
Docling and Langflow are two popular open-source frameworks to extract information from documents and to build agentic applications. This post describes how to leverage Docling within Langflow.
Langflow has more than 120k stars on GitHub:
Langflow is a powerful tool to build and deploy AI agents and MCP servers. It comes with batteries included and supports all major LLMs, vector databases and a growing library of AI tools.
Docling has been the GitHub repository of the day for multiple weeks:
Docling turns messy PDFs, DOCX, and slides into clean, structured data—ready for RAG, GenAI apps, or anything downstream. Complex layouts? Tables? Formulas? It handles them, so you don’t have to.
Document Conversions
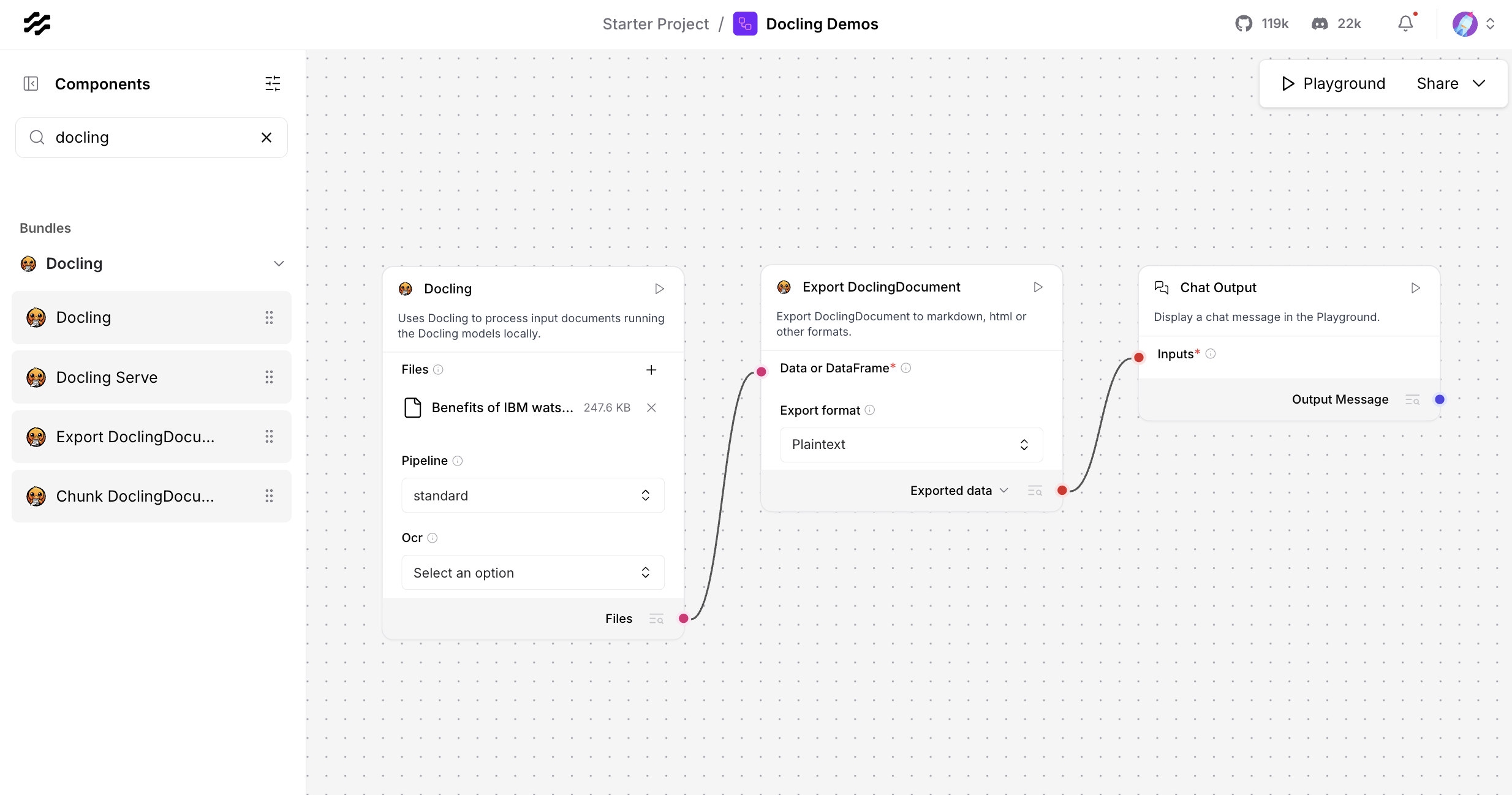
Langflow comes with several Docling components which can be dropped into flows - see image at the top of this post. Note that you need to install Docling first.
