit) shows the classic fine-tuning, Float4 and NFloat4 + DQ are two QLoRA fine-tunings. In summary the much cheaper and faster QLoRA fine-tunings are equally good or only one point worse.

Note that these good results require the benchmarks to be like the tasks the models have been fine-tuned on. In other words, the fine-tuned models are more specialized on certain tasks (as you would expect). In this case MMLU (Massive Multitask Language Understanding) fits well to Alpaca and FLAN.
Quantization
Classic fine-tuning of Large Language Models typically changes most or all weights of the models which requires a lot of resources. LoRA- and QLoRA-based fine-tunings freeze the original weights and only train a small number of parameters making the trainings much more efficient.
LLMs are usually stored in 32-bit datatypes. With QLoRA weights (parameters) are converted into smaller datatypes, for example 4-bit NormalFloat which means 16 discrete values. However, only the parameters that are frozen are quantized. The parameters that are trained stay in the 32-bit representation. When using the models for inferences, the frozen 4-bit parameters are dequantized to 32-bit. Similarly, dequantization is done for backpropagation.
Quantization and dequantization between 4- and 32-bit cannot be done without errors obviously. The question is why this mechanism works (almost) as efficiently as classic fine-tuning without quantization.
The trainable parameters for LoRA fine-tunings are adjusted based on 1. on the fine-tuning data and 2. on the original frozen 32-bit weights. The same trainable parameters for QLoRA fine-tunings are also adjusted on the fine-tuning data (1), but not on the original 32-bit weights, but on the frozen 4-bit weights. The trainable parameters can fix or undo the errors that were added when quantizating and dequantizating the non-trainable weights.
Code
To fine-tune models with QLoRA, the Hugging Face Transformers library can be utilized similarly to LoRA fine-tunings. The biggest addition is ‘BitsAndBytesConfig’ which is used for the quantization and dequantization.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
from trl import SFTTrainer
...
model_id = "google/flan-t5-xxl"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, use_cache=False, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
...
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
...
args = TrainingArguments(
output_dir="xxx",
bf16=True,
tf32=True,
...
)
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
tokenizer=tokenizer,
args=args,
...
)
trainer.train() # there will not be a progress bar since tqdm is disabled
trainer.save_model()
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.