
Many of the leading Large Language Models only support limited languages currently, especially open-source models and models built by researchers. This post describes some options how to get these models to generate text in German.
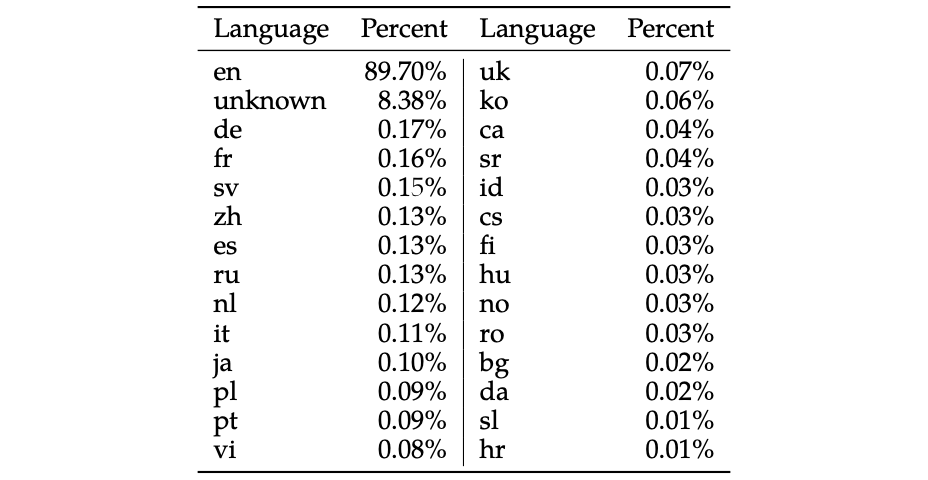
LLaMA 2 has been trained on 2 trillion tokens. As shown in the graphic at the top of this post, most data was English (90%), followed by code (8%), followed by all other 22 languages (2%). German is on number three with 0.17%. The model card describes usage in other languages than English as out-of-scope. Similar restrictions apply to many other models.
There are different theoretical solutions:
- Hope and wait that the original authors will support more languages
- Hope that people from the community will provide fine-tuned versions
- Fine-tune the models yourselves
- Use prompt engineering
English Prompt
The easiest solution is prompt engineering. While it’s not clear for which models, for which scenarios and if this works at all, it’s relatively easy to test. Some people claim that even only 0.17% of the 2 trillion tokens are enough.
One option is to simple prepend ‘Answer in German’ to the long LLaMA chat default prompt.
1
2
3
4
5
6
7
Answer in German. You are a helpful, respectful and honest assistant. Always answer as helpfully
as possible, while being safe. Your answers should not include any harmful,
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure
that your responses are socially unbiased and positive in nature. If a question
does not make any sense, or is not factually coherent, explain why instead of
answering something not correct. If you don’t know the answer to a question,
please don’t share false information.
When using this for Retrieval Augmented Generation where searches are performed first and the search results are passed as context in the other language to the model, the quality looks promising, but might not be good enough for your scenarios. For enterprise applications, for example chat bots, in many cases it is not good enough. I have seen Denglish sentences and several grammar errors. In some cases models even came up with ‘German’ words which do not exist.
German Prompt
Another option is to translate the same prompt in German.
1
2
3
Sie sind ein hilfsbereiter, respektvoller und ehrlicher Assistent. Antworten Sie immer so hilfreich
wie möglich und gleichzeitig sicher. Ihre Antworten sollten keine schädlichen,
unethische, rassistische, ...
So far for me these results look good, but not as good as the English prompt. It also depends heavily on the model. My assumption is that this happens, since models have been trained with certain prompts/instructions in English primarily.
Other Languages
While these simple mechanisms might work well enough for your scenarios, it might not work for other languages. The video LLaMA2 for Multilingual Fine Tuning? explains how tokenizers work (see Colab).
For English, German and French similar amounts of tokens are generated. For other languages like Chinese and Greek many more tokens are generated. This might mean that the ‘mapping’ between tokens in different languages might work less efficient.
1
2
3
4
5
6
7
8
9
10
11
12
13
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", use_auth_token=True,)
tokenizer.tokenize('My name is Sam')
['▁My', '▁name', '▁is', '▁Sam']
# French
tokenizer.tokenize('mon nom est Sam')
['▁mon', '▁nom', '▁est', '▁Sam']
# Greek
tokenizer.tokenize('Το όνομα μου είναι Σαμ')
['▁', 'Τ', 'ο', '▁', 'ό', 'ν', 'ο', 'μ', 'α', '▁', 'μ', 'ο', 'υ',
'▁', 'ε', 'ί', 'ν', 'α', 'ι', '▁', 'Σ', 'α', 'μ']
Fine-tuning
On Hugging Face new fine-tuned models for other languages are published often. Here are the German versions of LLaMA.
However, consider the following topics when choosing the models:
- What data has been used? The effectiveness of fine-tuning depends on the quality of the training data.
- Which exact model version has been fine-tuned?
- Could further fine-tuning have overwritten behavior of the base models?
- How have the licenses and terms changed?
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.