The Docling component contains the main functionality to understand documents and to generate output in the Docling Document format.
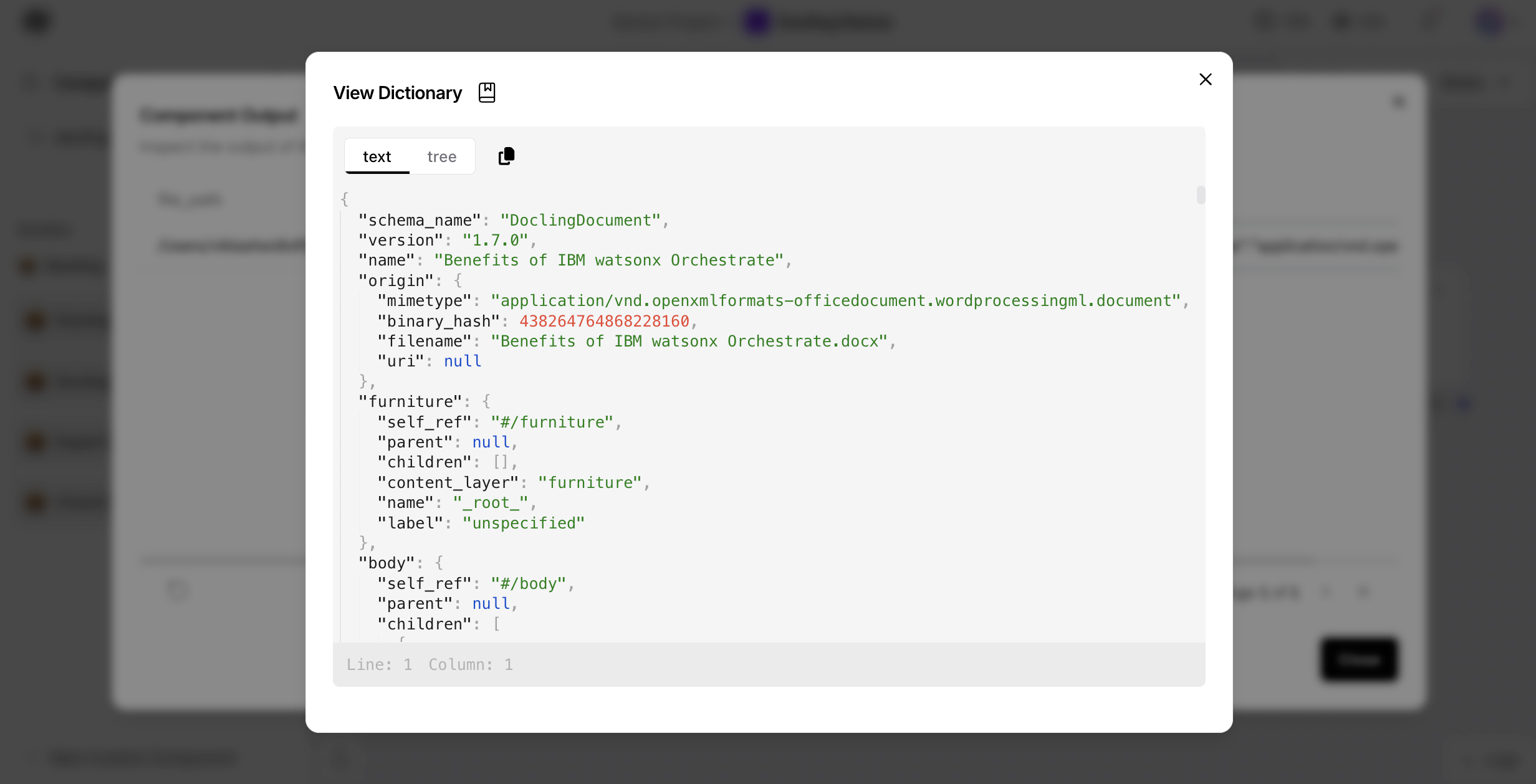
Documents in the Docling Document format can be converted to plain text, Markdown and HTML for further processing. The intermediate Docling Document format is used to avoid information loss.
