
SmolDocling is an ultra-compact, open-source Vision Language Model for document conversion including OCR. This post summarizes the key features and demonstrates how to get started.
SmolDocling is part of the popular open-source project Docling which is hosted in the Linux Foudation AI & Data Foundation. Docling and the SmolDocling model convert complex documents into structured data. Read my post Open-Source Document Parser including OCR for more.
SmolDocling has been developed by IBM Research in collaboration with HuggingFace. Here is how the IBM researcher Peter W. J. Staar describes SmolDocling:
At just 256M parameters, SmolDocling introduces a powerful end-to-end solution for converting complex documents into a universal markup format called DocTags—handling OCR, layout segmentation, and table/chart understanding in one shot. What makes this truly special? It captures not just content, but also structural information and precise spatial locations of every element on the page.
Features
SmolDocling provides amazing functionality, for example:
- 🎯 Ultra-compact size (256M parameters) with performance matching much larger models
- 🏷️ DocTags are a universal markup format preserving content with location
- 🔍 OCR (Optical Character Recognition) to extract text from images
- 🔲 OCR with bounding boxes
- 📊 Comprehensive handling of tables, code, equations, and charts
- 📜 Works across diverse document types
- 💨 Fast inference using vLLM
Note that SmolDocling is currently in preview, but the team is iterating quickly. Given the state of the project and the size of the model OCR might not be as reliable as leading classic OCR tools. While Large Language Models are evolving fast, there might be some issues with features like the detections of locations.
DocTags
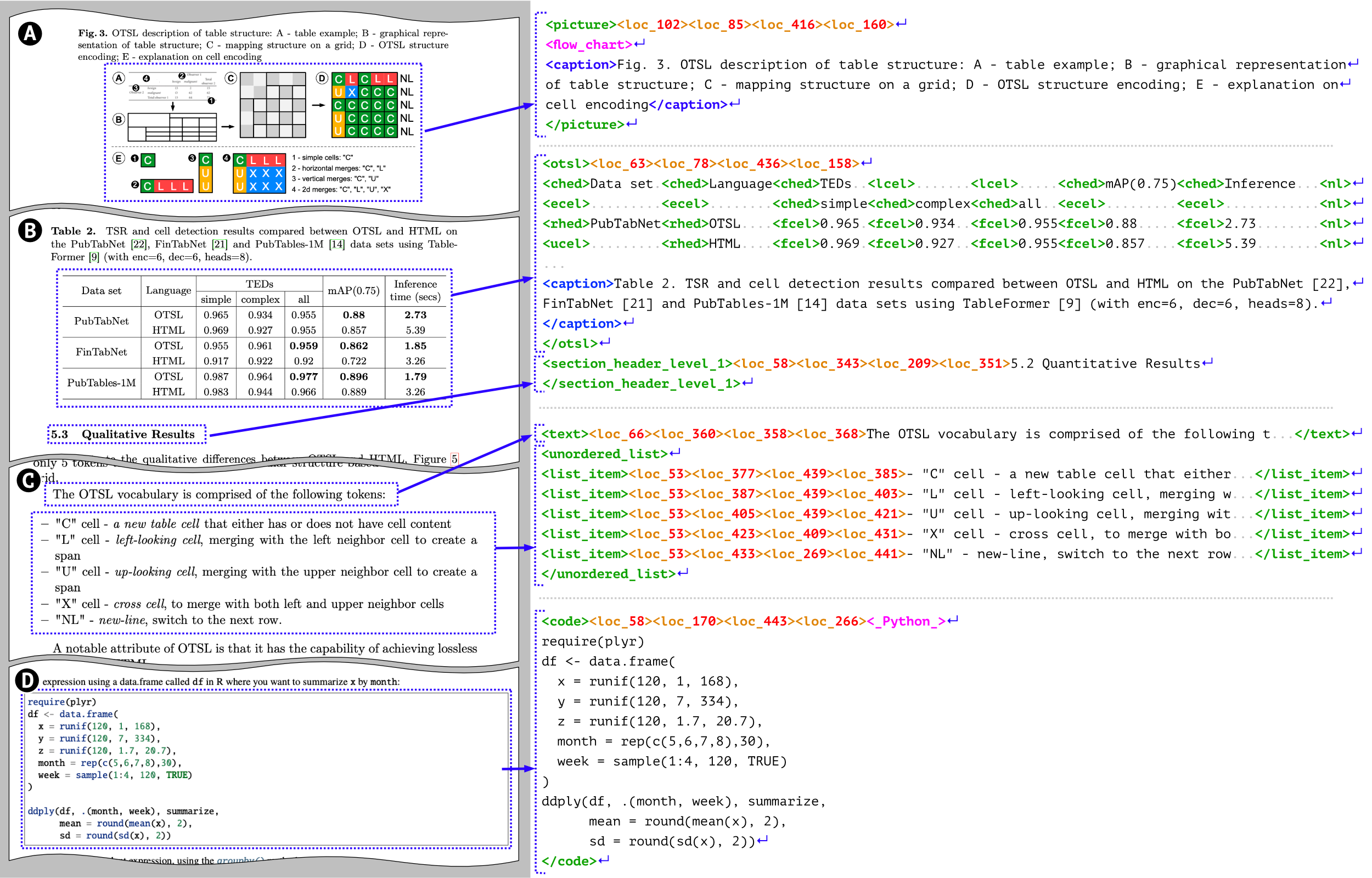
The output of the model are DocTags.
