
In the most recent versions Elasticsearch provides semantic searches. This post summarizes how this new functionality can be utilized.
Semantic searches allow finding relevant information even if classic keyword matches (BM25) are not present. The new functionality is described in the Elasticsearch blog and documentation:
- Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model
- ELSER – Elastic Learned Sparse EncodeR
- Tutorial: semantic search with ELSER
- ELSER text expansion
IBM provides the new Elasticsearch capabilities in the new offering Watsonx Discovery.
Overview
With Retrieval Augmented Generation (RAG) search results are passed as context via prompts to the Large Language Models (LLMs). This supports LLMs to generate responses based on data the models haven’t been trained on, e.g., data that is not publicly available. It also reduces hallucination.
With vector-based searches documents can be found even if keywords from the questions don’t appear in the documents. Instead Embeddings are used to find the k-nearest neighbors in neural networks. While this is a typical approach for semantic searches, it is not the only way to implement this.
Dense
Elasticsearch supports Dense vectors and k-nearest neighbor searches (kNN). In this case embeddings are stored in the indexes.
As stated in the blog and documentation there are some disadvantages though.
Training the model on your own data is essential to ensure better search results than using only BM25. However, the model training process requires a team of data scientists and ML experts, making it expensive and time-consuming.
ELSER
Additionally Elasticsearch supports another slightly different approach. When adding documents to search indexes, lists of tokens with rankings are generated which represent the content of documents. At runtime this list of tokens is leveraged to detect relevant documents. This new semantic search functionality is called ELSER.
Elastic Learned Sparse EncodeR - or ELSER - is a retrieval model trained by Elastic that enables you to perform semantic search to retrieve more relevant search results. This search type provides you search results based on contextual meaning and user intent, rather than exact keyword matches. ELSER is an out-of-domain model which means it does not require fine-tuning on your own data, making it adaptable for various use cases out of the box. Effectively the ELSER model is replacing the terms in the original query with other terms that have been learnt to exist in the documents that best match the original search terms in a training dataset, and weights to control how important each is.
