
Serving AI models is resource intensive. There are various model inference platforms that help operating these models as efficiently as possible. This post summarizes two platforms for classic ML and foundation models.
Kubeflow KServe
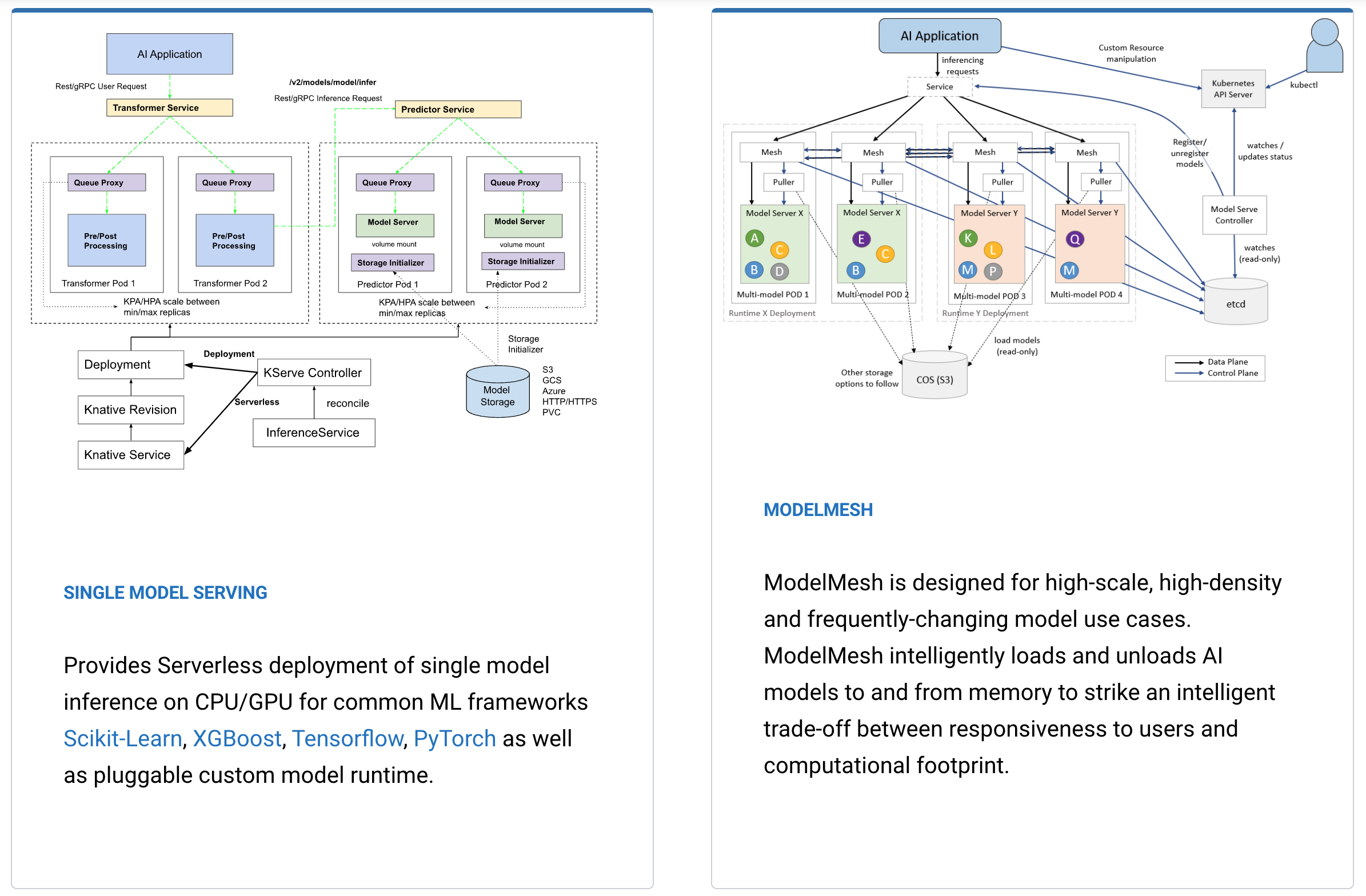
KServe enables inferencing on Kubernetes and provides performant, high abstraction interfaces for common machine learning frameworks like TensorFlow and PyTorch to solve production model serving use cases. Read my earlier post how to run Watson NLP on KServe ModelMesh.
There are two options how to run KServe. The easiest way is to use ‘Single Model Serving’ where each model is associated with one dedicated runtime container. For frequently-changing model use cases and to achieve better scalability, containers can also handle multiple models via ‘ModelMesh’.
