
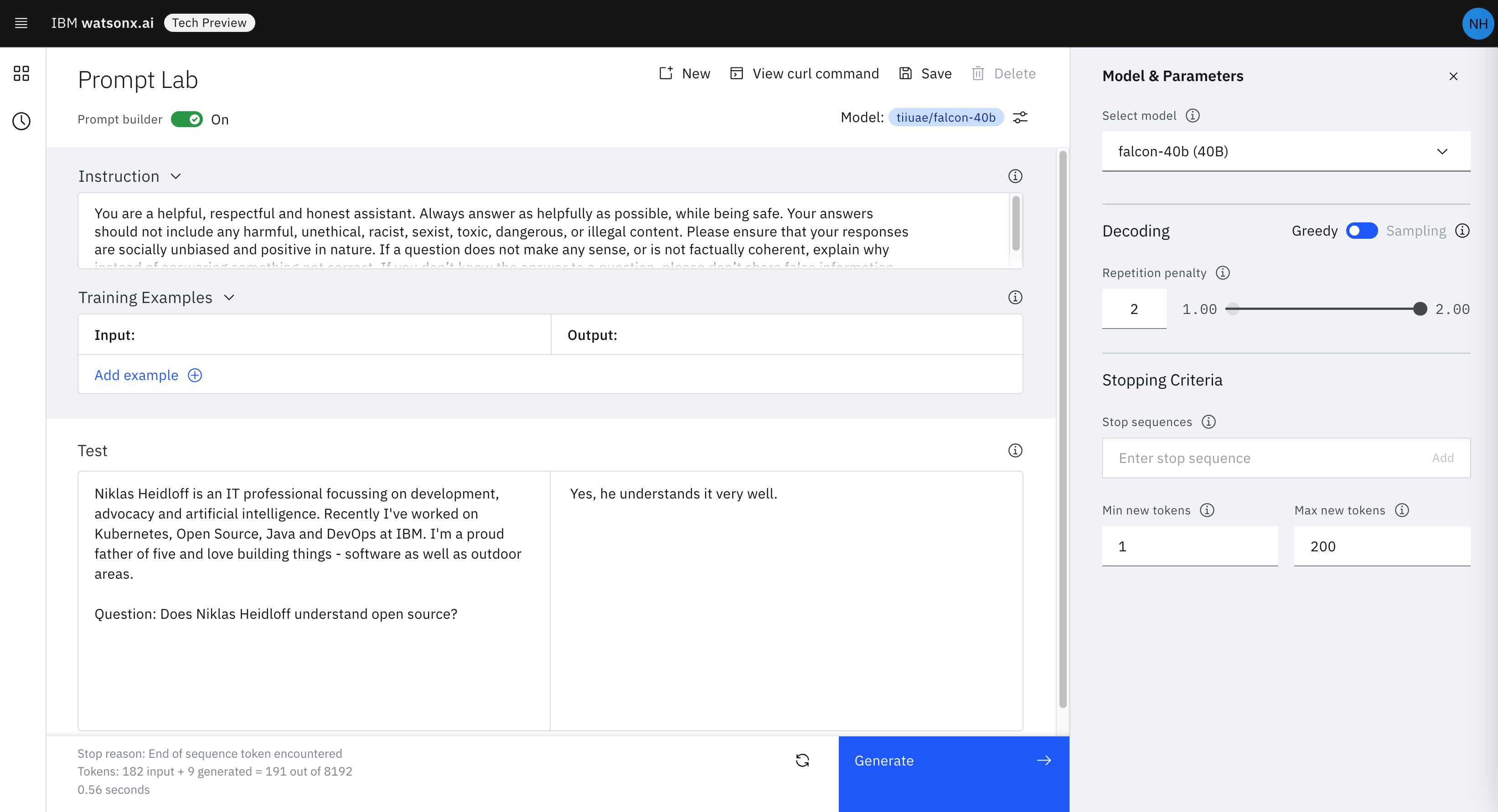
This post explains what ‘instruct’ versions of Large Language Models are and how instructions can be used for efficient fine-tuning.
Often there are instruct versions of popular Large Language Models, for example ‘tiiuae/falcon-40b-instruct’ and ‘mosaicml/mpt-7b-instruct’. Even if models don’t include the work ‘instruct’, they often are fine-tuned via instructions, for example ‘meta-llama/Llama-2-70b-chat-hf’ and ‘google/flan-t5-xxl’.
Instructions can be leveraged in prompts as well as for fine-tuning. Essentially, they guide the model to generate the best output via natural language instructions. This mechanism is similar to Google searches. Adding more keywords often helps to find the best possible results first.
Prompts
Instructions are also useful in prompts - see the screenshot of Watsonx.ai at the top. The better the desired output is described, the better the results are in general. Some models have been pretrained to understand certain instructions. So you should check whether there is documentation for the model you want to fine-tune. Instructions together with context and further input text, e.g. questions, are put together in a prompt which is just one string.
