
Watsonx.ai provides various Large Language Models and Embedding Models out of the box. Models that are not supported by the watsonx.ai inference stack can be deployed via Python Functions.
Watsonx.ai supports different open-source Large Language Models, Embedding and ReRanker Models, Time Series Models and more.
vLLM is utilized as inference stack. Even if models are not officially supported, they might work on watsonx.ai if they work on vLLM.
Models that don’t run on vLLM can be deployed via Python Functions and AI Services which are like containers. Read my post Deploying Agentic Applications on watsonx.ai.
Embeddings
Embeddings are vector representations of words and are used for semantic searches in RAG and for other similarity searches. For example, ReRankers can help to rank search results in memory after RAG searches to improve the results.
The HuggingFace Leaderbord lists different embeddings models. For different use cases certain embedding models work better than other ones if they are specialized on a certain domain, for example languages.
It can also make sense to fine-tune your own embedding models to optimize the retrieval performance of your RAG application, see Fine-tune Embedding models for Retrieval Augmented Generation.
Let’s look at an example which uses bilingual-embedding-large, a bilingual language embedding model for French and English.
The model is based on an architecture that vLLM does not support.
1
2
3
4
5
6
7
{
"_name_or_path": "dangvantuan/bilingual_impl",
"architectures": [
"BilingualModel"
],
...
}
The code leverages the standard library sentence-transformers.
1
2
3
python3.11 -m venv venv
source venv/bin/activate
!pip install sentence-transformers==3.4.1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Lajavaness/bilingual-embedding-large", trust_remote_code=True)
sentences = [
"Paris est une capitale de la France",
"Paris is a capital of France",
"Niklas Heidloff works for IBM et il aime le développement de logiciels"
]
embeddings = model.encode(sentences)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
#tensor([[1.0000, 0.8833, 0.0802],
# [0.8833, 1.0000, 0.0306],
# [0.0802, 0.0306, 1.0000]])
The result shows that the first two sentences about Paris are more similar than the last sentence.
Deployable Function
This post demonstrates Python Functions . AI Services are more flexible but not supported yet in the software version of watsonx.ai.
Update 12.02.25: AI Services are supported in 2.1.1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def deployable_function():
"""
Deployable Python Function
"""
def score(payload):
from sentence_transformers import SentenceTransformer
try:
model = SentenceTransformer("Lajavaness/bilingual-embedding-large", trust_remote_code=True)
sentences = payload['input_data'][0]['values']
embeddings = model.encode(sentences)
result = []
index = 0
for row in embeddings:
result.append({sentences[index]: str(row)})
index = index + 1
output = {
'predictions': [
{'values': str(result)}
]
}
return(output)
except Exception as e:
return {'predictions': [{'values': [repr(e)]}]}
return score
Notebook
The function can be deployed via REST APIs or Python. Below a notebook is run in a Python environment with CPUs. Note that this environment is different from the one the deployed function will use!