RAG Preparations
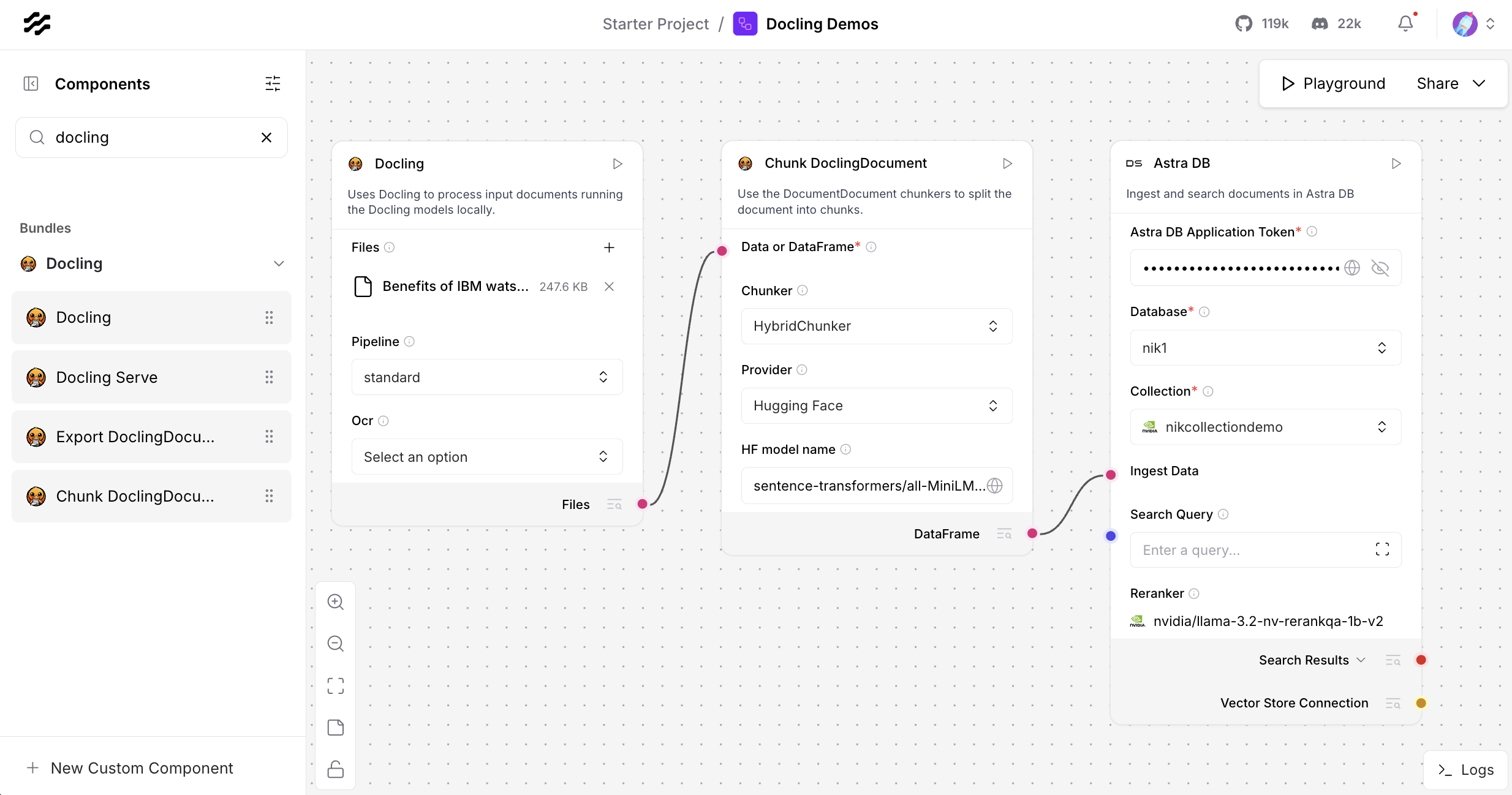
To use semantic searches in RAG (Retrieval Augmented Generation), documents need to be split in chunks first with another Langflow Docling component.