As stated in the blog in most cases ELSER searches outperform BM25.

Notes: ELSER is only available in English. Response times can increase compared to classic BM25 searches.
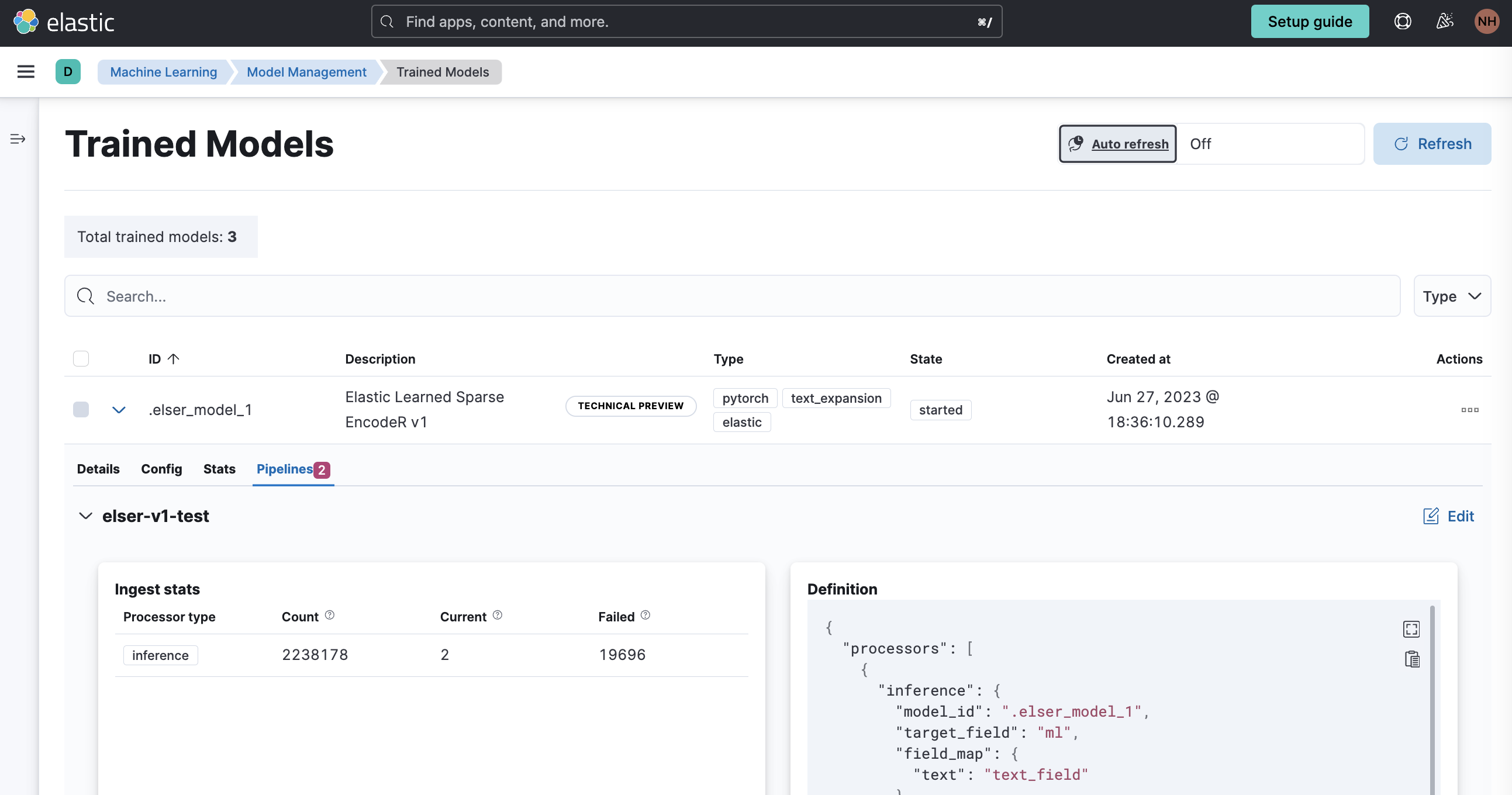
Indexing
To leverage ELSER the model needs to be deployed and extra information needs to be created in the indexes via pipelines. Check out the documentation for details.
Longer documents have to be split in multiple parts because of technical restrictions. My previous post Tokenizing Text for Vector Searches with Java describes how documents can be split in less than 512 tokens with overlaps. As tokenizer MiniLM L-6 is used:
Following the literature, we were using MiniLM L-6 from the SBERT family for our initial teacher.
Input
The following curl request shows how to invoke queries via the new ‘text_expansion’ field. Filters work as for classic BM25 searches.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
QUESTION="my question"
ELASTIC_SEARCH_FILTER_NAME="myfilter"
ELASTIC_SEARCH_FILTER_VALUE="myfiltervalue"
curl -X GET "${ELASTIC_SEARCH_URL}${ELASTIC_SEARCH_INDEX}/_search?pretty"
-H 'Content-Type: application/json'
-u "${ELASTIC_SEARCH_USER}:${ELASTIC_SEARCH_PASSWORD}"
-d'
{
"size": 1,
"query":
{
"bool":
{
"must":
{
"text_expansion":
{
"ml.tokens":
{
"model_id":".elser_model_1",
"model_text":"'$QUESTION'"
}
}
},
"filter":
[
{
"term":
{
"'$ELASTIC_SEARCH_FILTER_NAME'": "'$ELASTIC_SEARCH_FILTER_VALUE'"
}
}
]
}
}
}
'
Output
The response to queries includes the standard information plus the list of tokens with probabilities that have been created when indexing documents.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
{
"took" : 139,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 8.314766,
"hits" : [
{
"_index" : "xxx",
"_id" : "xxx",
"_score" : 8.314766,
"_source" : {
"myfilter" : "myfiltervalue",
"title" : "xxx",
"url" : https://xxx,
"text" : "xxx ...",
"ml" : {
"tokens" : {
"xxx" : 0.9745649,
...
},
"model_id" : ".elser_model_1"
}
}
}
]
}
}
The tokens are created by ELSER. They can be single characters or full words. There are even tokens in these lists that are not in the original text if they are semantically similar. Stop words don’t have to be removed manually. ELSER determines automatically whether or not certain stop words should be added to the list of tokens.
Next Steps
To learn more, check out the Watsonx.ai documentation and the Watsonx.ai landing page.