
The OpenAI API can be considered as de-facto standard for accessing Large Language Models for generations. This post describes how to run a proxy which accepts OpenAI API requests to run models on watsonx.ai.
Several Generative AI frameworks allow plugging in different models and providers. In many cases models need to provide an API with the same interface as the API used by OpenAI.
My colleague Alexander Seelert developed a proxy which provides a ‘/v1/completions’ endpoint and which can be run in a container.
Note: This interface is different from ‘/v1/chat/completions’ which is the successor.
watsonx.ai Proxy
Run the container with Docker or Podman. Define your watsonx.ai API key and project id as environment variables.
1
2
3
4
5
6
podman run -d -p 8080:8000 --name watsonxai-endpoint \
-e WATSONX_IAM_APIKEY=${WATSONX_IAM_APIKEY} \
-e WATSONX_PROJECT_ID=${WATSONX_PROJECT_ID} \
aseelert/watsonxai-endpoint:1.0
podman logs -f watsonxai-endpoint
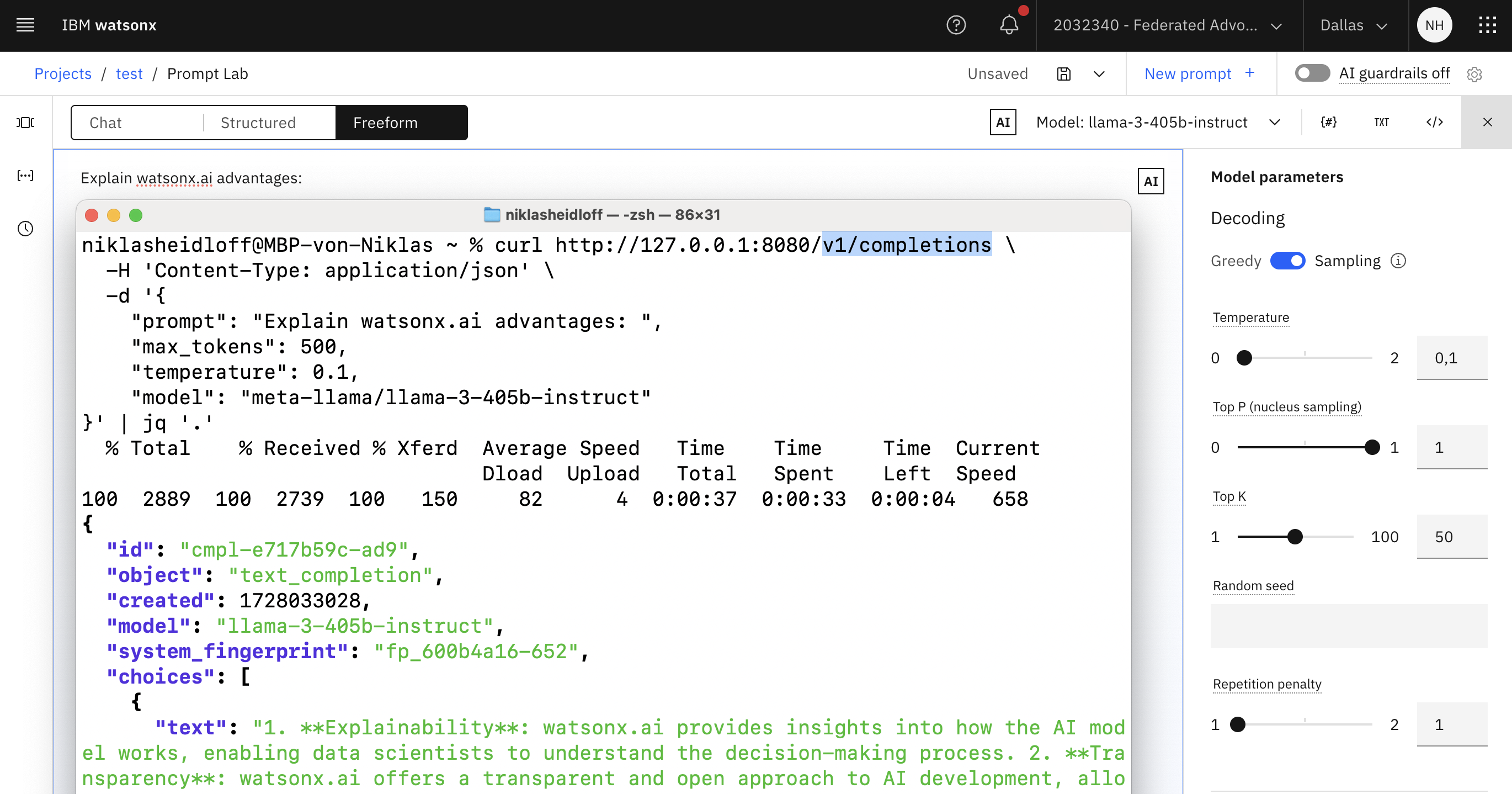
Invoke the endpoint, for example via curl.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
curl http://127.0.0.1:8080/v1/completions \
-H 'Content-Type: application/json' \
-d '{
"prompt": "Explain watsonx.ai advantages: ",
"max_tokens": 500,
"temperature": 0.1,
"model": "meta-llama/llama-3-1-70b-instruct"
}' | jq '.'
{
"id": "cmpl-8ed60033-e0a",
"object": "text_completion",
"created": 1728032293,
"model": "meta-llama/llama-3-1-70b-instruct",
"system_fingerprint": "fp_9deef774-6ec",
"choices": [
{
"text": "1. **Improved Customer Experience**: Watsonx.ai helps businesses ...",
"index": 0,
"logprobs": null,
"finish_reason": "max_tokens"
}
],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 500,
"total_tokens": 509
}
}
InstructLab
InstructLab is an open-source framework to fine-tune smaller generative AI models via a new technique called Large-Scale Alignment for ChatBots.
Models can be fine-tuned with relative little (real) data since additional data is generated synthetically. The teacher models that generate and evaluate this data can be integrated via the /v1/completions endpoint.
The repo watsonx-ai-platform-demos contains examples how to generate data.
1
2
3
4
5
6
7
ilab data generate \
--endpoint-url http://localhost:8080/v1 \
--model meta-llama/llama-3-1-70b-instruct \
--pipeline simple \
--sdg-scale-factor 5 \
--output-dir ./datasets \
--num-cpus 10
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.