
The Chinese startup DeepSeek open-sourced their reasoning model DeepSeek-R1 and created several smaller distilled versions. This post summarizes some of the key concepts how the new models have been created.
DeepSeek has ‘open-sourced’ their new Reasoning Models which provide great performances. The smaller versions are very fast and efficient and require less infrastructure compared to other state-of-the-art models.
The models are available under the MIT license, the weights can be downloaded and a high-level paper describes the methodology. The models can be fine-tuned and used to generate data for other models. Unfortunately, the data which was used for the Supervised Fine-Tuning and the Distillation is not shared and the Reinforcement Learning documentation only gives some hints how it has been implemented.
Resources
There are many good videos and blogs that describe DeepSeek-R1. Here are some of my favorites:
- DeepSeek Paper
- AMAZING DeepSeek R1-Distill-Qwen-32B: Reasoning SLM explained (Discover AI)
- DeepSeekR1 - Full Breakdown (Sam Witteveen)
- DeepSeek R1 Coldstart: How to TRAIN a 1.5B Model to REASON (Chris Hay)
- The Industry Reacts to DeepSeek R1 - “Beginning of a New Era” (Matthew Berman)
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (Yannic Kilcher)
Models
There are several different models that were utilized to build the new reasoning models.
DeepSeek-V3-Base is the base model for DeepSeek-R1. It is a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37b activated for each token. It has been pretrained on 14.8 trillion diverse and high-quality tokens. The documentation states that ‘DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training’.
DeepSeek-V3 is an improved version of DeepSeek-V3-based based on knowledge distillation from DeepSeek-R1
DeepSeek-R1-Zero is the first version of the new reasoning family. It skipped the initial Supervised Fine-Tuning and used Reinforcement Learning only. While this works to some degree there are challenges such as endless repetition, poor readability and language mixing.
DeepSeek-R1 is the reasoning model with the better performance. It has the same number of parameters as the base model DeepSeek-V3-Base (671B total parameters with 37b activated).
DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Llama-70B and four more distilled models (1.5B, 7B, 8B, 14B, 32B, 70B) are based on Qwen and Llama.
Chain-of-Thought Reasoning
After the pre-training of DeepSeek-V3-Base, the model needs to start learning Chain-of-Thought Reasoning. The paper states that fine-tuning is run with only thousands of cold-start data items. The paper doesn’t state how this has been done, and the final data is not shared.
Last year DeepSeek published another paper about how to leverage mathematical reasoning. Training models with lots of code has also been successful to improve reasoning capabilities for other models. It sounds like this technique could have been applied here as well. The trick is how to come up with a list of mathematical tasks and reasoning that describes how the solution has been found.
My colleague Chris Hay describes in his video how this could be done in a simple way. Mathematical questions like “44 + 41 + 25” can easily be generated with additional text around them, for example “What’s 44 + 41 + 25?” and results can be calculated using classic algorithmic code.
This data can be the input for prompts to larger teacher models which generate the reasoning that leads to the answers:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
For the problem "$question", involving the expression "$expression", produce a clear, step-by-step explanation of how the result " $answer " was derived. If any discrepancies are identified, re-calculate and provide the correct steps without referencing prior mistakes or external explanations.
Restate the problem clearly using <think> tags.
Break down the solution into intuitive, logically ordered steps, ensuring all calculations follow proper mathematical principles (e.g., PEMDAS for arithmetic). Use plain language and avoid unnecessary technical jargon.
Conclude the reasoning with the final answer inside <answer> tags.
Include a <verifier_answer> section containing only the result, formatted for automated systems.
All reasoning must be within the <think></think> tags, no reasoning should occur outside those tags
<think>
Problem: $question
Reasoning:
1. Start with the expression.
2. Explain and solve step by step
3. Conclude with the final result based on the above steps.
Recheck the steps, and answer if there is a discrepancy
</think>
<answer>final answer</answer>
<verifier_answer>clean answer used for verification</verifier_answer>
Note: This prompt teaches the model how to do chain-of-thought reasoning.
Note: The last tag ‘verifier_answer’ includes the answer in a format that is easy to read. This allows comparing the generated answer easily with the read answer classic algorithmic code can calculate.
Note: ‘Recheck the steps’ supports Self-Reflection in which case the model can improve its own first answer.
Here is an example. This generated data can be the input for the first round of supervised fine-tuning.
1
2
3
4
5
6
7
8
9
10
11
12
13
{ "messages": [
{ "role": "user", "content": "What's 44 + 41 + 25?"},
{"role": "assistant", "content": "
<think> \nProblem: What's 44 + 41 + 25? \n
Reasoning: \n 1. Begin with the given expression: 44 + 41 + 25 \n2. Add the
first two numbers, 44 and 41: 44 + 41 = 85 \n3. Then add the result to 25: 85
+ 25 = 110 \n4. The result is 110, which should be written in scientific
notation as 1.1E+2 (which means 1.1 times 10^2) \n Recheck the steps, and
confirm there are no discrepancies\n
</think> \n\n
<answer>The final answer is 110.</answer>\n
<verifier_answer>110</verifier_answer>"}
]}
Reinforcement Learning
One of the reasons why the training process of DeepSeek-R1 is efficient, is the way Reinforcement Learning is done. Typically, other LLMs act as judge to define rewards. For cases like mathematical reasoning this is not necessary. Instead, there is a much simpler and cheaper alternative for deterministic results which is classic programming. This works for code as well, which can be executed to test whether it is correct.
