
In the first part of this article I explain the amazing technologies Quarkus and Knative. In the second part I describe how to write simple microservices with Quarkus in Visual Studio Code in just a few minutes. In the last part I walk you through the steps how to deploy and run microservices as serverless applications on Kubernetes via Knative.
Quarkus
Quarkus is an open source project led by Red Hat. It’s a Java framework to build microservices which require little memory and start very fast. In other words Quarkus is a great technology to develop efficient containers.
From the outset Quarkus has been designed around a container first philosophy. What this means in real terms is that Quarkus is optimised for low memory usage and fast startup.
Quarkus is not a full Jakarta EE application server, but comes with a lot of similar functionality. The big difference is that Quarkus optimizes for container workloads by doing as much processing as possible at build time rather than at run time. This means that functionality like reflection is not supported.
Quarkus comes in two flavors. You can run it with classic JVMs like Hotspot or you can translate the Java code in binary code via GraalVM. When using binary code memory usage is even less and startup time is even shorter. Here are the measurements from the Quarkus home page.

In this article I focus on classic JVMs. Rather than using Hotspot I’ve used OpenJ9 which requires only roughly half of the memory compared to Hotspot. In my little test my simple microservice with a REST endpoint required only 34 MB which is similar to the Node.js node:8-alpine image. Until recently serverless applications have primarily been developed with less resource intensive technologies like Node.js.
I think that with Quarkus more enterprise developers will leverage their existing Java skills to build container workloads, for example serverless applications. In the cloud where you pay by 1. memory usage and 2. durations the code runs, frameworks like Quarkus make a huge difference.
Knative
Knative is an open source project initiated by Google with contributions from over 50 companies, for example Red Hat and IBM. Knative allows running containers on Kubernetes in a serverless fashion, so that containers only run when actually needed.
Run serverless containers on Kubernetes with ease, Knative takes care of the details of networking, autoscaling (even to zero), and revision tracking. You just have to focus on your core logic.
I think Knative’s key functionality is that it supports ‘scale to zero’. When containers are not needed anymore, they are shut down automatically so that they don’t consume compute resources. In other words you can run more containers in a cluster, just not all of them at the same time.
The big challenge for all serverless platforms is how to handle ‘cold starts’ of containers. The first time endpoints of containers are invoked, the containers need to be started first. Since Knative shuts down containers after a certain duration of inactivity, the same ‘cold starts’ occur the next time endpoints are invoked.
When using Knative the container with the microservice is not the only container in the pod. Additionally an Istio proxy and a Knative queue proxy are running. A fourth Istio container initiates the pod. These other three containers need to be started in addition to the microservice container. Even though Quarkus containers start in less than a second, the overall startup time of the pod is much longer. In my little test it took 16 seconds to get responses from my Quarkus container. So until there are better ways to handle the cold starts, Knative shouldn’t be used for all kinds of workloads.
I think the best usage of Knative are scenarios where a lot of compute is required infrequently and responses in a few milliseconds are not required. A good example is the processing of large data sets of massive scale which can be handled with serverless technologies running in parallel.
Development of Microservices with Quarkus
After the introduction of Quarkus and Knative let’s now move on and take a closer look how these technologies can be used. In this part I describe how to build your first microservices with Quarkus.
I think Quarkus provides an awesome developer experience. There is an extension for Visual Studio Code to create projects very easily. Quarkus also supports a development mode for hot code replace and built-in debugging functionality.
To create a new project open the palette (on Mac via ⇧⌘P) and choose “>Quarkus: Generate a Maven project”.

When you accept all defaults, a simple project is created with a greeting resource.
