
Llama Stack is an open-source effort from Meta that aims to standardize the core building blocks for AI application development. This post describes how to get started with the stack running on desktop machines.
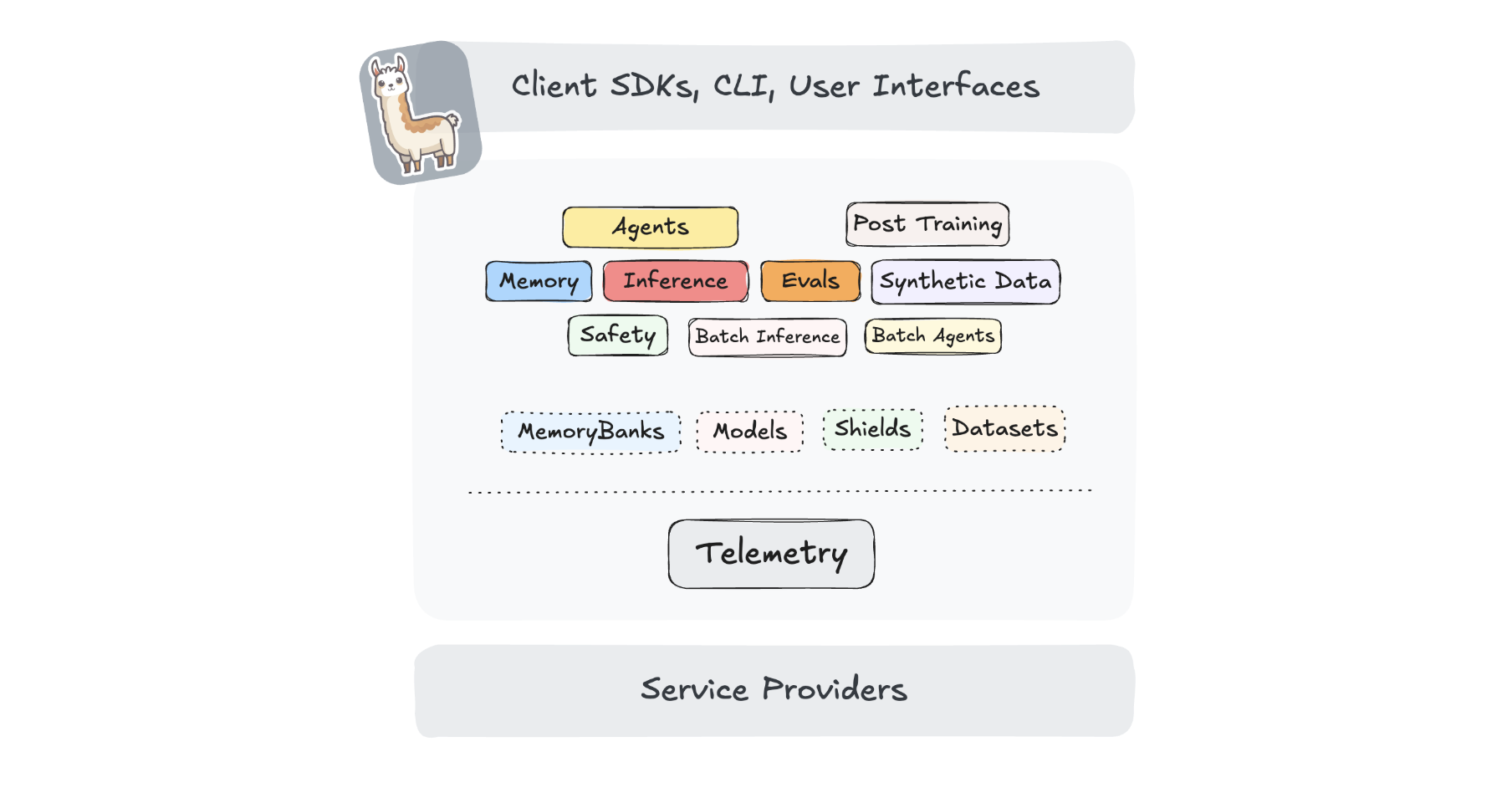
Llama Stack defines and standardizes the core building blocks needed to bring generative AI applications to market. It provides a unified set of APIs with implementations from leading service providers, enabling seamless transitions between development and production environments. More specifically, it provides:
- Unified API layer for Inference, RAG, Agents, Tools, Safety, Evals, and Telemetry
- Plugin architecture to support the rich ecosystem of implementations of the different APIs in different environments
- Prepackaged verified distributions
- Multiple developer interfaces
Here are some resources:
Introduction
To me Llama Stack is for AI development what J2EE is for Java development. The Java community agreed on common specifications for typical enterprise scenarios. Different providers like IBM were able to provide their own implementations of the specifications in addition to simpler reference implementations. This allowed the community to grow faster since the same skills could be leveraged for different providers.
The Llama Stack also defines an architecture with some key components. Implementations can be replaced. For example, you can use the Meta guardian models or implementations from other providers. Similarly to J2EE there are different distributions of the stack from different providers.
I like the following statement which describes the purpose of this effort:
“By reducing friction and complexity, Llama Stack empowers developers to focus on what they do best: building transformative generative AI applications.”
Setup
Run the following commands to run Llama Stack and a local model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
export INFERENCE_MODEL="meta-llama/Llama-3.2-3B-Instruct"
export OLLAMA_INFERENCE_MODEL="llama3.2:3b-instruct-fp16"
ollama run $OLLAMA_INFERENCE_MODEL --keepalive 60m
mkdir ~/.llama
wget https://raw.githubusercontent.com/meta-llama/llama-stack/cd40a5fdbfee6f5da17fb943526fb436eee757d1/llama_stack/templates/ollama/run.yaml
export LLAMA_STACK_PORT=5001
podman run \
-it \
-p $LLAMA_STACK_PORT:$LLAMA_STACK_PORT \
-v ~/.llama:/root/.llama \
-v ./run.yaml:/root/run.yaml \
llamastack/distribution-ollama \
--yaml-config /root/run.yaml \
--port $LLAMA_STACK_PORT \
--env INFERENCE_MODEL=$INFERENCE_MODEL \
--env OLLAMA_URL=http://host.docker.internal:11434
Simple Sample
The following snippet invokes a model.
1
2
3
4
5
6
7
8
9
10
11
from llama_stack_client import LlamaStackClient
client = LlamaStackClient(base_url="http://localhost:5001")
response = client.inference.chat_completion(
model_id="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about coding"}
]
)
print(response.completion_message.content)
When running it locally with Ollama, not all capabilities are supported yet.
Next Steps
Check out the Llama Stack Playground to try more features.