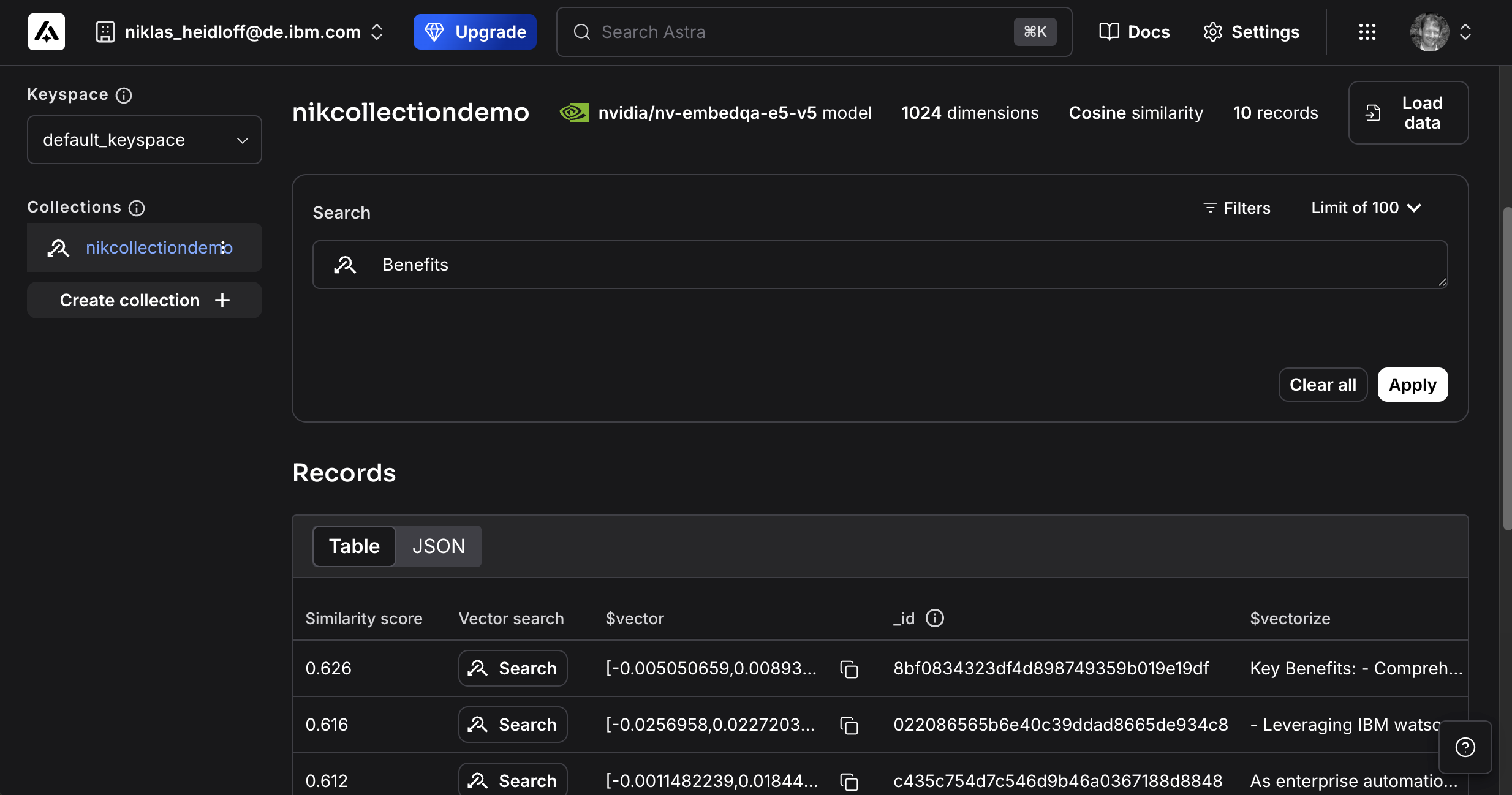
The semantic search database Astra displays the chunks in the admin console after the flow above has been run. Embeddings of the chunks are created automatically.
