
One of the newer IBM Watson offerings that I really like is Watson Knowledge Studio. It basically allows identifying information in unstructured data. Below is a quick overview of the Knowledge Studio functionality.
Watson Knowledge Studio is not a Bluemix service but an SaaS offering to create models for custom corpora of data that can actually be deployed and used in other Watson services (more about this in another blog). These models are either machine-learning models which work more generically or rule-based models which work well for smaller datasets.
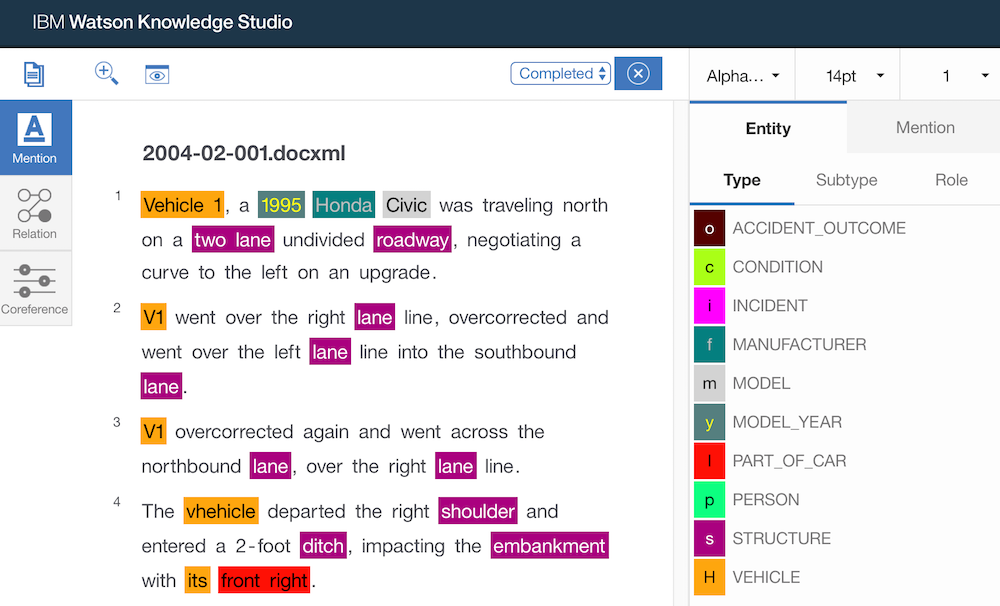
To train a machine-learning based model you need to create an annotator. Essentially you define entities, roles, dictionaries etc. and then mark the words in the training dataset accordingly. Here is a screenshot how to define entities. The scenario uses data from car incidents reports which have entities like vehicle and model.
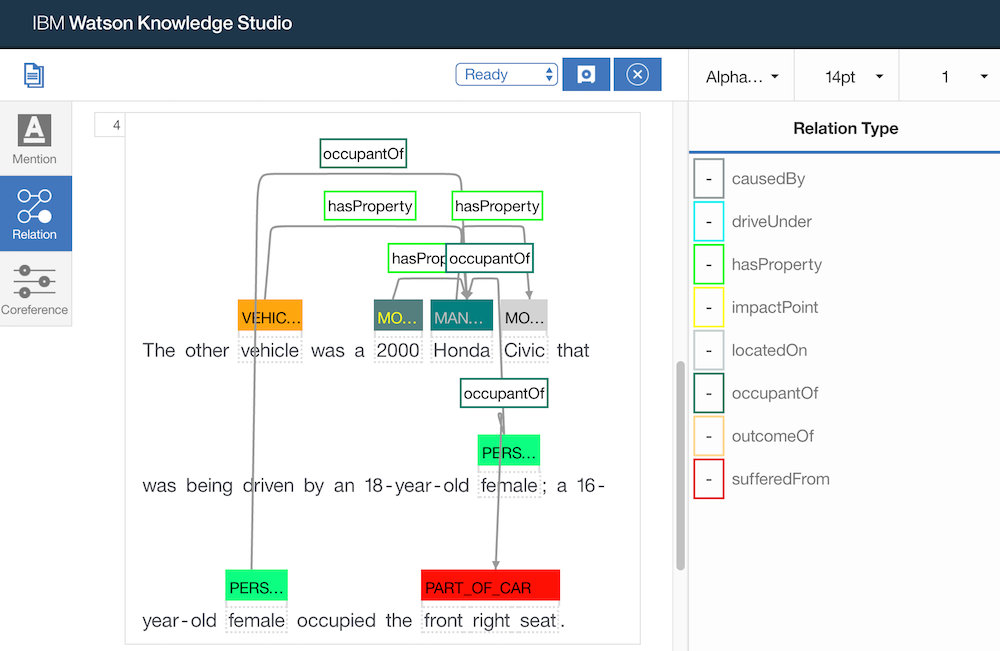
Additionally you can define relations between entities. In this scenario a person is an occupant of a vehicle.