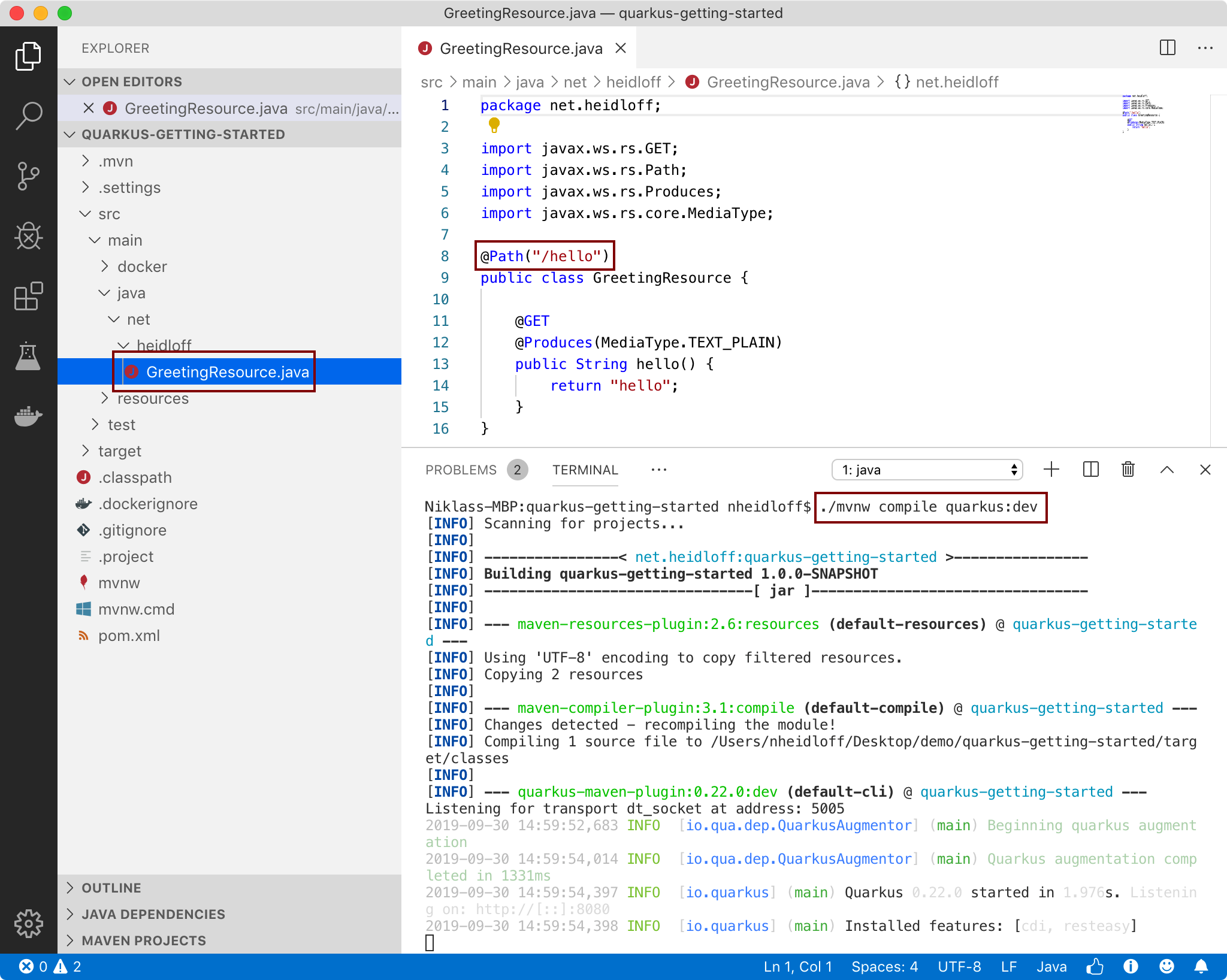
After this you can open a terminal and invoke “./mvnw compile quarkus:dev” to use the development mode. The endpoint will be accessible via the URL “http://localhost:8080/hello”. Try out the hot replace functionality! Very nice.