The first part of the notebook sets up credentials.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
!pip install -U ibm-watsonx-ai | tail -n 1
!pip install sentence-transformers==3.4.1
api_key = "xxx"
space_id = "xxx"
from ibm_watsonx_ai import Credentials
credentials = Credentials(
url = "https://cpd-watsonx.apps.fusion-hci.xxx",
username = "xxx",
api_key = api_key,
instance_id = "openshift",
version = "5.0"
)
from ibm_watsonx_ai import APIClient
client = APIClient(credentials)
client.set.default_space(space_id)
After this the function can be invoked directly in the notebook for testing purposes. The example returns the embeddings for the three sentences.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sentences = [
"Paris est une capitale de la France",
"Paris is a capital of France",
"Niklas Heidloff works for IBM et il aime le développement de logiciels"
]
payload = deployable_function()({
"input_data": [{
"values" : sentences
}]
})
print(payload)
# {'predictions': [{
# 'values': "[
# {'Paris est une capitale de la France': '[-0.00971037 0.04192735 0.00290196 ... 0.01251461 -0.01226924\\n 0.02913582]'},
# {'Paris is a capital of France': '[-0.00085885 0.04388924 -0.00083831 ... 0.02374511 -0.00984441\\n 0.02858762]'},
# {'Niklas Heidloff works for IBM et il aime le développement de logiciels': '[-0.08408933 -0.0428754 -0.03804896 ... -0.03178102 0.00735097\\n 0.00501928]'}]
# "}]}
Environment
The example uses a predefined Python environment plus custom dependencies which are defined in Conda yaml files.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
config_yml =\
"""
name: python311
channels:
- conda-forge
- nodefaults
dependencies:
- pip
- pip:
- sentence-transformers
prefix: /opt/anaconda3/envs/python311
"""
with open("config.yaml", "w", encoding="utf-8") as f:
f.write(config_yml)
base_sw_spec_id = client.software_specifications.get_id_by_name("runtime-24.1-py3.11")
meta_prop_pkg_extn = {
client.package_extensions.ConfigurationMetaNames.NAME: "sentence-transformers env",
client.package_extensions.ConfigurationMetaNames.DESCRIPTION: "Environment with sentence-transformers",
client.package_extensions.ConfigurationMetaNames.TYPE: "conda_yml"
}
pkg_extn_details = client.package_extensions.store(meta_props=meta_prop_pkg_extn, file_path="config.yaml")
pkg_extn_id = client.package_extensions.get_id(pkg_extn_details)
pkg_extn_url = client.package_extensions.get_href(pkg_extn_details)
meta_prop_sw_spec = {
client.software_specifications.ConfigurationMetaNames.NAME: "sentence-transformers software_spec",
client.software_specifications.ConfigurationMetaNames.DESCRIPTION: "Software specification to use sentence-transformers",
client.software_specifications.ConfigurationMetaNames.BASE_SOFTWARE_SPECIFICATION: {"guid": base_sw_spec_id}
}
sw_spec_details = client.software_specifications.store(meta_props=meta_prop_sw_spec)
sw_spec_id = client.software_specifications.get_id(sw_spec_details)
client.software_specifications.add_package_extension(sw_spec_id, pkg_extn_id)
sw_spec_id = client.software_specifications.get_id_by_name("sentence-transformers software_spec")
client.software_specifications.get_details(sw_spec_id)
client.software_specifications.list()
Next choose a hardware configuration.
1
2
asset_uid = client.hardware_specifications.get_id_by_name("L")
print("hw spec",asset_uid)
Deployment
Before the deployment the function needs to be stored.
1
2
3
4
5
6
7
meta_props = {
client.repository.FunctionMetaNames.NAME: "custom embedding bilingual-embedding-large",
client.repository.FunctionMetaNames.SOFTWARE_SPEC_ID: sw_spec_id
}