In addition to the accuracy reward there are two more rewards for the format and language of the responses to ensure easy programmatic access to the responses and responses with language that people appreciate.
Reasoning for other Domains
After the first round of Fine-Tuning and Reinforcement Learning the model needs to be further improved to also work more generically for other scenarios. This requires labeled data for the second round of Fine-Tuning that covers other domains. The paper describes this briefly:
We expand the dataset by incorporating additional data, some of which use a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment. For each prompt, we sample multiple responses and retain only the correct ones. In total, we collect about 600k reasoning related training samples.
By sampling multiple responses and by running multiple iterations in the training process the model also learns to correct and improve itself. In the paper this phenomenon is referred to as Aha Moment.
For non-reasoning data, such as writing, factual QA, translation, etc. 200k more examples are added to the dataset. This ensures that the original base model doesn’t forget other information and it helps to provide responses that don’t need reasoning. This technique is called Rejection Sampling.
Model Distillation
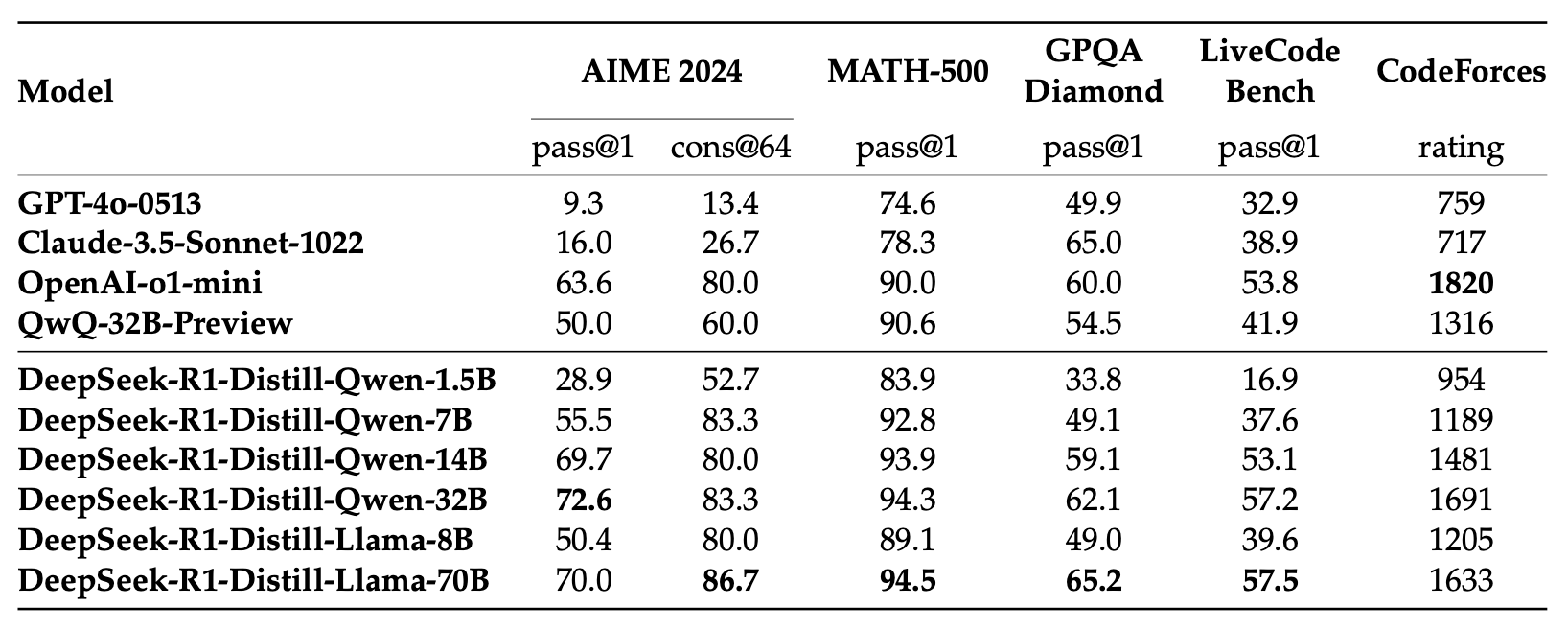
DeepSeek-R1 with 671B parameters and 37b paramters activated is rather large. To improve other smaller models, DeepSeek provides fine-tuned versions of Qwen and Llama. They have been fine-tuned with the same 800k dataset from the previous step. The results are impressive.
Next Steps
Try it out. This command runs the 7B distilled version locally:
1
ollama run deepseek-r1