
Watson Natural Language Processing Library for Embed is a containerized library designed to empower IBM partners with greater flexibility to infuse powerful natural language AI into their solutions. This post summarizes how sentiment analysis can be done.
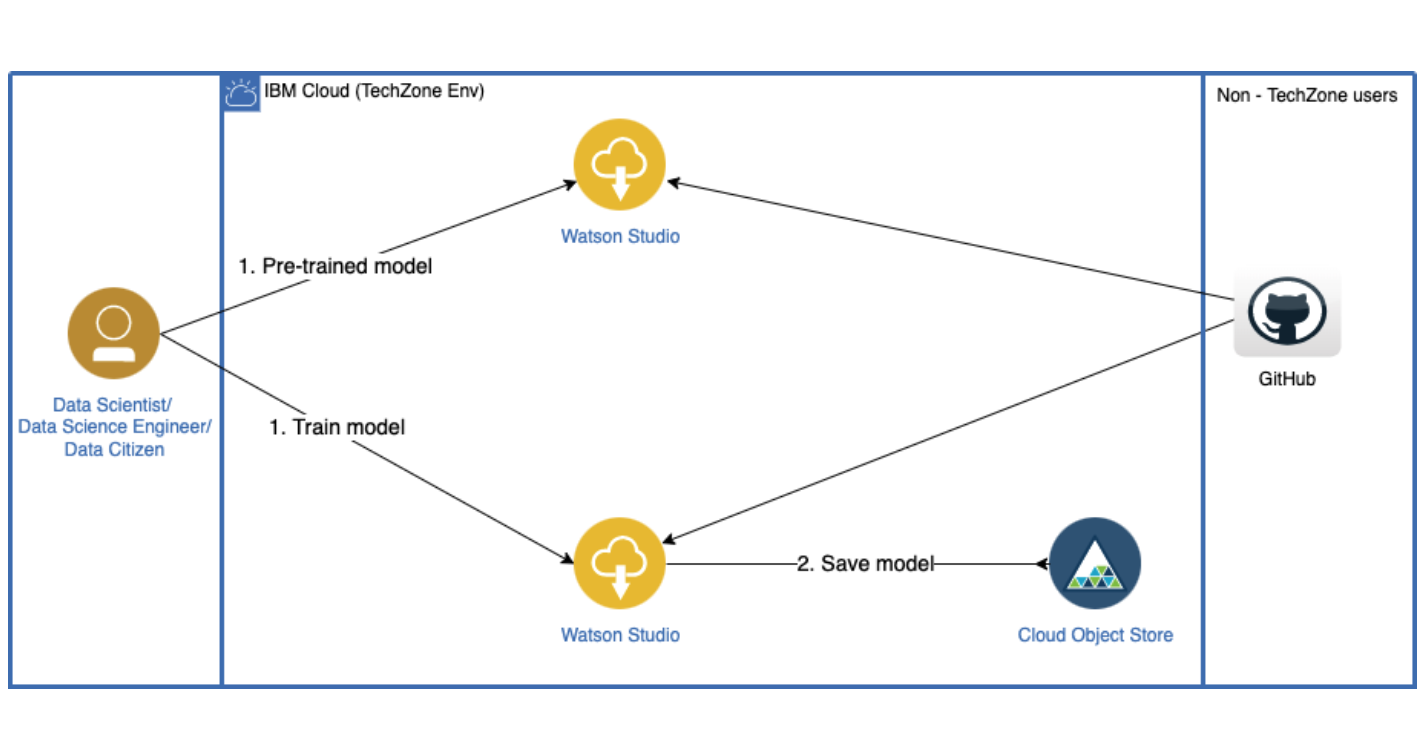
Watson NLP combines the best of open source and IBM Research NLP algorithms to deliver superior AI capabilities developers can access and integrate into their apps in the environment of their choice. Training of custom models can be done in environments like Watson Studio. To run predictions at runtime, Watson NLP can be packaged in containers and invoked via APIs.
Sentiment and Emotion Analysis
One of the most common natural language understanding use cases is sentiment and emotion analysis:
Sentiment is the classification of emotions extracted from a piece of text, speech, or document. While we typically look at emotion to capture feelings, such as anger, sadness, joy, fear, hesitation, sentiment is a higher-level classifier that divides the spectrum of emotions into positive, negative, and neutral.
My colleague Shivam Solanki has written a nice article on IBM Developer which describes how to analyse sentiments. The sample predicts the sentiments of movie reviews based on the IMDB movie reviews data set.
Pretrained Model
The easiest way to get started is to use a pretrained model. Via the syntax model text can be converted, for example to lemmatize words. After this the sentiment model can be used for sentences or complete documents.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import watson_nlp
import watson_nlp.data_model as dm
...
syntax_model = watson_nlp.load(watson_nlp.download('syntax_izumo_en_stock'))
sentiment_model = watson_nlp.load(watson_nlp.download('sentiment-aggregated_cnn-workflow_en_stock'))
...
def extract_sentiment(review_text):
# converting review text into lower case
review_text = review_text.lower()
syntax_result = syntax_model.run(review_text, parsers=('token', 'lemma', 'part_of_speech'))
# run the sentiment model on the result of the syntax analysis
sentiment_result = sentiment_model.run(syntax_result, sentence_sentiment=True)
document_sentiment = sentiment_result.to_dict()['label']
sentence_sentiment = [(sm['span']['text'], sm['label']) for sm in sentiment_result.to_dict()['sentiment_mentions']]
return (document_sentiment, sentence_sentiment)
As you can see in the sample notebook the overall micro precision and recall values are 0.81 each. This has been achieved by evaluating a pretrained model without training it on the IMDB Movie reviews dataset.
Additionally aspect-oriented sentiment analysis is supported which handles cases like “The served food was delicious, yet the service was slow.” which contain positive and negative sentiments in one sentence.
Fine-Tuning Models
If you want a better performance or custom model, you can look at a second notebook that shows how to fine-tune/re-train a pretrained sentiment analysis BERT model from the Watson NLP library on the same dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from watson_nlp.workflows.document_sentiment import BERT
from watson_nlp.toolkit import bert_utils
...
pretrained_model_resource = watson_nlp.load(watson_nlp.download("pretrained-model_bert_multi_bert_multi_uncased"))
sentiment_model = watson_nlp.download_and_load('sentiment-aggregated_cnn-workflow_en_stock')
syntax_model = watson_nlp.load(watson_nlp.download('syntax_izumo_en_stock'))
syntax_lang_code_map = {"en": syntax_model}
...
bert_workflow = BERT.train(
train_file,
test_file,
syntax_lang_code_map,
pretrained_model_resource,
label_list=['negative', 'neutral', 'positive'],
...
keep_model_artifacts=True)
This second notebook demonstrates how to fine-tune/re-train the BERT sentiment workflow using compression. The model performance has improved over out-of-the-box pre-trained model where accuracy was 87% and which is now 96% with the fine-tuned model.
What’s next?
To find out more about Watson NLP, check out the Guide to IBM Watson Libraries