RAG Retrievals
To run RAG flows user input is sent to Astra.
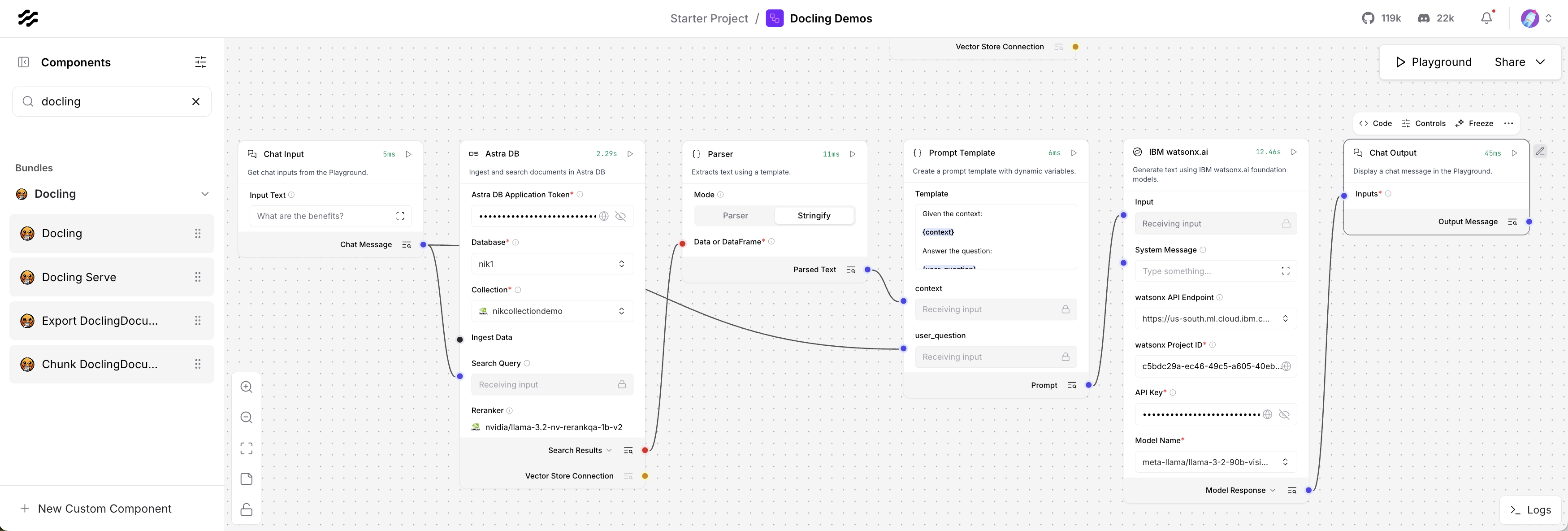
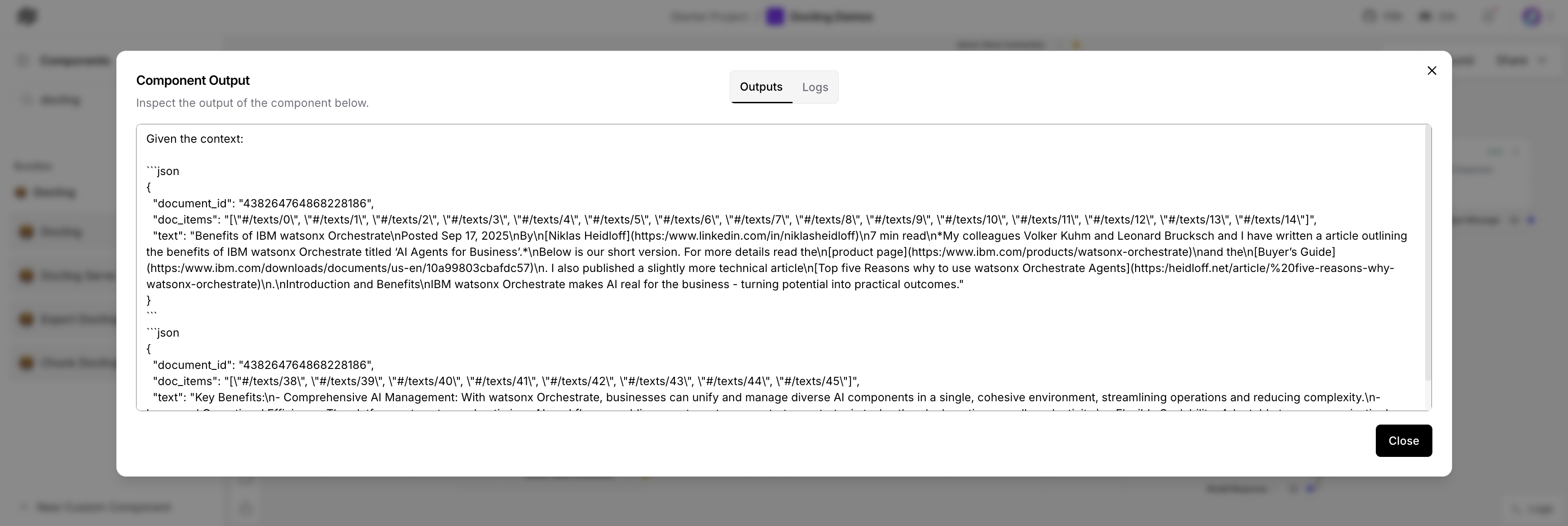
The results are passed as context into a prompt.
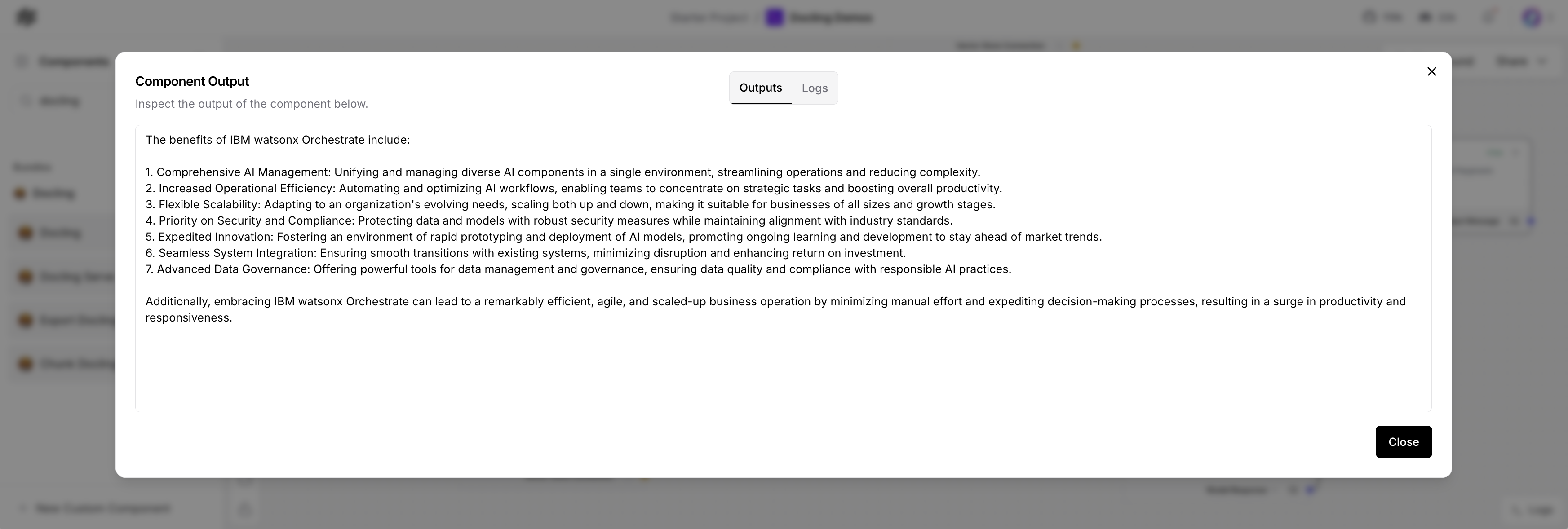
The prompt with the context and the user question is sent to an LLM (Large Language Model) to generate the answer. In my example the benefits of watsonx Orchestrate are summarized for my previous blog post.
Next Steps
To find out more, check out the following resources: