
Fine-tuning Large Language Models requires GPUs. When tuning small and/or quantized models, single GPUs can be sufficient. This post explains how to leverage a Nvidia V100 GPU in the IBM Cloud.
Overview
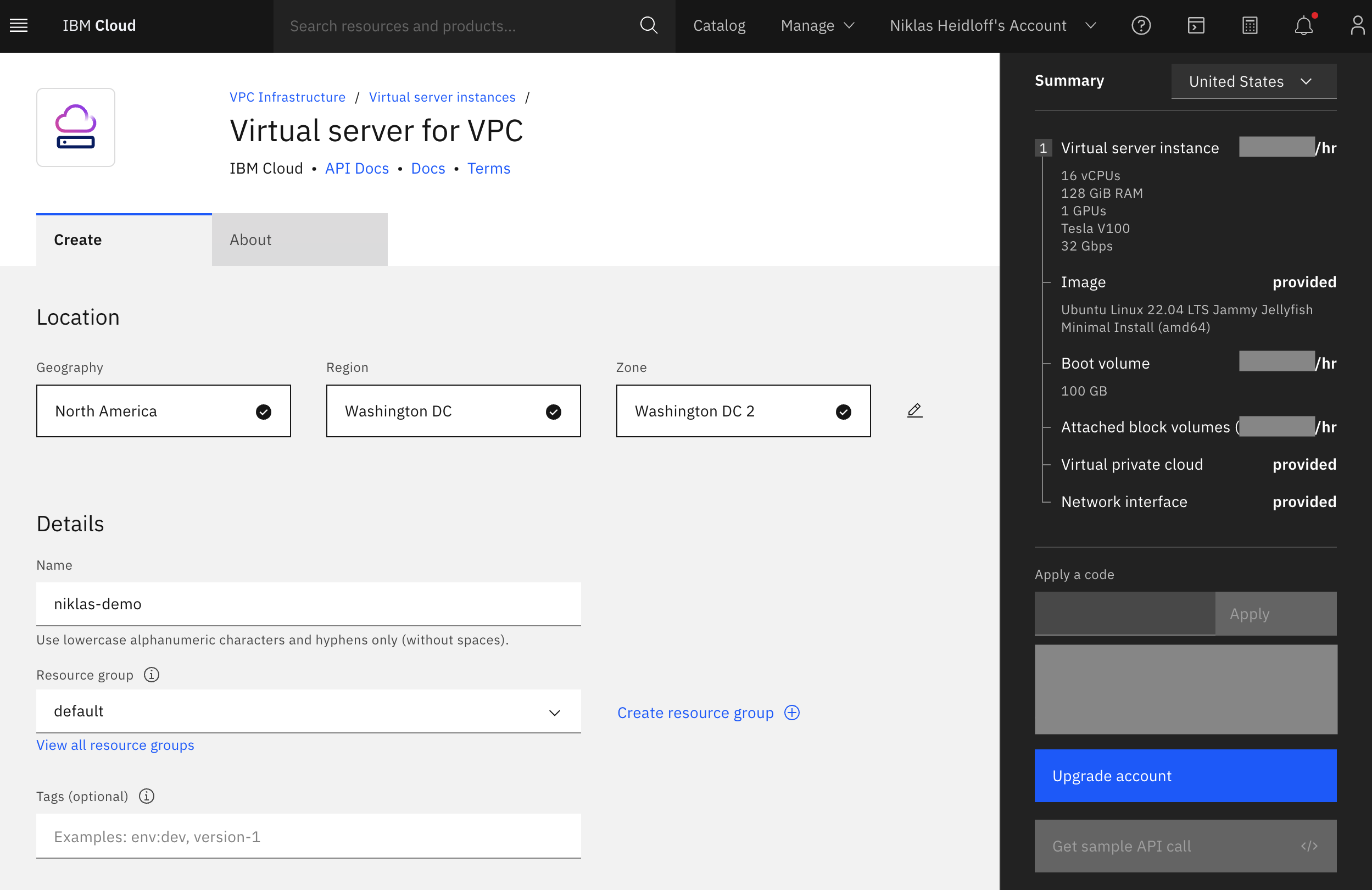
The Nvidia V100 GPU has 16GB in the IBM Cloud. You can choose one or two GPUs. Virtual server instances can be deployed easily in the IBM Cloud with GPUs and storage.
