
Model Distillation is a very interesting concept to build small models which are almost as efficient as larger models for specific tasks. This post describes the concept in general and how it can be applied for Large Language Models.
Running or licensing large Large Language Models typically requires many resources and/or money. Additionally, it takes larger models in gernal more time to generate text, simply because they have more parameters. Because of this, activities are going on in the AI community to build smaller, but almost as efficient models.
Previously I wrote about another similar approach Fine-tuning small LLMs with Output from large LLMs. This post explains the alternative Model Distillation.
Knowledge Transfer
The article A Model Distillation Survey describes a great sample how to transfer knowledge from a large to a small model. A large model for image classification is trained with a typical set of training data with labels and 1000 classes. Every item in the training set has exactly one correct label.
The small model is not trained with the same exact data. Instead, it gets the output of the large model which will also provide some wrong labels. The question is why training the small model with partly ‘wrong’ data is still desirable and effective.
The teacher (large) model … will be able to predict a matching class for a new sample, along with scores for each of the 999 remaining classes. The relative probabilities assigned by the teacher (large) model to the other classes express what the model has learned about generalizing on the training data. For example, if the model predicts an image to be a ‘lion’, the probability of the class ‘tiger’ will be higher than the one of the class ‘napkin’ … The student (small) model can learn from the teacher (large) model using all the 1000 probabilities predicted.
Simple Sample
Let’s look at how teachers teach students how to do simple arithmetic tasks, for example:
- Task (data): Anne has 4 apples and gives Peter 2 and Thomas 1. How many apples has she left?
- Answer (label): 1
- Calculation method (rationale): 4 - 2 - 1 = 1
The ‘trick’ is to teach students not only the answers, but also the calculation method.
Large Language Models
For Model Distillation this is called teacher-student architectures, where teachers are the large models and students the small ones. There is a new paper that shows how to apply this technique for Large Language Models.
- Paper: Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
- Video: MedAI #88: Distilling Step-by-Step! Outperforming LLMs with Smaller Model Sizes; Cheng-Yu Hsieh
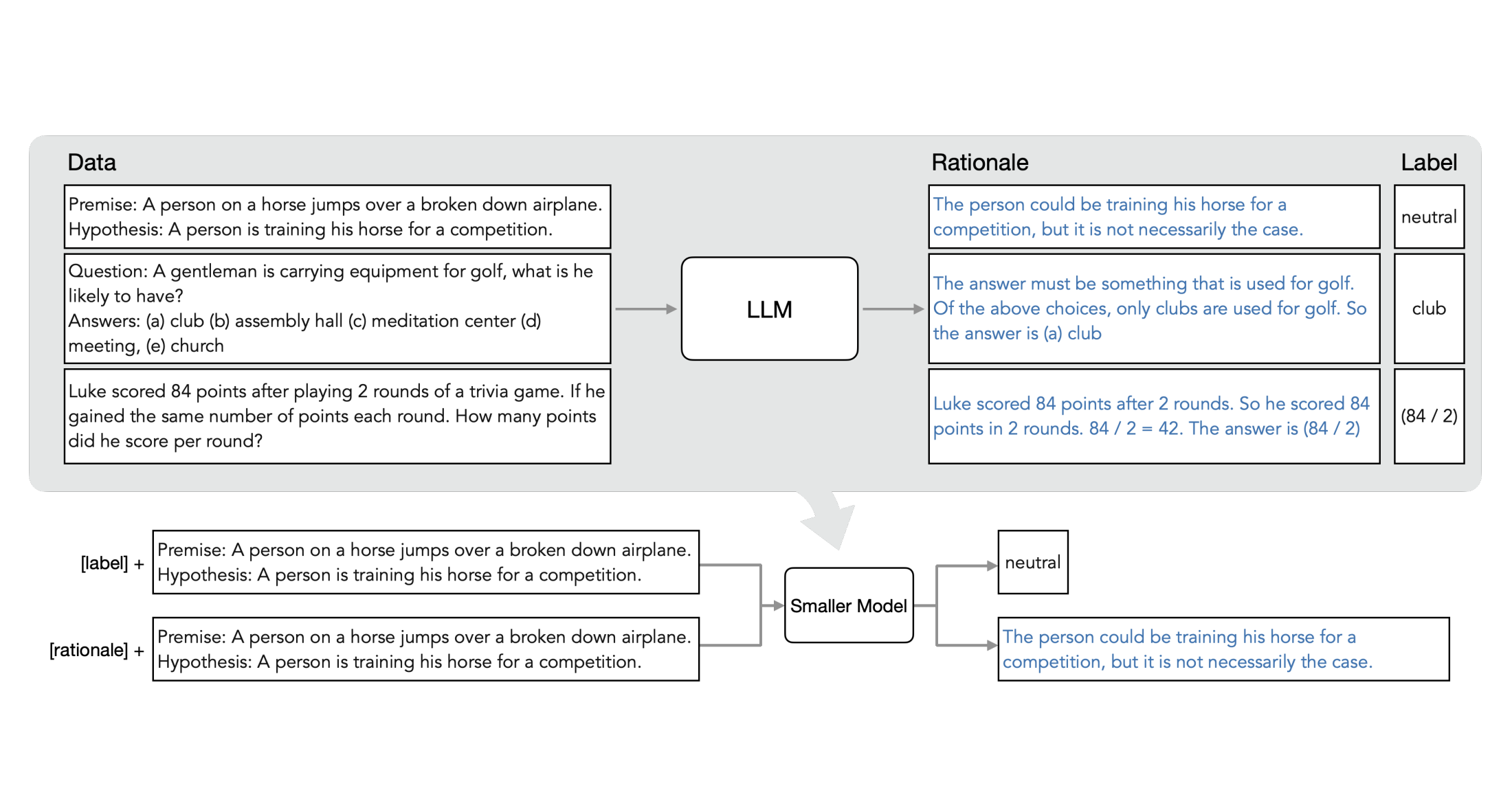
Let me try to summarize via the diagram at the top of this post and let’s start with the gray top row. The large model (teacher) gets data (tasks) as input. It produces an answer (label) and additionally the calculation/solution method (rationale). Example:
- Task (data): Premise: A person on a horse jumps over a broken down airplane. Hypothesis: A person is training his horse for a competition.
- Answer (label): neutral
- Solution method (rationale): The person could be training his horse for a competition, but it is not necessarily the case.
To train the small model conceptionally the authors use the data as well as the rationale as input and the label as output. In the video they mention this as option, which has the disadvantage that at test time you’d need the large model to produce the rationales.
Instead, the authors utilize multi-task training which is the row at the bottom of the diagram. One task produces labels, the other one rationales. To instruct the model to perform these two tasks, they simply prepend the fixed texts ‘[label]’ and ‘[rationale’] to the actual data and pass both in as input. The model will produce the two different outputs per data item which are related to each other.
