
Fine-tuning of Large Language Models optimizes models for certain AI tasks and/or improves performance for smaller and less resource intensive models. This post describes how to further improve models based on human feedback.
As explained in my post Evaluating Question Answering Solutions there are different ways to evaluate Large Language Models, for example for Question Answering scenarios. Simple metrics like prediction loss/cross entropy, Bleu and Rouge are often not good enough. Instead, human feedback is needed from experts. Human input is also necessary for model alignment.
RLHF
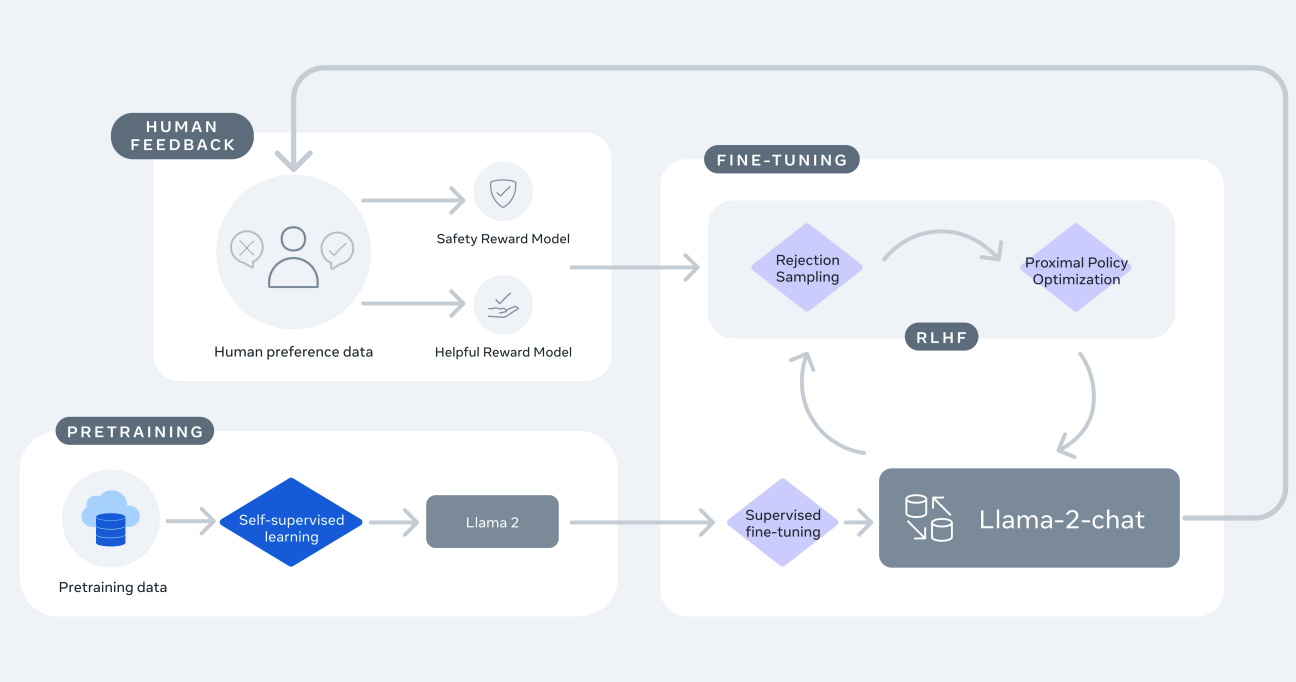
Reinforcement Learning from Human Feedback (RLHF) is a technique to address these challenges. Training and fine-tuning is typically done in these steps:
- Pretraining
- Fine-tuning
- RLHF: Fine-tuning based on human feedback or preferences
The following documents are great resources to learn RLHF:
- Illustrating Reinforcement Learning from Human Feedback (RLHF)
- LLM Training: RLHF and Its Alternatives
- Llama 2: Open Foundation and Fine-Tuned Chat Models
- Fine-tune Llama 2 with DPO
Improvements
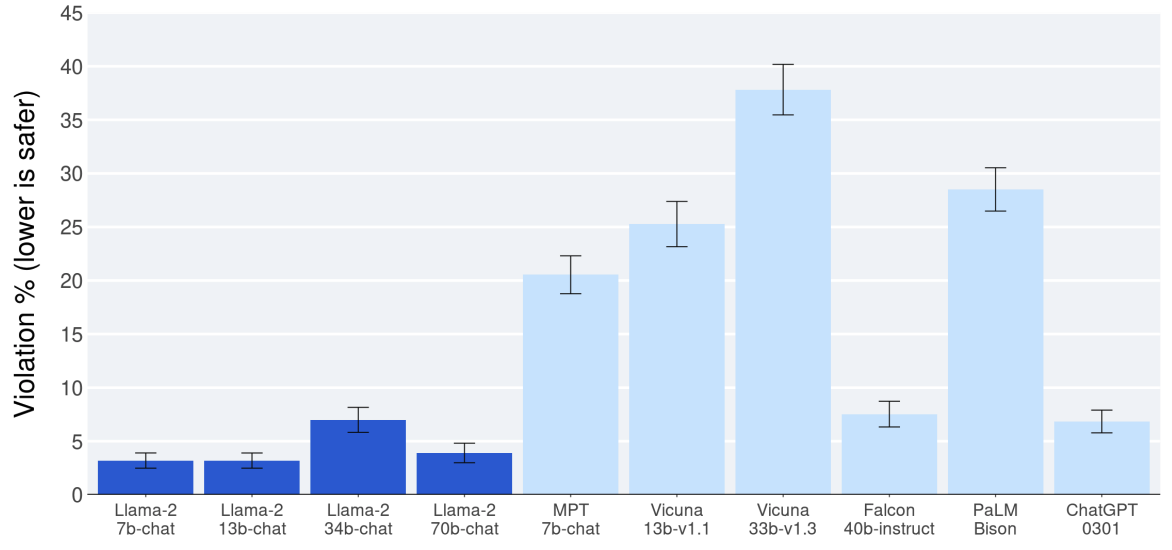
While pretraining and fine-tuning is relatively well understood, RLHF is a rather evolving, but important field. As demonstrated by LLaMA 2 and ChatGPT it increases performance significantly. The following diagram shows the results from the LLaMA 2 paper: ‘Safety human evaluation results for Llama 2-Chat compared to other open-source and closed source models’.
Reward Models
To implement RLHF, first human input is needed. As the LLaMA paper states, this can be done by giving humans different options which they can rank.
RLHF is a model training procedure that is applied to a fine-tuned language model to further align model behavior with human preferences and instruction following. We collect data that represents empirically sampled human preferences, whereby human annotators select which of two model outputs they prefer. This human feedback is subsequently used to train a reward model, which learns patterns in the preferences of the human annotators and can then automate preference decisions.