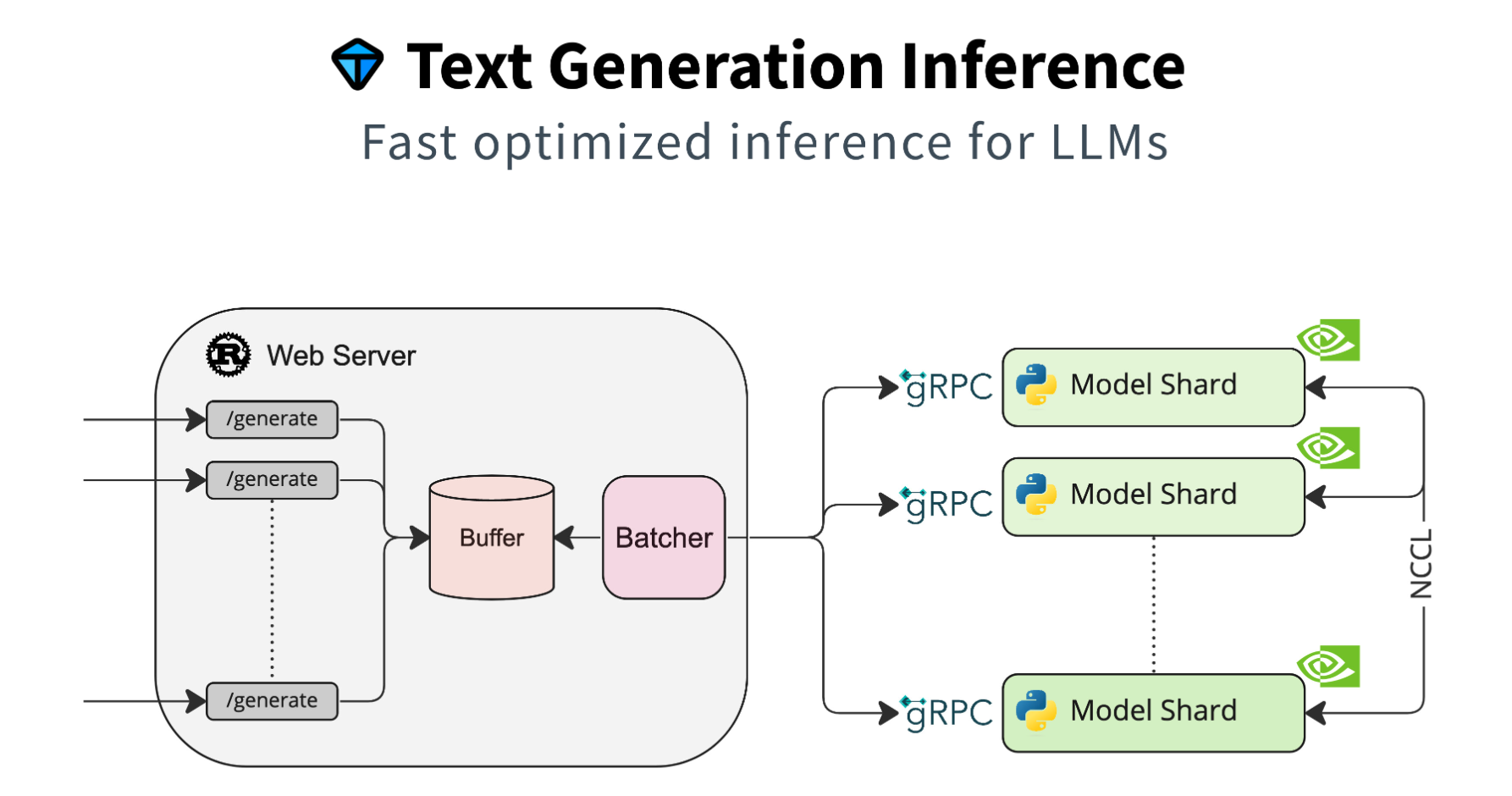
Text Generation Inference
While KServe is a great platform to serve classic machine learning models, it has not been designed specifically for Large Language Models and other Foundation Models. These models have extended requirements that TGI addresses. For example, while CPUs can easily be virtualized, this hasn’t really been possible so far for GPUs. Additionally, batching and caching is performed heavily to optimize access to the GPUs. Here is a list of some of the features from the TGI documentation:
- Simple launcher to serve most popular LLMs
- Production ready
- Tensor Parallelism for faster inference on multiple GPUs
- Token streaming using Server-Sent Events
- Continuous batching of incoming requests for increased total throughput
- Quantization with bitsandbytes
IBM also uses TGI from Hugging Face and has extended features like gRPC.
The article Fine-tuning and Serving an open source foundation model with Red Hat OpenShift AI describes how TGI (TGIS) is integrated in KServe in Red Hat OpenShift AI.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.