Performance
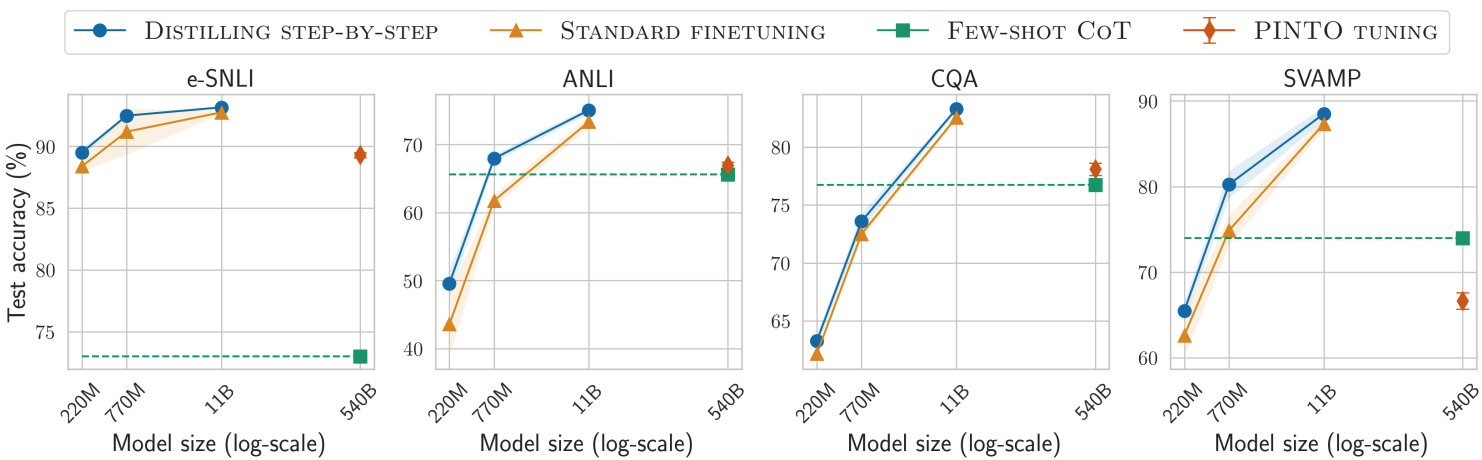
The results are amazing. Smaller models can perform even better than larger models because they are specialized on certain tasks. The next graphic uses Chain of Thought prompting with a 540b PaLM model as the green line. The smaller models are tuned versions of T5 in different sizes. Both the classic fine-tuning and the new distillation fine-tuning can perform better even for much smaller models and distillation fine-tuning provides a better performance than classic fine-tuning.
Distilling step-by-step is able to outperform LLM baselines by using much smaller models, e.g., over 700× smaller model on ANLI. Standard finetuning fails to match LLM’s performance using the same model size.
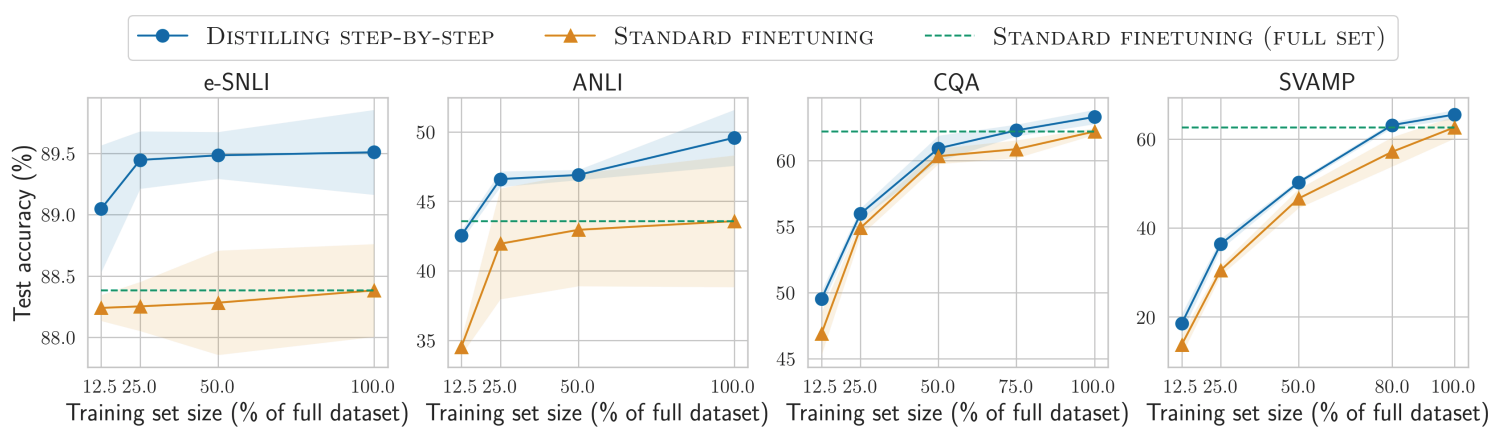
The other benefit is that less training data is required.
Distilling step-by-step is able to outperform Standard finetuning, trained on the full dataset, by using much less training examples (e.g., 12.5% of the full e-SNLI dataset).
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.