
As most of my readers will know there is a huge hype around ChatGPT, generative AI, large language models (LLMs) also known as foundation models and further related AI technologies. I’m trying to understand these technologies better and have put together below a couple of key concepts I’ve found out so far.
Note: This post is mainly a quick summary of the articles referenced at the bottom, especially of the posts from my colleague Armand Ruiz.
Large Language Models
Many people describe LLMs as a technology revolution similar to how the internet and the iPhone changed the world. Based on my current understanding I think LLMs are a disruptive technology and game changer for many industries at a minimum.
However, as always in the IT industry there is no ‘one size fits all’. Additionally, there are ethical questions, unknown human labor implications and missing legal rules. For most of the existing models you can also find warnings related to misinformation, bias and lack of accountability.
Here is an easy definition of LLMs from Armand Ruiz:
LLMs are computer systems that have been designed to learn […] a text corpus in order to generate new text that mimics the style and content of the original text [..] written by a real person. The AI looks at the last few words typed and tries to predict what word will come next. The predictions are based on probabilities, so the most likely prediction is chosen as the next word.
The reason why LLMs are so powerful is that they can build up an extremely rich internal representation of the language they are trained on. This internal representation captures not just the individual words in the language but also the relationships between those words—relationships.
Scenarios
Large language models can be used for a wide range of scenarios:
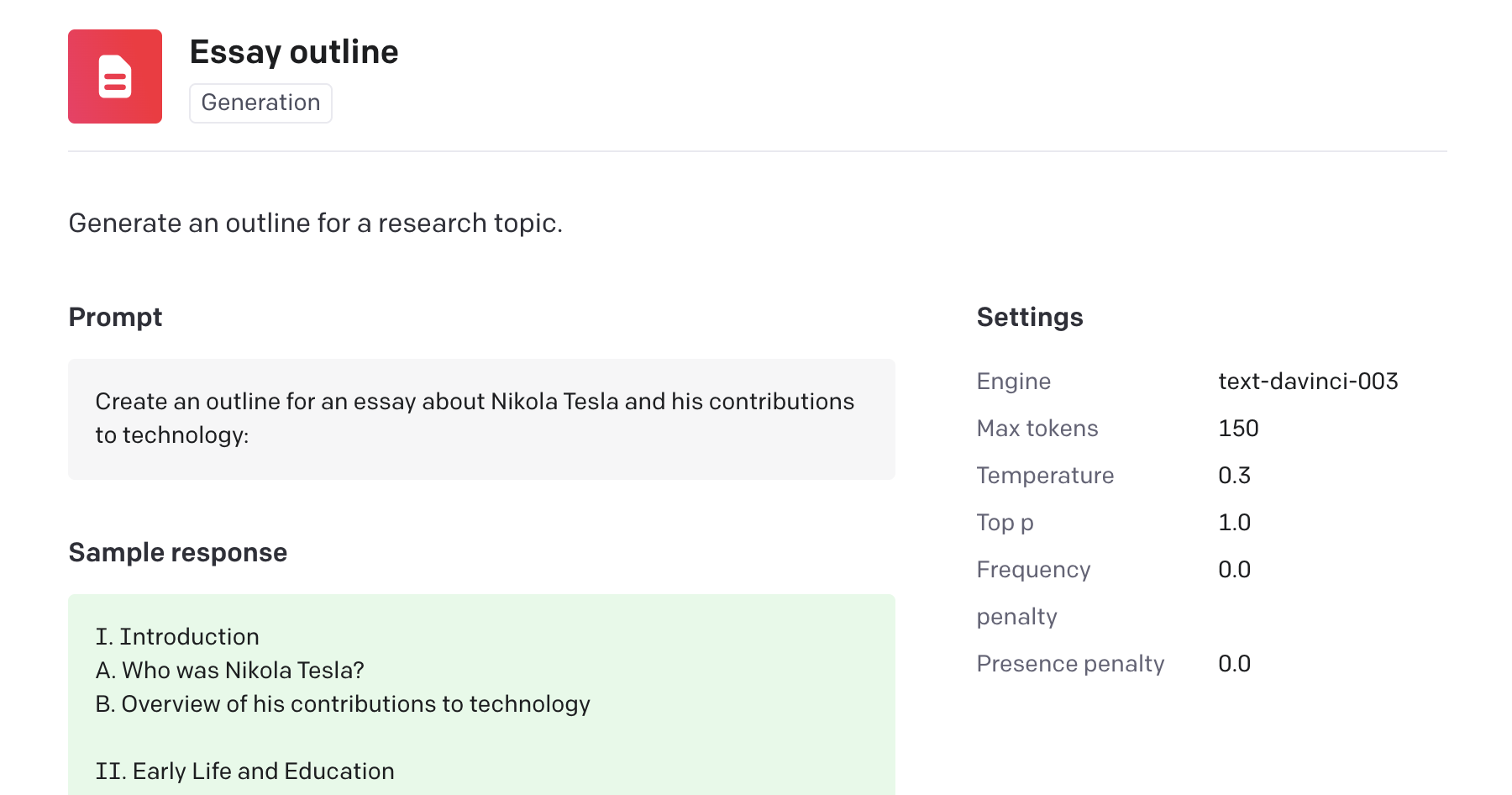
- Q&A, English to other languages, source code generation, code explanation, summarization for a 2nd grader, grammar correction, keyword extraction, product name generator, analogy maker, essay outline generator, interview questions, story creator and much more (see OpenAI examples)
- Text to image, text to video, text to avatar, text to music, text to ideas and more (see blog Welcome to the Text-to-Everything Era)
- And more potential innovative ones like generating new medicines or optimizing Internet searches
Technology
While ChatGPT has primarily created the recent buzz, there are many different large language models. Most of them are commercial, but some are available as open source. There are different models for different scenarios like image and source code generation. For example OpenAI, the company behind ChatGPT, provides GPT-3, GPT-3.5, Codex, Dall E 2, etc.
LLMs have been trained by massive amounts of data, for example in the case of GPT-3.5 with data from the internet until 2021, book libraries and more. The codex model series has been trained with lots of data from GitHub and StackOverflow.
Training and running these large models requires a huge amount of resources and time. From Armand’s blog:
OpenAI worked with a supercomputer with thousands of GPUs to train the LLM and it still took months. The cost of training GPT-3 is not available for public access but it is estimated to be around $4.6 million for a training cycle, with reporters saying it could cost over $10 million. And that’s just for training, one source estimates the cost of running GPT-3 on a single AWS instance at a minimum of $87,000 per year.
From lifearchitect.ai:
Training hardware: Access to a supercomputer with ~10,000 GPUs and ~285,000 CPU cores […] Staffing: […] they have a team of 120 people. […] Time (data collection): EleutherAI took a solid 12-18 months to agree on, collect, clean, and prepare data […] Time (training): Expect a model to take 9-12 months of training, and that’s if everything goes perfectly.
Prompt Engineering
As stated above, large language models can be used for multiple scenarios. To receive the best possible results, you need to use the best possible instructions to define what you want. This technique is called Prompt Engineering. Read the blog Introduction to Prompt Engineering to learn more.
I compare prompt engineering with efficient Google searches. For example to get the best results, I usually think about the most promising and precise keywords or I use ‘site:target-domain.com’ to filter the results.
Let’s look at a simple example to extract the airport codes from this text:
1
2
3
4
5
Text: "I want to fly from Los Angeles to Miami."
Airport codes: LAX, MIA
Text: "I want to fly from Orlando to Boston"
Airport codes:
1
2
Sample response
MCO, BOS
There are other scenarios where you need to define multiple examples first to help the AI to understand patterns. These techniques are called One-Shot Learning and Few-Shot Learning.
Customization
In addition to Prompt Engineering some LLMs can also be customized for custom domains. In this case the pretrained models are used and extended with labeled training data.
Customization is key if for your own domains and for data that is not publicly available. From Armand’s blog:
The power of LLMs comes when companies take existing LLMs already trained and tune them to create models for specific domains and tasks. Those companies will have a lot of value by using those models internally or offering them to their customers. They will combine LLMs massive training with their Domain-Specific datasets and use a new generation of tools to fine-tune those models. Many of those tools will be No-code AI tools and will allow users to modify the prompts.
For example OpenAI provides fine tuning of models.
References
If you want to learn about large language models, I recommend checking out the following resources:
- Introduction to Large Language Models
- GPT-3.5 + ChatGPT: An illustrated overview
- OpenAPI documentation
- Large Language Models: A New Moore’s Law?
- OpenAI CEO Sam Altman - AI for the Next Era
Some of the popular models are not available as open source, but many of them provide trial plans which might work for you.
BLOOM describes itself as the world’s largest open multilingual language model.
The image generator Stable Diffusion seems to have a free playground that doesn’t require registration and it is available as open source.