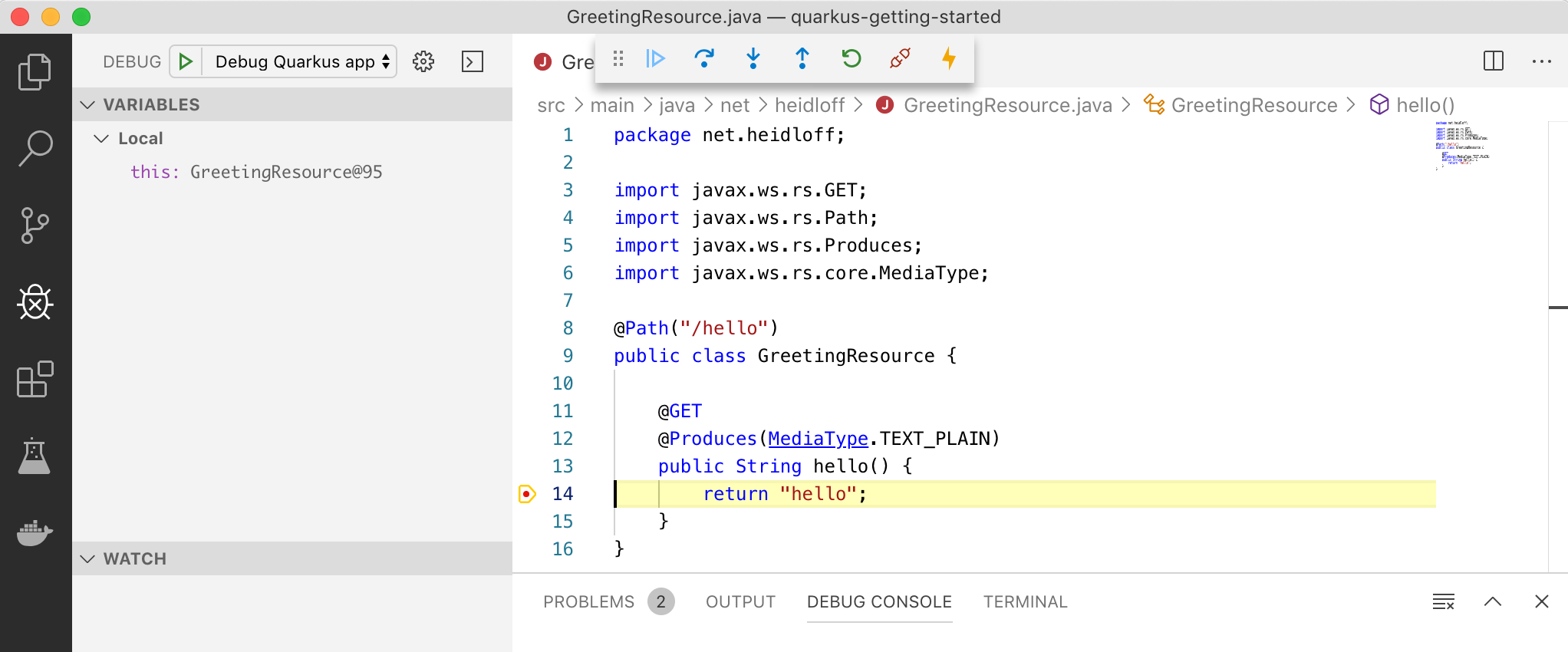
Additionally the VS Code extension supports debugging:

This screenshot shows the debugger in action:
Building Quarkus Images
Before microservices can be deployed to Kubernetes, the Java applications have to be built and the Docker images have to be built.