DocTags create a clear and structured system of tags and rules that separate text from the document’s structure. This makes things easier for Image-to-Sequence models by reducing confusion. On the other hand, converting directly to formats like HTML or Markdown can be messy—it often loses details, doesn’t clearly show the document’s layout […]. DocTags are integrated with Docling, which allows export to HTML, Markdown, and JSON. These exports can be offloaded to the CPU, reducing token generation overhead and improving efficiency.
Setup
Here is how to run SmolDocling on an Apple M3 GPU via Local inference on Apple Silicon with MLX:
1
2
3
4
5
6
7
8
9
10
brew install cmake
brew install gfortran openblas pkg-config
brew info openblas | grep PKG_CONFIG_PATH
brew install llvm libomp
export CC=/opt/homebrew/opt/llvm/bin/clang
export CXX=/opt/homebrew/opt/llvm/bin/clang++
python3.12 -m venv venv
source venv/bin/activate
pip install -U mlx-vlm pillow docling-core
Example
The sample code is from the model card.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from io import BytesIO
from pathlib import Path
from urllib.parse import urlparse
import requests
from PIL import Image
from docling_core.types.doc import ImageRefMode
from docling_core.types.doc.document import DocTagsDocument, DoclingDocument
from mlx_vlm import load, generate
from mlx_vlm.prompt_utils import apply_chat_template
from mlx_vlm.utils import load_config, stream_generate
model_path = "ds4sd/SmolDocling-256M-preview-mlx-bf16"
model, processor = load(model_path)
config = load_config(model_path)
image = "https://ibm.biz/docling-page-with-table"
if urlparse(image).scheme != "":
response = requests.get(image, stream=True, timeout=10)
response.raise_for_status()
pil_image = Image.open(BytesIO(response.content))
else:
pil_image = Image.open(image)
prompt = "Convert this page to docling."
formatted_prompt = apply_chat_template(processor, config, prompt, num_images=1)
output = ""
print("DocTags: \n\n")
for token in stream_generate(
model, processor, formatted_prompt, [image], max_tokens=4096, verbose=False):
output += token.text
print(token.text, end="")
if "</doctag>" in token.text:
break
print("\n\n")
print("Markdown: \n\n")
doctags_doc = DocTagsDocument.from_doctags_and_image_pairs([output], [pil_image])
doc = DoclingDocument(name="SampleDocument")
doc.load_from_doctags(doctags_doc)
print(doc.export_to_markdown())
Output for the image:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
python test.py
...
model.safetensors.index.json: 100%|███████| 38.1k/38.1k [00:00<00:00, 2.34MB/s]
tokenizer.json: 100%|█████████████████████| 3.55M/3.55M [00:00<00:00, 5.37MB/s]
model.safetensors: 100%|████████████████████| 513M/513M [00:10<00:00, 48.6MB/s]
Fetching 13 files: 100%|████████████████████| 13/13 [00:00<00:00, 18660.49it/s]
DocTags:
<doctag>
<page_header><loc_127><loc_27><loc_419><loc_34>Optimized Table ...</page_header>
<page_header><loc_451><loc_27><loc_457><loc_34>9</page_header>
<text><loc_57><loc_46><loc_457><loc_71>order to compute ...</text>
<section_header_level_1><loc_57><loc_84><loc_271><loc_92>5.1 Hyper Parameter Optimization</section_header_level_1>
...
</doctag>
Markdown:
order to compute ...
.. 5.1 Hyper Parameter Optimization
...
Next Steps
Try SmolDocling in the HuggingFace Space and check out the following resources.