
Watsonx.ai is IBM’s enterprise studio for AI builders to train, validate, tune and deploy Large Language Models. It comes with multiple open source and IBM LLMs which can be accessed via REST API.
Via the API all models can be invoked in the same way to run inference. There are REST APIs and Python APIs. They leverage the ‘/generation’ REST endpoint.
Authentication
The watsonx.ai as a Service API requires a bearer token which needs to be refreshed every hour. You can get it via API key.
1
curl -X POST 'https://iam.cloud.ibm.com/identity/token' -H 'Content-Type: application/x-www-form-urlencoded' -d 'grant_type=urn:ibm:params:oauth:grant-type:apikey&apikey=MY_APIKEY'
You can refresh the access token with the refresh token. The Python API does this automatically for you.
1
2
3
4
5
6
7
{
"access_token": "eyJhbGciOiJIUz......sgrKIi8hdFs",
"refresh_token": "SPrXw5tBE3......KBQ+luWQVY=",
"token_type": "Bearer",
"expires_in": 3600,
"expiration": 1473188353
}
Input
In addition to the model, the decoding type is important which I described in an earlier post Decoding Methods for Generative AI.
- decoding_method
- temperature
- top_k
- top_p
‘min_new_tokens’ and ‘max_new_tokens’ are relative self explanatory. Just note that ‘max_new_tokens’ does not lead automatically to endings that you might expect. For example, sentences can be cut off. You might have to do some post-processing in your code.
‘length_penalty’ is an interesting parameter. Some people who use large language models to generate answers in Question Answering scenarios expect rather short answers with additional links to find out more. This setting can help to shorten the answers for some models. Note that the length primarily depends on how models have been pretrained and fine-tuned. Especially decoder models with greedy decoding only focus on the next token. In this case the length_penality parameter has no impact.
‘repetition_penalty’ is very useful since it addresses the common repetition issue. My understanding is that this works only when ‘sampling’ is used as decoding method.
‘stop_sequences’ are one or more strings which will cause the text generation to stop. This is useful, for example, if you return JSON which is easy to parse that ends with three back ticks.
‘time_limit’ and ‘truncate_input_tokens’ are basically convenience parameters.
Output
The output can include more or less information based on the input parameters:
- generated_text: The text that was generated by the model.
- generated_token_count: The number of generated tokens.
- generated_tokens: The list of individual generated tokens with additional information: text, logprob, rank and top_tokens.
- input_token_count: The number of input tokens consumed.
- input_tokens: The list of input tokens for decoder-only models with additional information: text, logprob, rank and top_tokens.
As output you get the following ‘stop_reason’:
- not_finished - Possibly more tokens to be streamed
- max_tokens - Maximum requested tokens reached
- eos_token - End of sequence token encountered
- cancelled - Request canceled by the client
- time_limit - Time limit reached
- stop_sequence - Stop sequence encountered
- token_limit - Token limit reached
- error - Error encountered
Example
Let’s look at an example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
curl "https://eu-de.ml.cloud.ibm.com/ml/v1/text/generation?version=2023-05-29" \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer YOUR_ACCESS_TOKEN' \
-d '{
"input": "You are an AI LLM agent. Return a definition of a function '\''hello world'\'' with an input parameter '\''name'\'' in JSON format.\n\n",
"parameters": {
"decoding_method": "sample",
"max_new_tokens": 200,
"min_new_tokens": 0,
"random_seed": null,
"stop_sequences": [],
"temperature": 0.7,
"top_k": 50,
"top_p": 1,
"repetition_penalty": 1
},
"model_id": "meta-llama/llama-3-70b-instruct",
"project_id": "6b5b2153-5c18-4790-a605-f7f0d8415c12"
}' | jq '.'