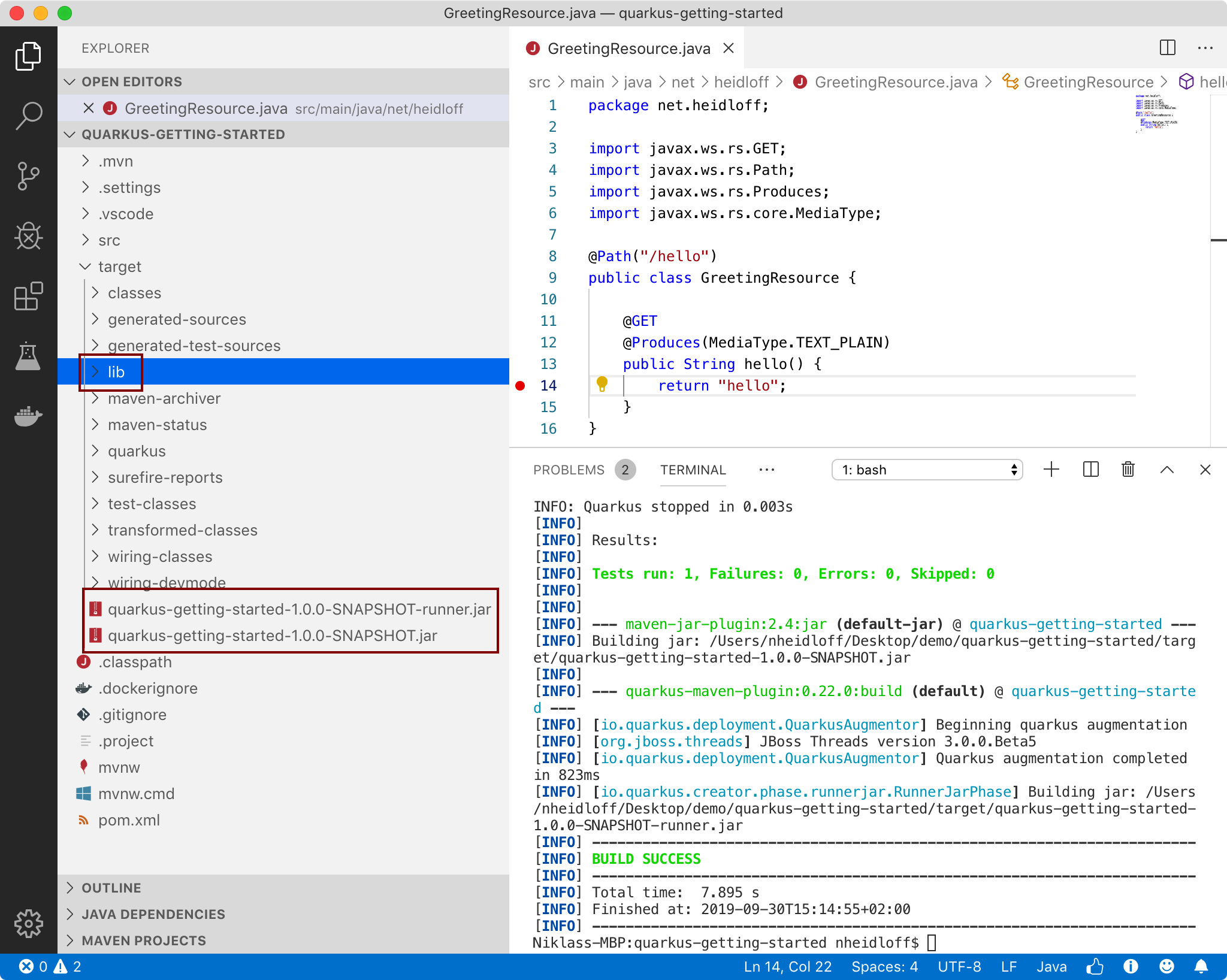
When running Maven via “./mvnw package”, two jar files are created in the /target directory.
- getting-started-1.0-SNAPSHOT.jar: Classes and resources of the projects
- getting-started-1.0-SNAPSHOT-runner.jar: Executable jar. Dependencies are needed additionally (in /target/lib)
The VS Code extension also creates a Dockerfile to run the Quarkus application with Hotspot. However I’ve used OpenJ9 since it consumes only half of the memory. To use OpenJ9, create the file ‘src/main/docker/Dockerfile.jvm-j9’ with the following content.
1
2
3
4
5
FROM adoptopenjdk:8-jre-openj9
RUN mkdir /opt/app
COPY target/lib/* /opt/app/lib/
COPY target/*-runner.jar /opt/app/app.jar
CMD ["java", "-jar", "/opt/app/app.jar"]
To build the images and to run the container locally, run the following commands.
1
2
3
$ docker build -f src/main/docker/Dockerfile.jvm-j9 -t quarkus/quarkus-getting-started-jvm-j9 .
