

Question Answering is one of the most interesting scenarios for Generative AI. While base models have often been trained with massive amounts of data, they have not always been fine-tuned for specific AI tasks. This post describes how to fine-tune models for Question Answering.
Question Answering is a computer science discipline to answer questions in natural language. To avoid hallucination, these systems are often built via Retrieval Augmented Generation where searches are performed first. The search results are passed as context to the Large Language Models to ground the answers on that content.
Fine-tuning models for Question Answering scenarios is not trivial. The main reason is that this is a broad topic, there are many different types of questions and the expectations on the results can vary too.
- Single-turn vs multi-turn conversations
- Type of question: aggregated, ambiguous, direct/indirect, comparative, multiple questions in one, etc.
- How to return “I don’t know” (IDK) if the models don’t know to avoid hallucination
- Types of expected answer: yes/no, short summary, step by step instructions, etc.
Below is code from Hugging Face that shows how to do the fine-tuning, followed by some open datasets.
Fine-tuning
There is a nice Hugging Face tutorial. Let’s look at some key aspects only.
The tiny (67M) DistilBERT model is fine-tuned with the SQuAD dataset (see below) which contains data in this format:
1
2
3
4
5
{
'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
'context': 'Architecturally, the school has a Catholic character. ... the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direc....',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
}
After the fine-tuning you can test your model:
1
2
3
4
5
6
7
8
9
question = "How many programming languages does BLOOM support?"
context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
from transformers import pipeline
question_answerer = pipeline("question-answering", model="my_awesome_qa_model")
question_answerer(question=question, context=context)
{'score': 0.2058267742395401,
'start': 10,
'end': 95,
'answer': '176 billion parameters and can generate text in 46 languages natural languages and 13'}
The answer is not perfect but remember that the original model was only 67M parameters big and only a data set with 5000 rows has been used.
SQuAD
SQuAD (Stanford Question Answering Dataset) is the dataset from above. It comes with sets of questions, answers and context and it comes with samples where models should answer “I don’t know”.
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.

Doc2Dial
Doc2Dial (Document-grounded Dialogue) is a dataset to fine-tune models for Question Answering scenarios where different questions are asked based on the same document.
For goal-oriented document-grounded dialogs, it often involves complex contexts for identifying the most relevant information. […] Thus, we create a new goal-oriented document-grounded dialogue dataset that captures more diverse scenarios derived from various document contents from multiple domains.

QuAC
QuAC (Question Answering in Context) is another grounded dataset with conversations between students and teachers.
QuAC is a dataset for modeling, understanding, and participating in information seeking dialog. Data instances consist of an interactive dialog between two crowd workers: (1) a student who poses a sequence of freeform questions to learn as much as possible about a hidden Wikipedia text, and (2) a teacher who answers the questions by providing short excerpts (spans) from the text.

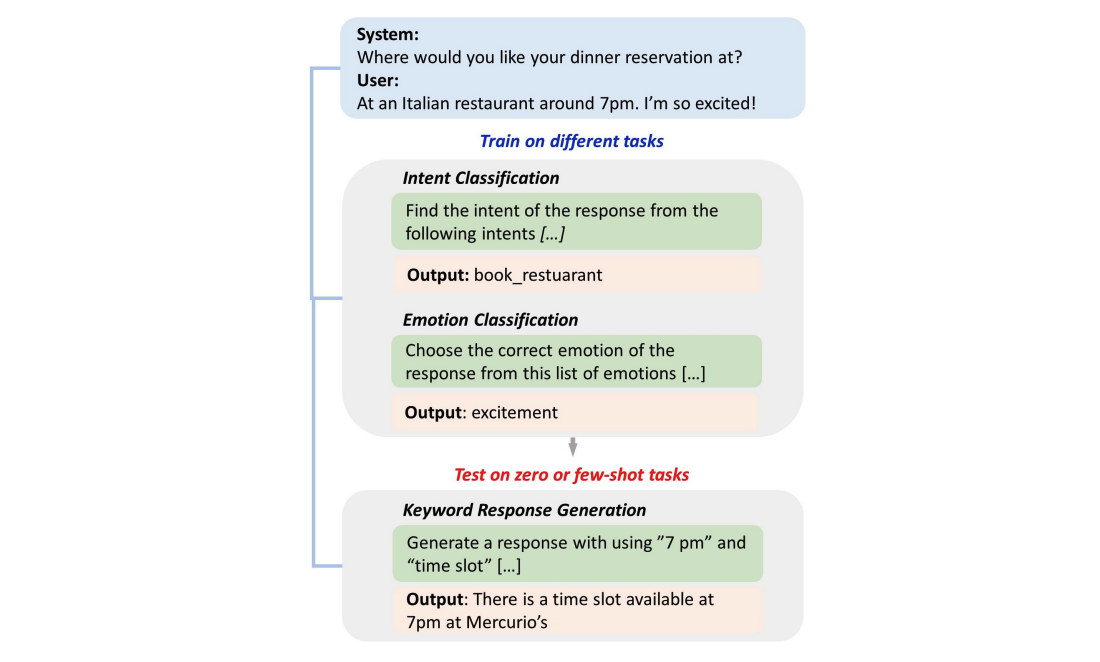
InstructDial
InstructDial (Instruction-based Tuning for Dialogs) is a dataset and methodology how to use instructions to improve zero and few-short generalization for dialogs.
InstructDial is an instruction tuning framework for dialogue, which consists of a repository of 48 diverse dialogue tasks in a unified text-to-text format created from 59 openly available dialogue datasets. Next, we explore cross-task generalization ability on models tuned on InstructDial across diverse dialogue tasks.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.