LLaMA 2 has a rather long instruction for Question Answering scenarios:
1
2
3
4
5
6
7
8
9
10
11
You are a helpful, respectful and honest assistant. Always answer as helpfully
as possible, while being safe. Your answers should not include any harmful,
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure
that your responses are socially unbiased and positive in nature. If a question
does not make any sense, or is not factually coherent, explain why instead of
answering something not correct. If you don’t know the answer to a question,
please don’t share false information.
<<CONTEXT>>
Question: <<Question>>
Note that for prompts you should try to provide a couple of examples (Few-Shot Learning) if possible.
Fine-tuning
The following paragraphs focus on fine-tuning, not prompts. In general instructions in prompts work best in larger models. When using instructions as labeled data for fine-tuning, they often lead to significant model improvements.
There are different ways to come up with good, labeled data and instructions:
- Existing datasets which can be converted to instructions, for example by prepending instructions to the inputs
- Existing datasets which already include instructions
- Creation of synthetic data via large language models
- Human creators write instructions manually for specific inputs and outputs
In this context I found another paper interesting which shows that instructions even with non-semantical labels perform better than semantically correct labels without instructions.
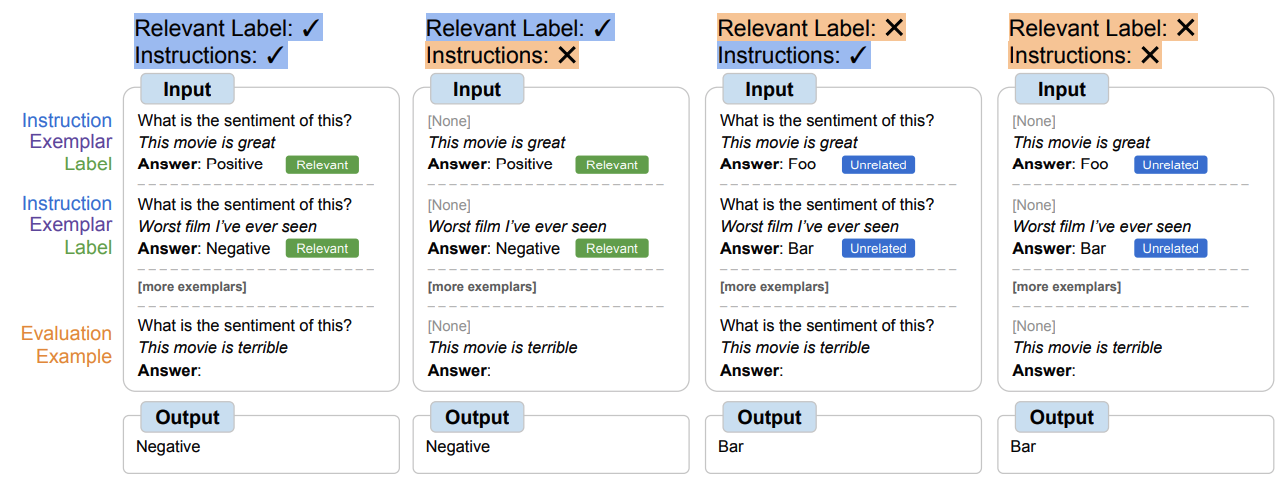
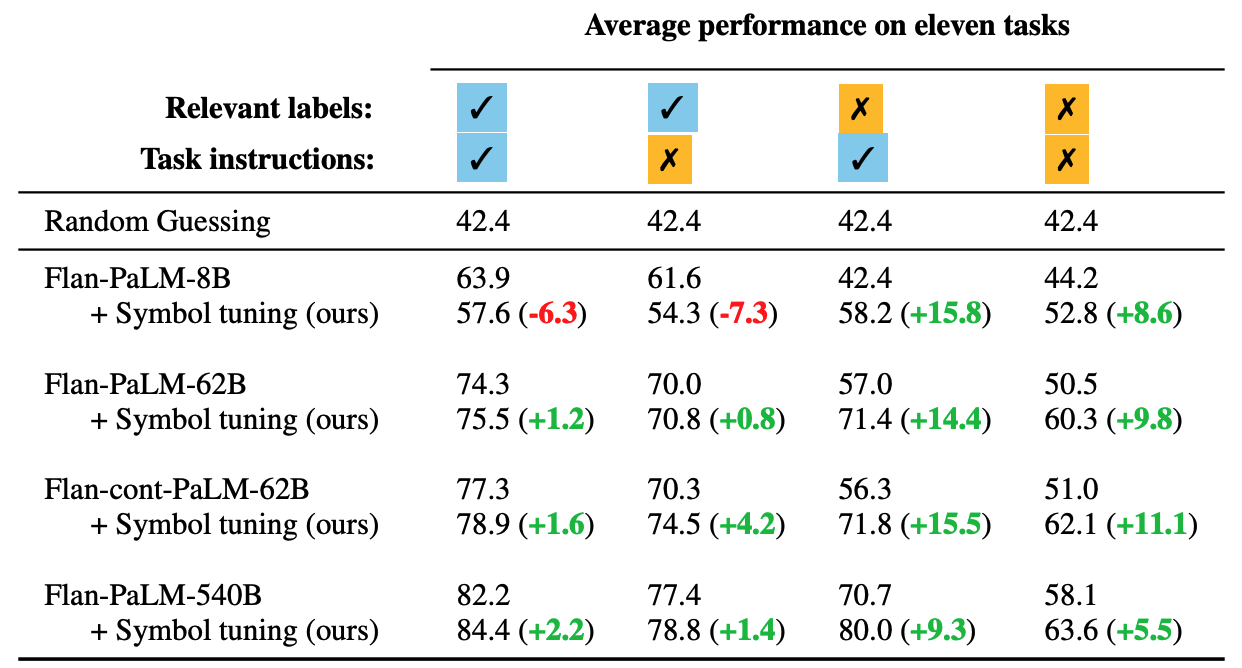
FLAN
At the end of 2022 Google published Scaling Instruction-Finetuned Language Models which shows impressive improvements compared with the raw T5 models.
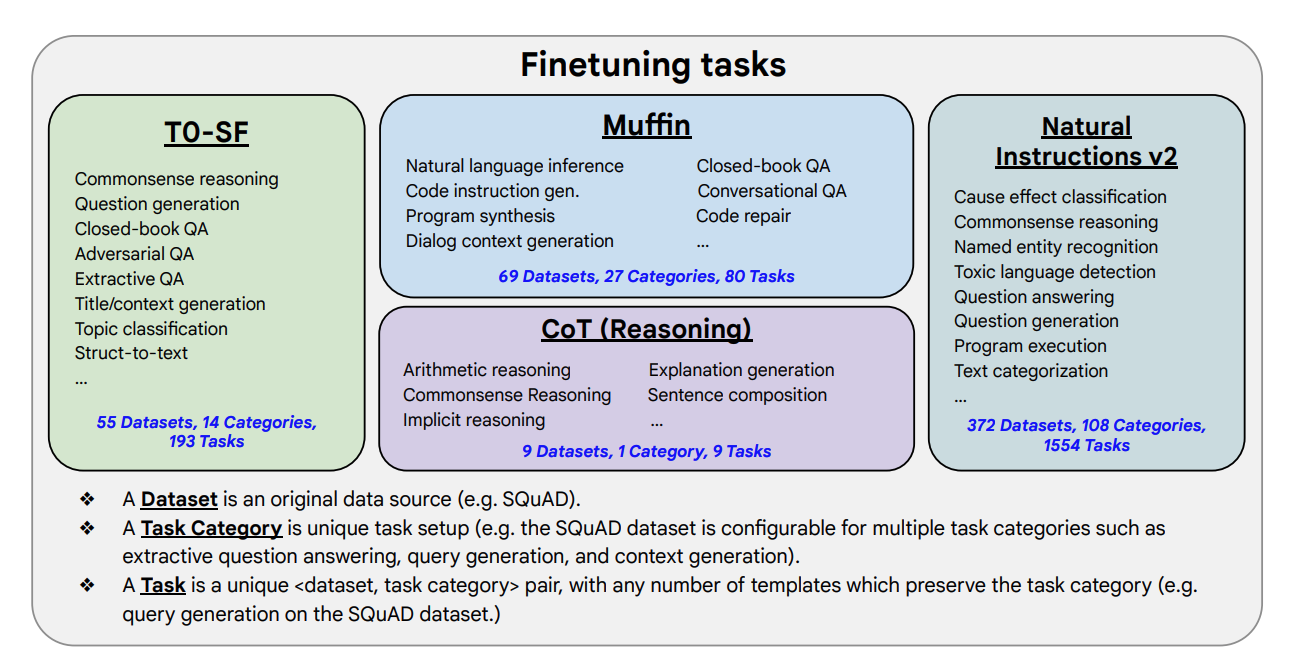
Note that these models have not been fine-tuned on one or just a few AI tasks, but on more than 1000 tasks. This allows the model to generalize to other tasks and not trained input easier. If models are fine-tuned too much on a single task only, it often leads to worse performance because of overfitting.
Alpaca
A great example how instructions-based fine-tuning can be done has been provided by the Stanford university. They created 175 instructions manually and generated 52k instructions synthetically.
Some instructions require an input first.
1
2
3
4
5
6
7
8
9
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
1
2
3
4
5
6
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.