$ docker run -i --rm -p 8080:8080 quarkus/quarkus-getting-started-jvm-j9
$ curl http://localhost:8080/hello
The Quarkus application starts in around 0.7 seconds.

The application requires 32 MB memory.

Next push the image to DockerHub. Replace ‘nheidloff’ with your DockerHub name.
1
2
3
docker tag quarkus/quarkus-getting-started-jvm-j9 nheidloff/quarkus-getting-started-jvm-j9
docker login
docker push nheidloff/quarkus-getting-started-jvm-j9
Deploying Quarkus Images as Serverless Applications
In order to deploy Quarkus microservices as serverless application, you need to install Knative on Kubernetes. One option is to do this locally with Minikube.
I’ve used another option. IBM provides a managed Kubernetes service. To install Knative, you can simply activate it in the user interface. Read the documentation for details.
Before deploying the application, log in to the IBM Cloud.
1
2
3
4
$ ibmcloud login -a cloud.ibm.com -r eu-de -g default
$ ibmcloud ks cluster config --cluster <cluster-name-or-id>
$ export KUBECONFIG=<file-from-previous-command>
$ kubectl get pods
One option to deploy the application is to use yaml files with the custom resources provided by Knative. Another option is to use the Knative CLI (command line interface) kn. In that case you only have to invoke one command.
1
2
$ kn service create quarkus-getting-started --image nheidloff/quarkus-getting-started-jvm-j9
$ kn service list
The screenshot shows the three containers including the Quarkus container running in the same pod. Invocations of the greeting endpoint take between 0.06 and 0.2 seconds dependent on the network.
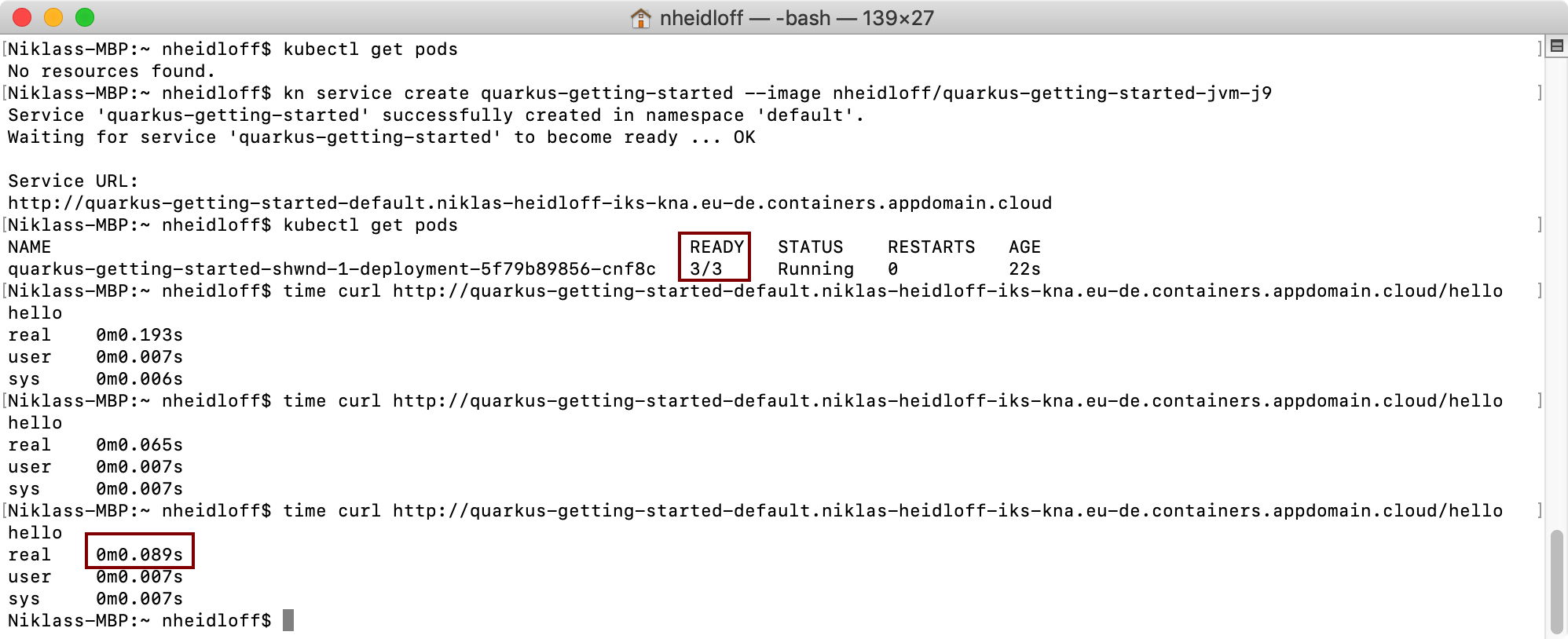
To find out memory usage invoke the following command.
