
Developing high quality software is not trivial and not cheap. To help developers, there are several attempts to leverage AI and special foundation models optimized for source code. This post gives a quick overview of popular projects with a focus on an open source project from IBM.
While there is a lot of buzz around ChatGPT, it is not the only AI based technology to help writing source code. GitHub’s Copilot is another popular option which uses the same underlaying Codex family of models. There is also a very interesting effort IBM is working on, called Project Wisdom, as well as several other activities from tech companies like Google.
Legal Implications
There is a debate going on whether and under which rules these tools can be used. As some models have been trained with data from GitHub.com, some developers think that this has not been done in compliance with their license terms.
While generative foundation models do not directly copy data, the intensive training (and the potential of overfitting) might lead models to ‘memorize’ data. Because of this grey area, it might be safer for some developers not to use some of these tools and to first consider the potential implications.
Good Examples
There are some incredible examples documented in blogs and on YouTube. Check out the following resources which explain how Kubernetes resources can be generated.
- ChatGPT Tutorial - Use ChatGPT for DevOps tasks to 10x Your Productivity
- Using ChatGPT to learn Kubernetes and OpenShift
As I read in the article How we Build The Software of Tomorrow, the GitHub CEO Thomas Dohmke thinks that in five years 80% of the source code will be written by AI:
Thomas reveals that about 40% of the code, in those files that have Copilot enabled, was written by AI. While that’s an impressive amount of predicted code, he further declares that this number is just the beginning. In fact, the GitHub CEO assumes this percentage will double to 80% in the next five years.
Bad Examples
While the scenarios above are impressive, there are also several scenarios that show the current limitations:
I think the ‘no free lunch’ theorem summarizes the challenges well. For example, to avoid AI software to propose deprecated Ansible modules, you need specialized models or fine-tuned generic models.
It sounds like AI generated code currently significantly helps with generations of boilerplate code and to improve productivity for repetitive tasks. It will be interesting to see how these tools will evolve to handle more sophisticated tasks.
By the way: Since people started to publish ChatGPT answers on StackOverflow that didn’t meet quality standards, StackOverflow banned ChatGPT-generated answers.
Project Wisdom
At the end of 2021 IBM open sourced the CodeNet dataset. As documented there are differentiating features when compared to other similar efforts:
- Data from AIZU Online Judge and AtCoder (not GitHub) available under Apache License v2
- Big dataset: 500 million lines of code; 55 different languages, esp. C++, Python, Java, C, Ruby and C#
- Rich annotations and clean samples
The Google company DeepMind used the same dataset to develop AlphaCode.
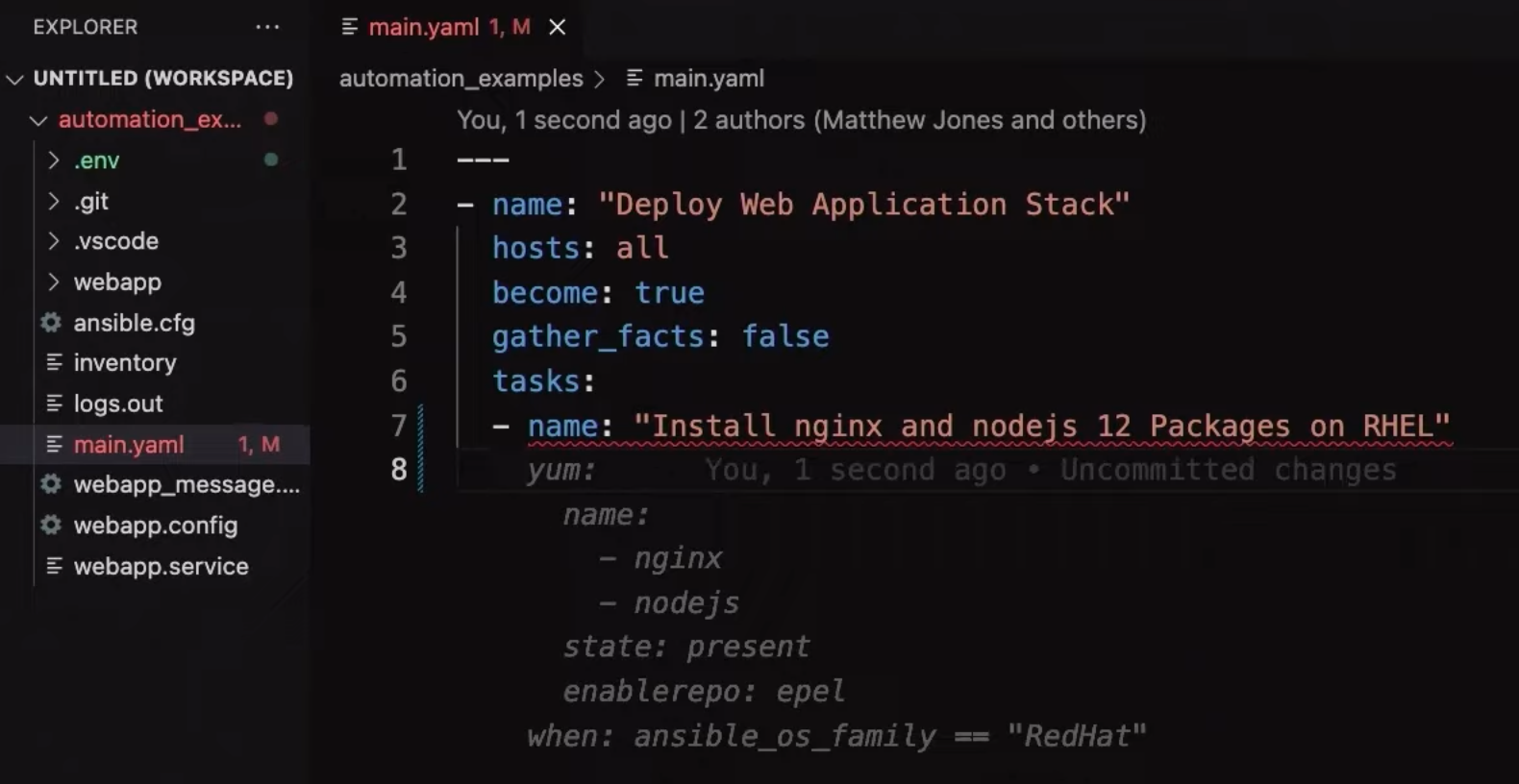
IBM Research and Red Hat built an extension to Visual Studio Code specifically to generate Ansible playbooks based on natural lanuage. Read the article Continuing the momentum of AI for Code with Project Wisdom and watch the demo for details. While Ansible isn’t a classic programming language, it is very similar because of the declarative approach to provision and operate infrastructure resources (Infrastructure as Code).