- Virtual server instances for VPC
- How to Use V100-Based GPUs on IBM Cloud VPC
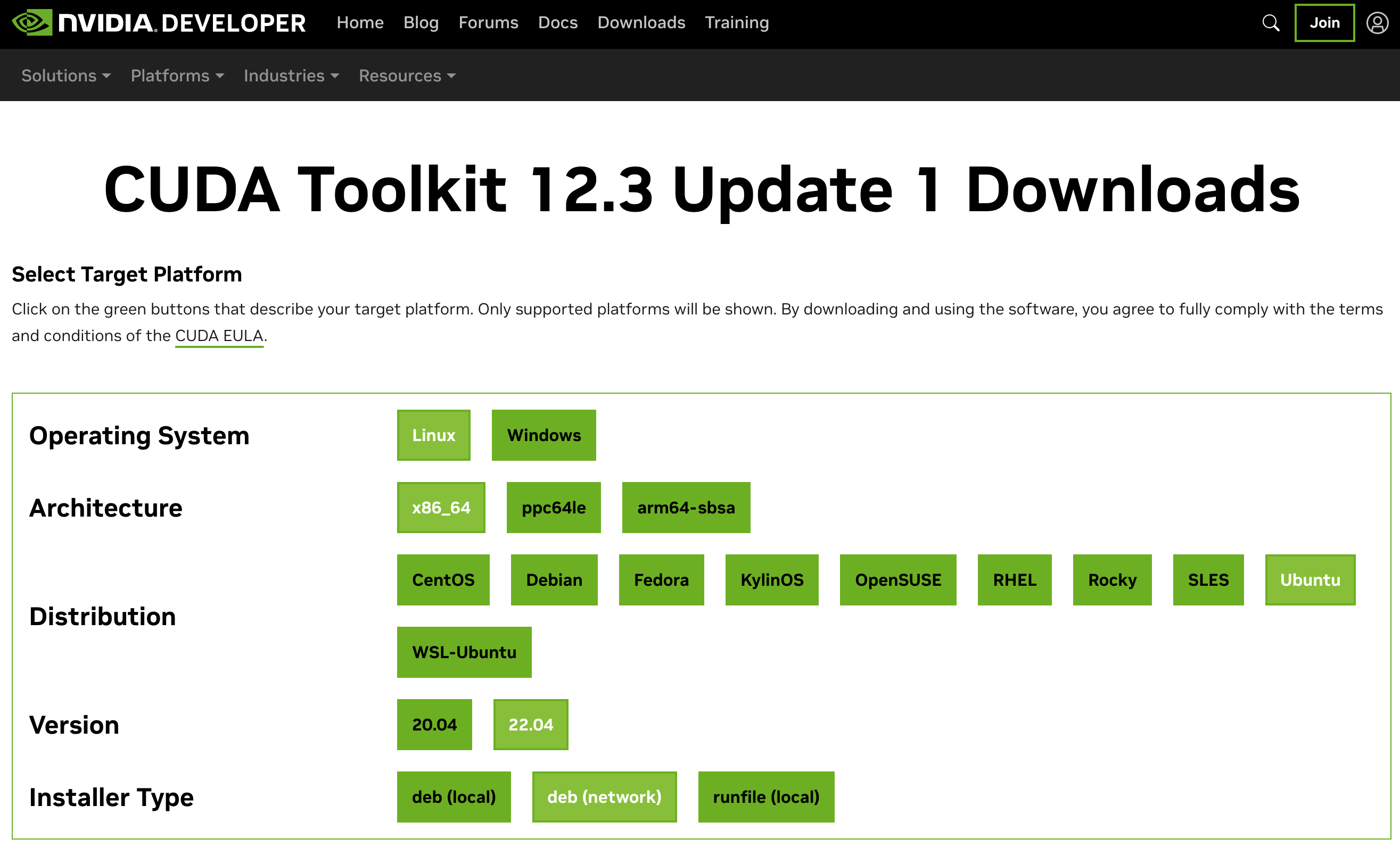
- CUDA Toolkit 12.3 Update 1
- PyTorch Setup
After servers have been provisioned, data can be copied on the servers or read via ‘ssh’ and ‘scp’.
1
2
3
ssh -i ∼/.ssh/gpuadmin-id root@xxx.xxx.xxx.xxx
scp -i ∼/.ssh/gpuadmin-id -r ground-truth.xlsx root@xxx.xxx.xxx.xxx:/gpu-disc/
scp -i ∼/.ssh/gpuadmin-id -r root@xxx.xxx.xxx.xxx:/gpu-disc/results .
Configuration
Before the GPU can be leveraged, it needs to be configured. Follow the instructions in the CUDA Toolkit documentation. Choose the ‘network’ option to make sure to get the latest versions and choose the ‘open kernel module flavor’ for the driver.
To validate that the GPU has been configured correctly, run the following commands.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
root@gpu-server:~# lspci | grep -i nvidia
04:01.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] (rev a1)
root@gpu-server:~# lshw | grep nvidia
configuration: driver=nvidia latency=0
root@gpu-server:~# nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla V100-PCIE-16GB On | 00000000:04:01.0 Off | 0 |
| N/A 37C P0 45W / 250W | 5308MiB / 16384MiB | 22% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 74161 C python3 5304MiB |
+---------------------------------------------------------------------------------------+
After you’ve installed PyTorch, you can check whether the GPU is available from your Python code.
1
2
3
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
print(device)
Troubleshooting
When configuring everything, use the latest versions and validate that only one version is installed. The following commands might help for troubleshooting.
1
2
3
4
5
6
7
accelerate config
apt search nvidia-driver
apt reinstall nvidia-driver-545
apt-get --purge remove "*nvidia*" "libxnvctrl*"
apt-get autoremove
cd /etc/apt/sources.list.d
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.