The following output is returned. Note that ''' needs to be replaced with three back ticks.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
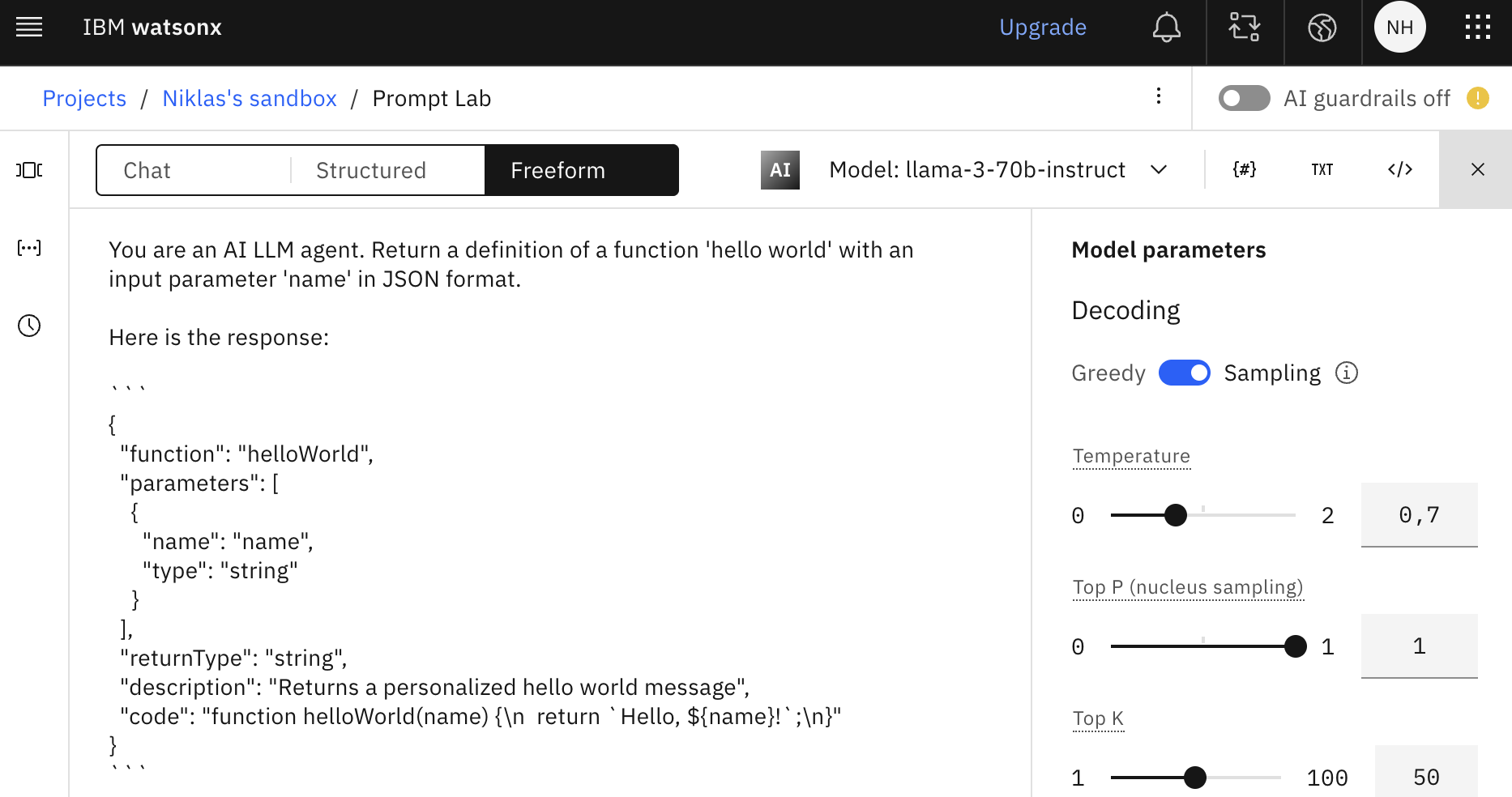
Here is the response:
'''
{
"function": "helloWorld",
"parameters": [
{
"name": "name",
"type": "string"
}
],
"returnType": "string",
"description": "Returns a personalized hello world message",
"code": "function helloWorld(name) {\n return `Hello, ${name}!`;\n}"
}
'''
Here is the full ouput:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
"model_id": "meta-llama/llama-3-70b-instruct",
"created_at": "2024-04-24T08:42:43.570Z",
"results": [
{
"generated_text": "Here is the definition:\n\n{ \n \"function\": \"helloWorld\", \n \"parameters\": { \n \"name\": \"string\" \n }, \n \"returnType\": \"string\", \n \"description\": \"A function to return a personalized hello world message.\" \n}",
"generated_token_count": 60,
"input_token_count": 29,
"stop_reason": "eos_token",
"seed": 1007052670
}
],
"system": {
"warnings": [
{
"message": "This model is a Non-IBM Product governed by a third-party license that may impose use restrictions and other obligations. By using this model you agree to its terms as identified in the following URL.",
"id": "disclaimer_warning",
"more_info": "https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-models.html?context=wx"
}
]
}
}
Note that this is different from the screenshot and the text output above since I ran it twice and used sampling.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.