Next reward models are created to fine-tune models, e.g., via Proximal Policy Optimization (PPO), as described in the article referenced above.
We can design a reward model that outputs a reward score for the optimization subsequent stage […]. This reward model generally originates from the LLM created in the prior supervised finetuning step. […] To turn the model […] into a reward model, its output layer (the next-token classification layer) is substituted with a regression layer, which features a single output node. […] Use the reward model to finetune the previous model from supervised finetuning.
LLaMA 2 uses two reward models, a safety reward model and a helpful reward model to balance the requirements alignment and usefulness. In addition to PPO, LLaMA also uses rejection sampling. Dependent on the fine-tuning stage these two methods get different weights.
DPO
Creating reward models is not trivial and creating human annotations takes time and is not cheap. Because of this, new techniques are evolving. Direct Preference Optimization (DPO) is one of these new techniques which does not require award models and human annotations. Instead it uses preferences from experts.
To me DPO looks very similar to ‘normal’ fine-tuning. The only potential difference is that Contrastive Learning is utilized to define good and bad responses. Each data unit contains this information:
- Prompt
- Chosen: contains the preferred generated response to the corresponding prompt
- Rejected: contains the response which is not preferred or should not be the sampled response
TRL
Hugging Face provides a library Transformer Reinforcement Learning (TRL) for both, the ‘classic’ RLHF/PPO as well as DPO.

There is an end-to-end RLHF DPO training example of the LLaMA model on the Stack exchange dataset.
Next Steps
As with ‘normal’ fine-tuning it’s important to find the right balance and right amount of fine-tuning to avoid catastrophic forgetting and to prevent overfitting.
Whenever humans are supposed to evaluate responses or define their preferences, you should try to find a diverse group of people to avoid bias.
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.