function_details = client.repository.store_function(meta_props=meta_props, function=deployable_function)
function_id = client.repository.get_function_id(function_details)
client.repository.list_functions()
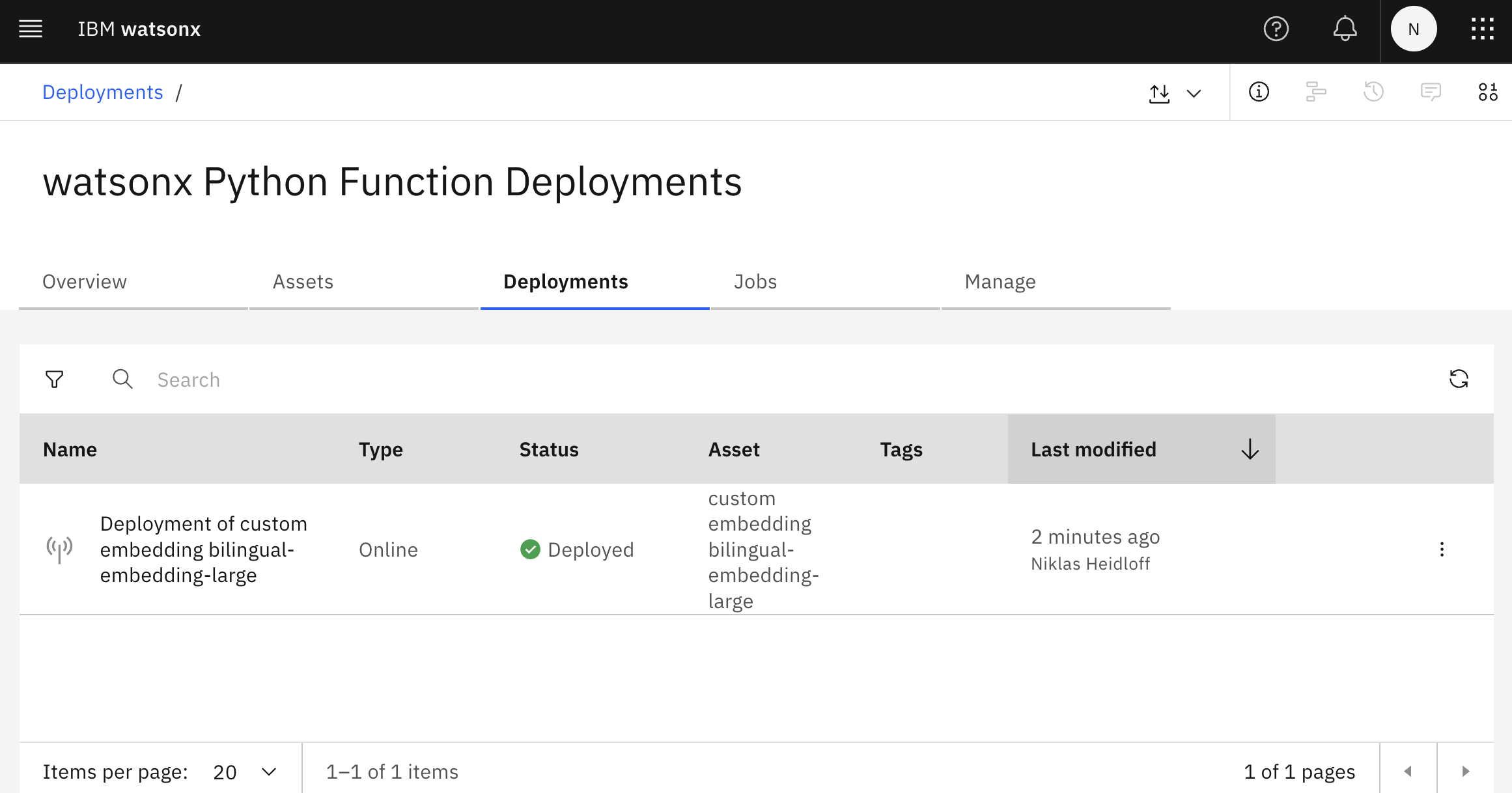
Now the actual deployment can be invoked. The screenshot at the top shows how the function deployment is displayed in the user interface.
1
2
3
4
5
6
7
8
metadata = {
client.deployments.ConfigurationMetaNames.NAME: "Deployment of custom embedding bilingual-embedding-large",
client.deployments.ConfigurationMetaNames.ONLINE: {},
client.deployments.ConfigurationMetaNames.HARDWARE_SPEC: { "id": asset_uid }
}
function_deployment = client.deployments.create(function_id, meta_props=metadata)
deployment_id = client.deployments.get_id(function_deployment)
print(deployment_id)
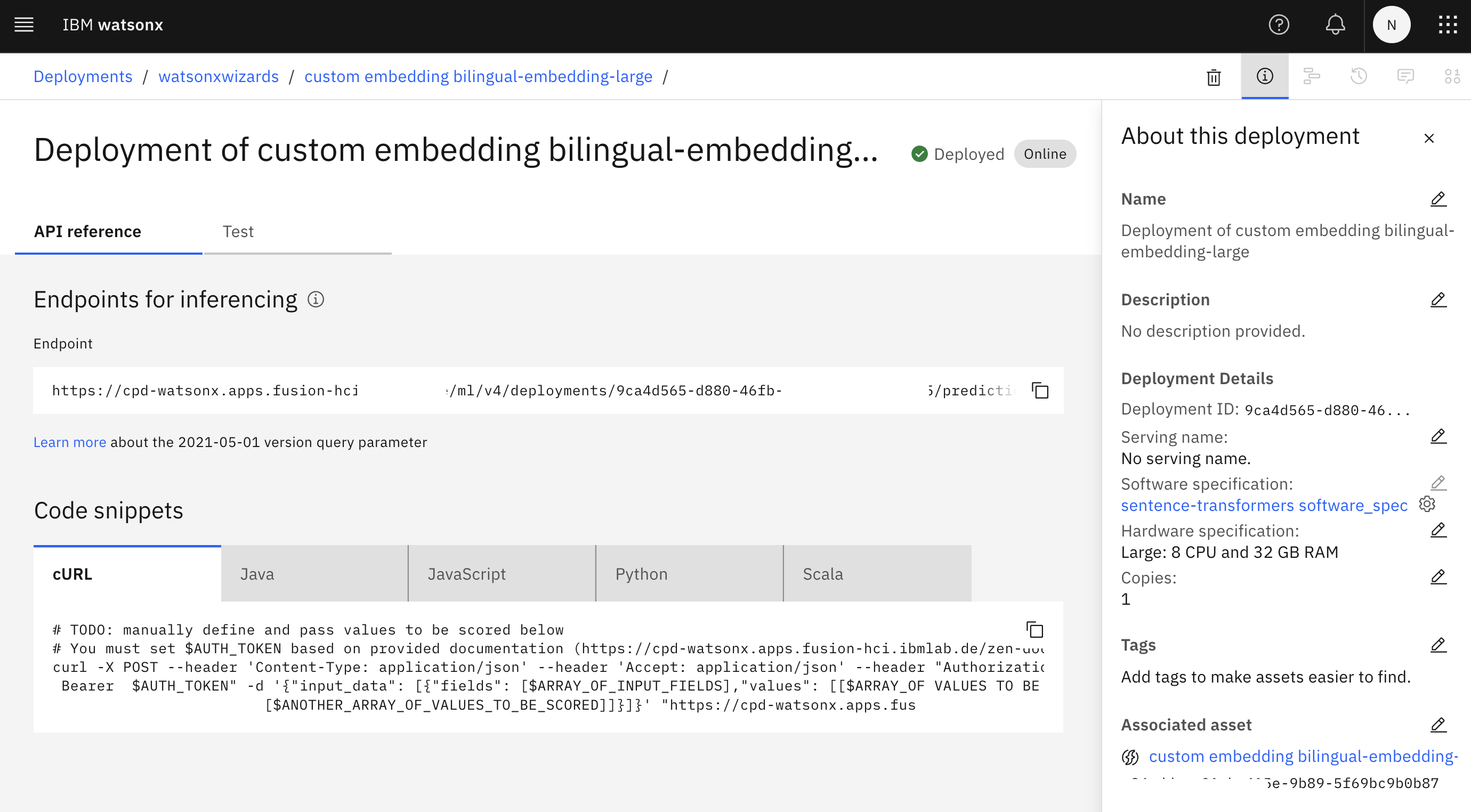
Endpoint
After the successful deployment an endpoint will be provided.
The snippet can be run in a notebook.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
sentences = [
"Paris est une capitale de la France",
"Paris is a capital of France",
"Niklas Heidloff works for IBM et il aime le développement de logiciels"
]
scoring_payload = {
"input_data": [{
"values" : sentences
}]
}
predictions = client.deployments.score(deployment_id, scoring_payload)
print(predictions)
# {'predictions': [{
# 'values': "[
# {'Paris est une capitale de la France': '[-0.00971037 0.04192735 0.00290196 ... 0.01251461 -0.01226924\\n 0.02913582]'},
# {'Paris is a capital of France': '[-0.00085885 0.04388924 -0.00083831 ... 0.02374511 -0.00984441\\n 0.02858762]'},
# {'Niklas Heidloff works for IBM et il aime le développement de logiciels': '[-0.08408933 -0.0428754 -0.03804896 ... -0.03178102 0.00735097\\n 0.00501928]'}]
# "}]}
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.