The following screenshot shows how nginx can be set up. After entering the text ‘Install nginx and nodjs 12 Packages on RHEL’ a proposal of the code is displayed in gray and can be accepted by pressing the tab key.
Summary
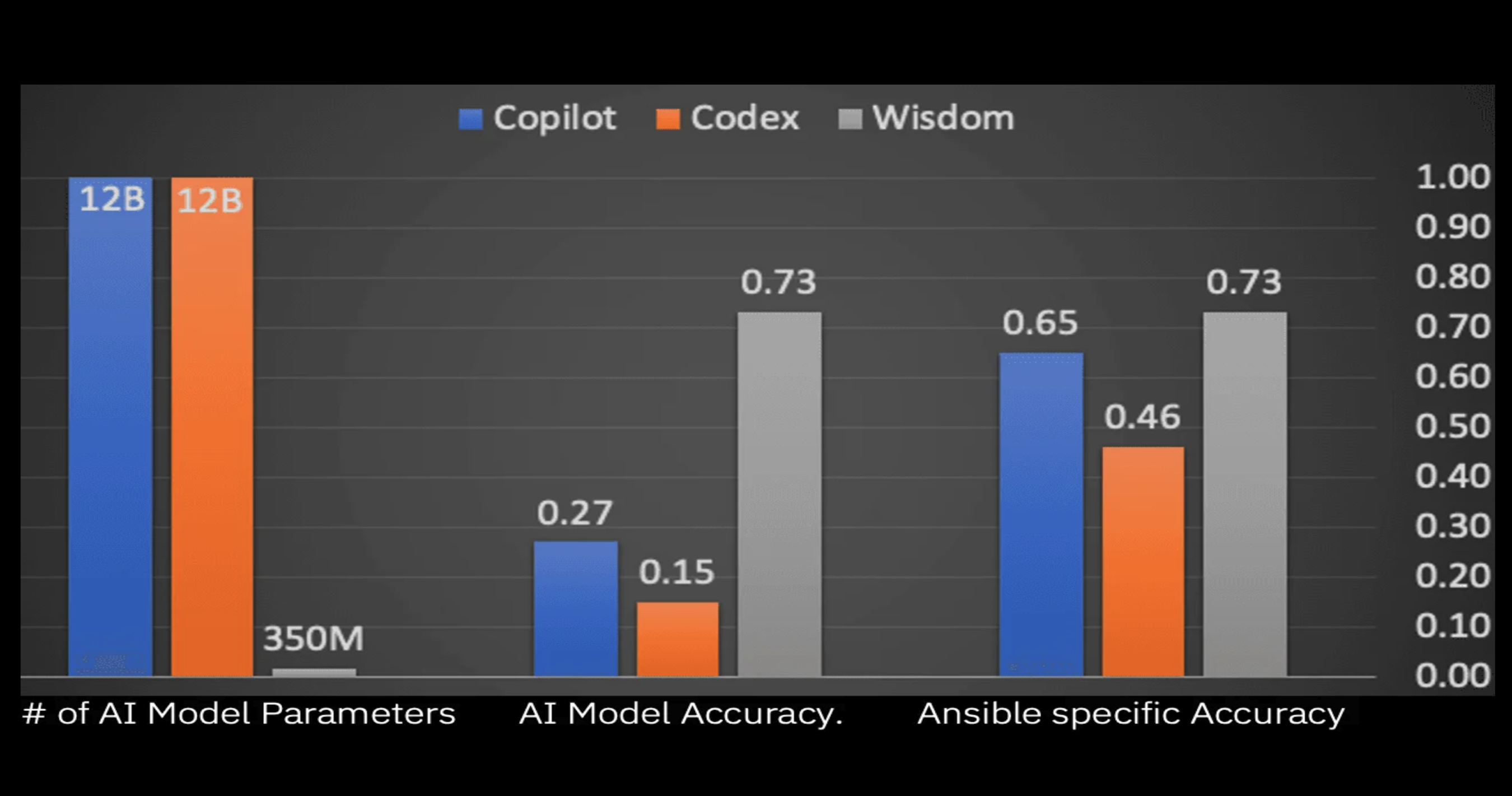
As shown in the image at the top of this article, the model used by Project Wisdom is competitive and in some case even better than the well known Codex model. Note that this comparison is already four months old and things have changed (e.g. Copilot uses Codex now).
For me one key thing is missing in all public demonstrations I have seen so far. As a developer I spend most of my time to set up or configure infrastructure and development environments, to test my code, to build automated CI/CD pipelines, etc. AI needs to support these steps as well. Generating snippets that might or might now work is not that helpful. This is why I like that Sriram Raghavan, Vice President of IBM Research AI, mentioned in an interview that IBM is working on adding these aspects too.