1
2
$ kubectl get pods
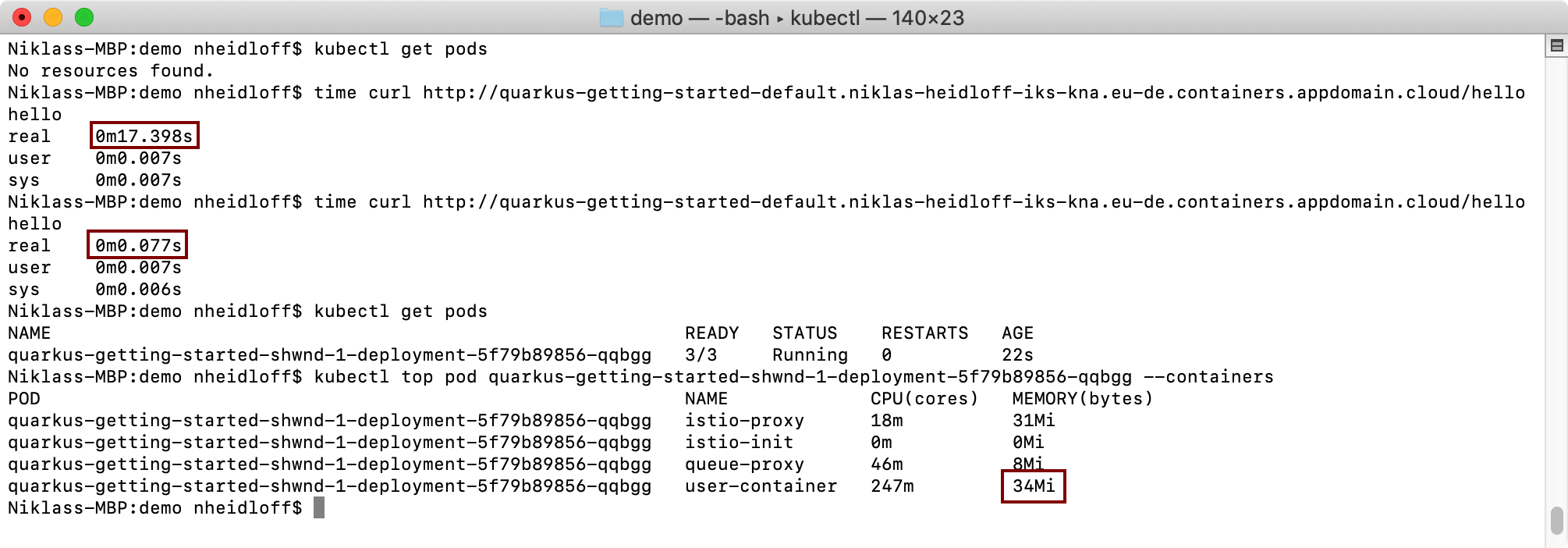
$ kubectl top pod quarkus-getting-started-<your-pod-id> --containers
The Quarkus container with OpenJ9 consumes 34 MB memory. The first time the endpoint was invoked (cold start) took 17 seconds, after this only 0.7 seconds.
Next Steps
I hope you enjoyed this article. To find out more about these technologies, check out the following resources.