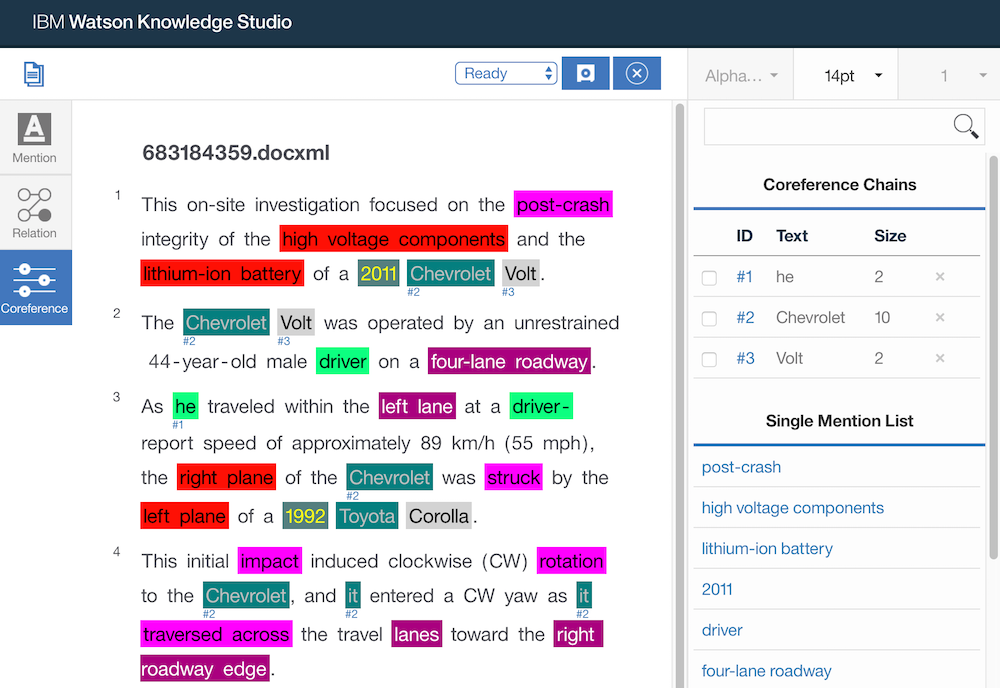
You can even define coreferences, for example that ‘he’ and ‘driver’ refer to the same person.
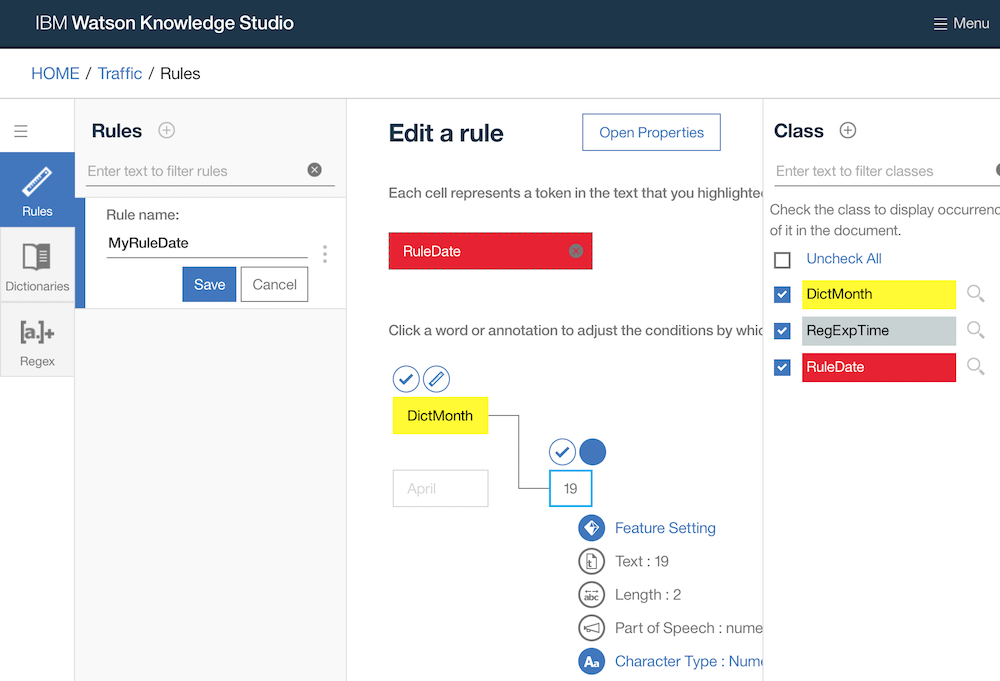
In order to create rule-based models, rules need to be defined (surprise, surprise). This can be done graphically as shown in the screenshot or via regular expressions. In this sample a simple date rule is defined.
To find out check out these resources. Knowledge Studio was introduced on the Watson blog. There are also YouTube playlists Getting Started and Deep Dive. Here is the documentation.